Sabitlenmiş Tweet

Day 117 diving into ML. Read the OG DQN paper today and exploring RL applications in various industries. Cool ones:
Nuclear fusion: nature.com/articles/s4158…
Ride matching at Lyft: arxiv.org/pdf/2310.13810
Cooling data centers: arxiv.org/pdf/2211.07357
shaan☄️@MehtaDontStop
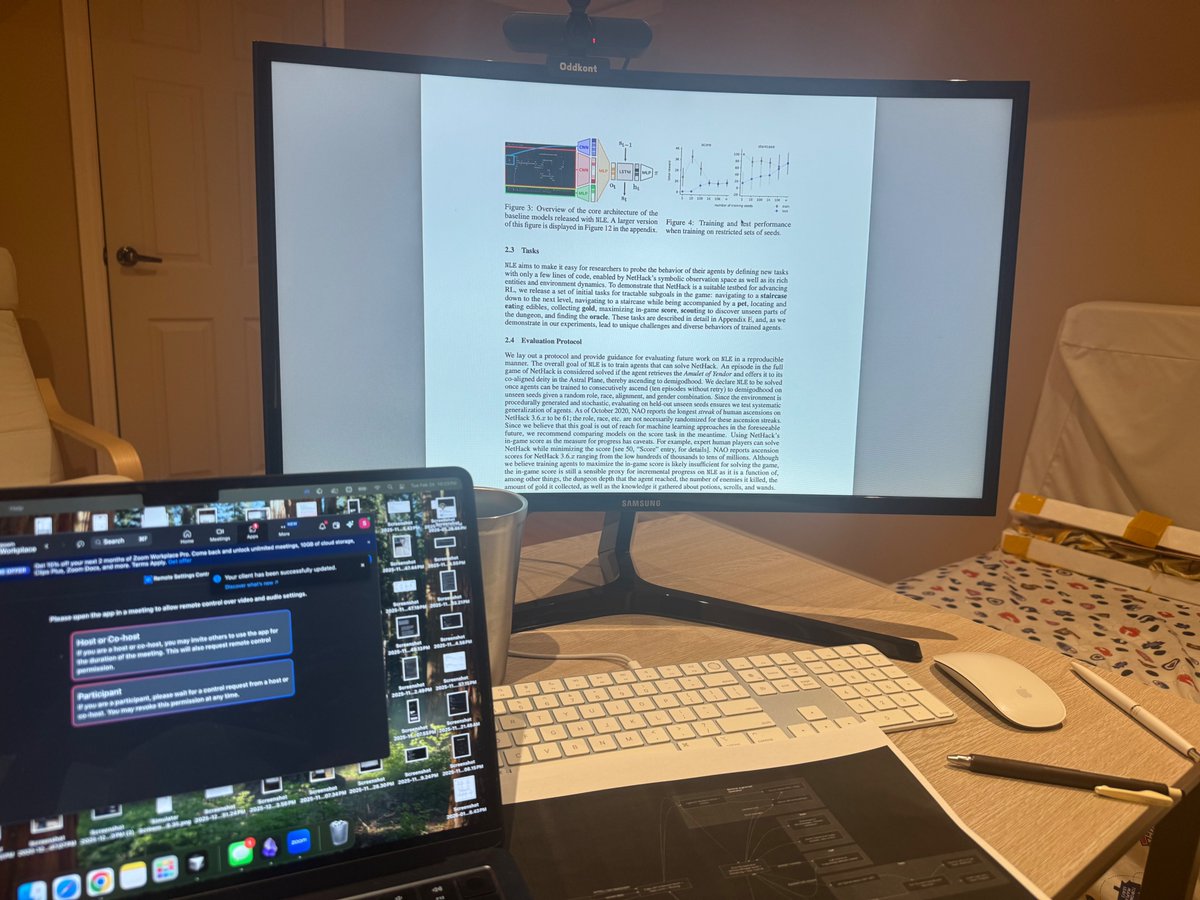
Day 116 diving into ML. Read the NetHack Learning Environment (NLE) paper. Key takeaway: to get generalizing agents, create envs which are procedural + stochastic worlds and build memory + structured encoders into the policy from the start. also, use unseen seeds during eval (seeds reserved for eval) to expand on structured encoders from above, don't flatten the entire obs array, encode each modality into the right format like map data into a CNN, text based data into a language encoder, etc. feeding these into your policy allows it to learn richer representations like a human would, rather then sending a single giant vector
English