@MichaelKatz77 i've been in a couple former SSRs over the last few weeks and i'm confident that every other woman i saw there could easily kill me with her pinkie finger
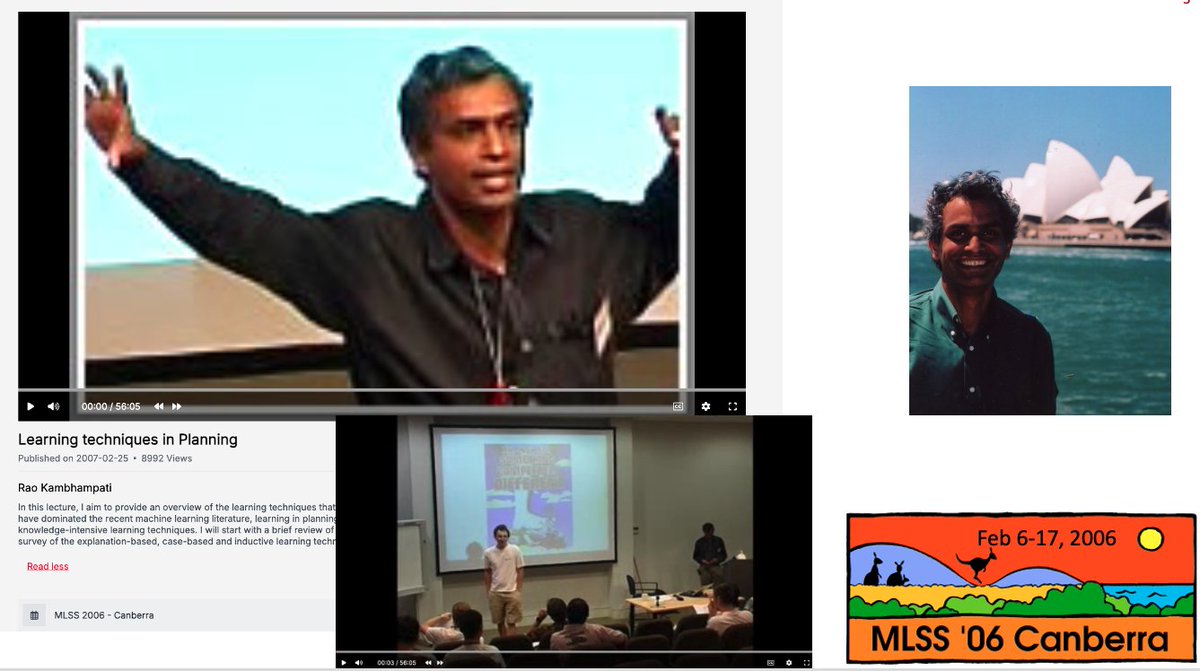
Looking forward to give two lectures today and tomorrow on the Planning and Reasoning abilities of LLMs and LRMs at #ML Summer School Melbourne (mlss-melbourne.com). The last time I spoke at an #ML summer School down under was 20 years back--had more hair 😰 (videolectures.net/videos/mlss06a…)
📣 📣 📣 We have extended the deadline for AAAI workshop on Planning in the Era of LLMs (LM4Plan @ AAAI 2025)! 📣 📣 📣
llmforplanning.github.io
The new deadline is *November 28* AOE!
#AIPlanning#LLM#AgenticAI
@IntuitMachine The graphic in the original post is not wrong, it just does not belong into the post, it is from another paper. Please make sure to update the post to reflect that.
1/n How Agentic AI Can Learn Strategic Thinking Through Self-Improvement and Bi-Level Search
Large Language Models (LLMs) have demonstrated remarkable abilities in understanding and generating human-like text, but their capacity for strategic decision-making in complex environments has remained a challenge. This challenge is particularly evident in multi-agent games, where success hinges on anticipating and outmaneuvering opponents who are constantly adapting their own strategies. The "STRATEGIST" paper tackles this challenge head-on, proposing a novel framework that empowers LLMs to learn sophisticated strategic skills through a process of self-improvement and bi-level tree search.
Traditional approaches to LLM-based decision-making have often fallen short in these complex settings. Directly controlling actions with LLMs, while intuitive, becomes computationally infeasible as the number of possible actions explodes. Similarly, while LLM-based planning methods show promise, they often struggle to learn reusable strategies, instead focusing on planning at the individual action level. Reinforcement learning, while achieving superhuman performance in certain games, typically demands massive datasets and struggles to generalize across different domains.
STRATEGIST differentiates itself by focusing on the acquisition of high-level strategic skills rather than simply searching for the best action in every possible scenario. The framework centers around two key components:
High-Level Strategy Learning: Instead of directly selecting actions, the LLM learns to evaluate game states and generate effective dialogue strategies. This is achieved through:
Value Heuristics: The LLM learns functions that assess the favorability of different game states, allowing it to prioritize advantageous positions.
Dialogue Strategy Guides: Structured prompts guide the LLM in generating persuasive and strategically sound dialogue within the game, taking into account the social dynamics of the environment.
Low-Level Action Selection (MCTS):
To bridge the gap between strategic thinking and concrete actions, STRATEGIST employs Monte Carlo Tree Search (MCTS). This search method explores possible future game states, providing the LLM with more accurate estimates of state values and guiding it towards better immediate actions.
The learning process itself is driven by a continuous loop of self-play, reflection, and improvement. The LLM engages in simulated games, analyzes the outcomes to identify weaknesses in its strategies, and generates ideas for improvement. This reflective process is guided by examining key states where the LLM's predictions diverged from the actual simulation results. The most promising improvement ideas are then implemented, refining the LLM's value heuristics or dialogue guides.
The effectiveness of STRATEGIST is demonstrated through experiments on two distinct games: the strategic card game GOPS and the social deduction game Avalon. In both settings, STRATEGIST consistently outperforms baseline methods, showcasing the power of combining high-level strategy learning with low-level action planning. The results highlight the importance of both components, as removing either significantly diminishes performance.
The paper's findings offer compelling evidence for the potential of STRATEGIST to enhance LLM-based decision-making in complex, multi-agent environments. The framework's ability to learn generalizable strategic skills through self-improvement and search paves the way for LLMs to tackle increasingly sophisticated challenges in domains ranging from game playing to real-world strategic interactions. As LLMs continue to evolve, frameworks like STRATEGIST will be crucial in unlocking their full potential for strategic thinking and decision-making in our increasingly complex world.