Michelle Yin@MichelleYinPhD
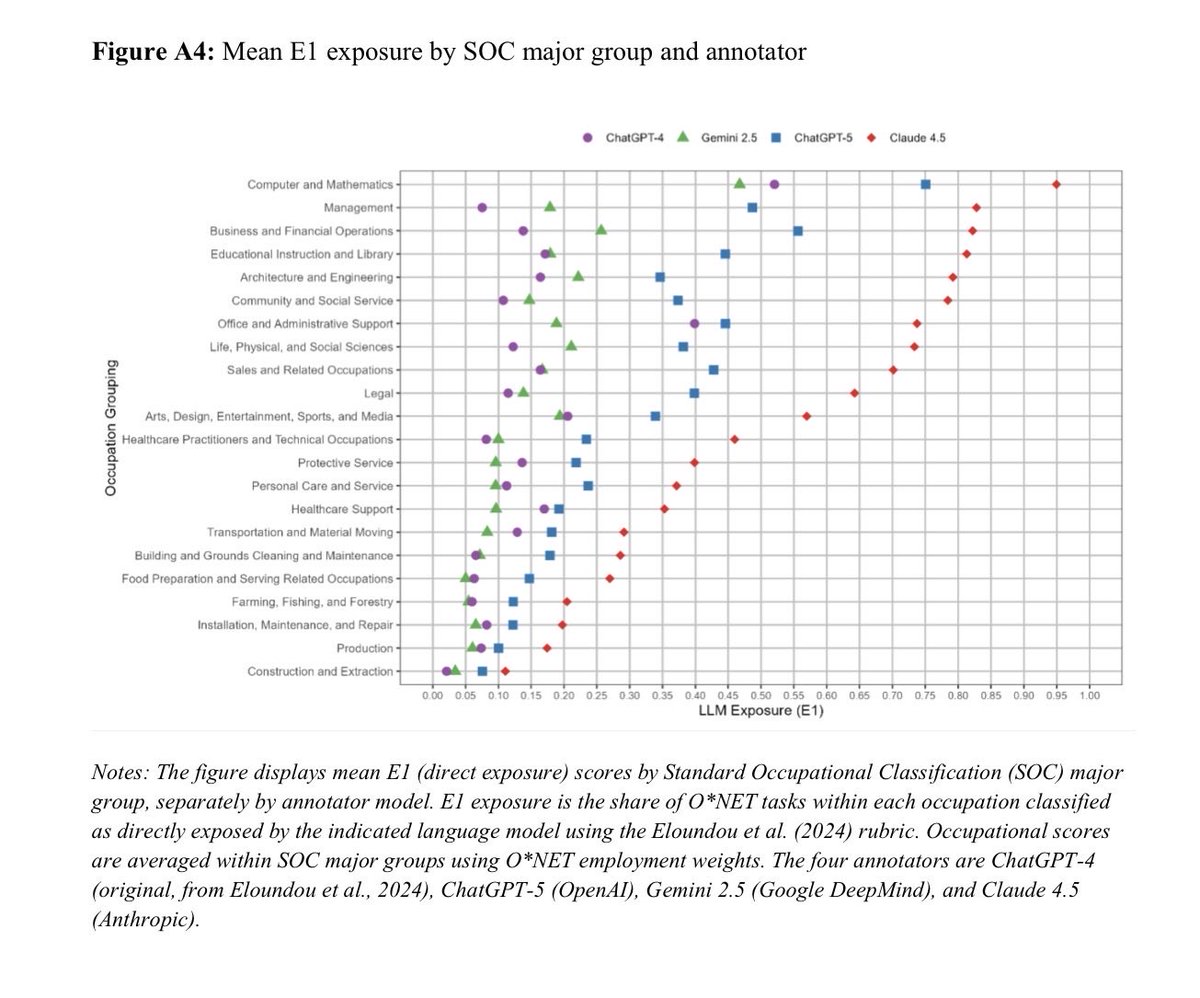
New Wall Street Journal piece on paper number one of a series. Same task list, four AI models. The share of US occupations flagged "high AI exposure" runs from 14% under one model to 51% under another, on identical content. A 19-fold spread. Thread. wsj.com/tech/ai/ai-mod…
English