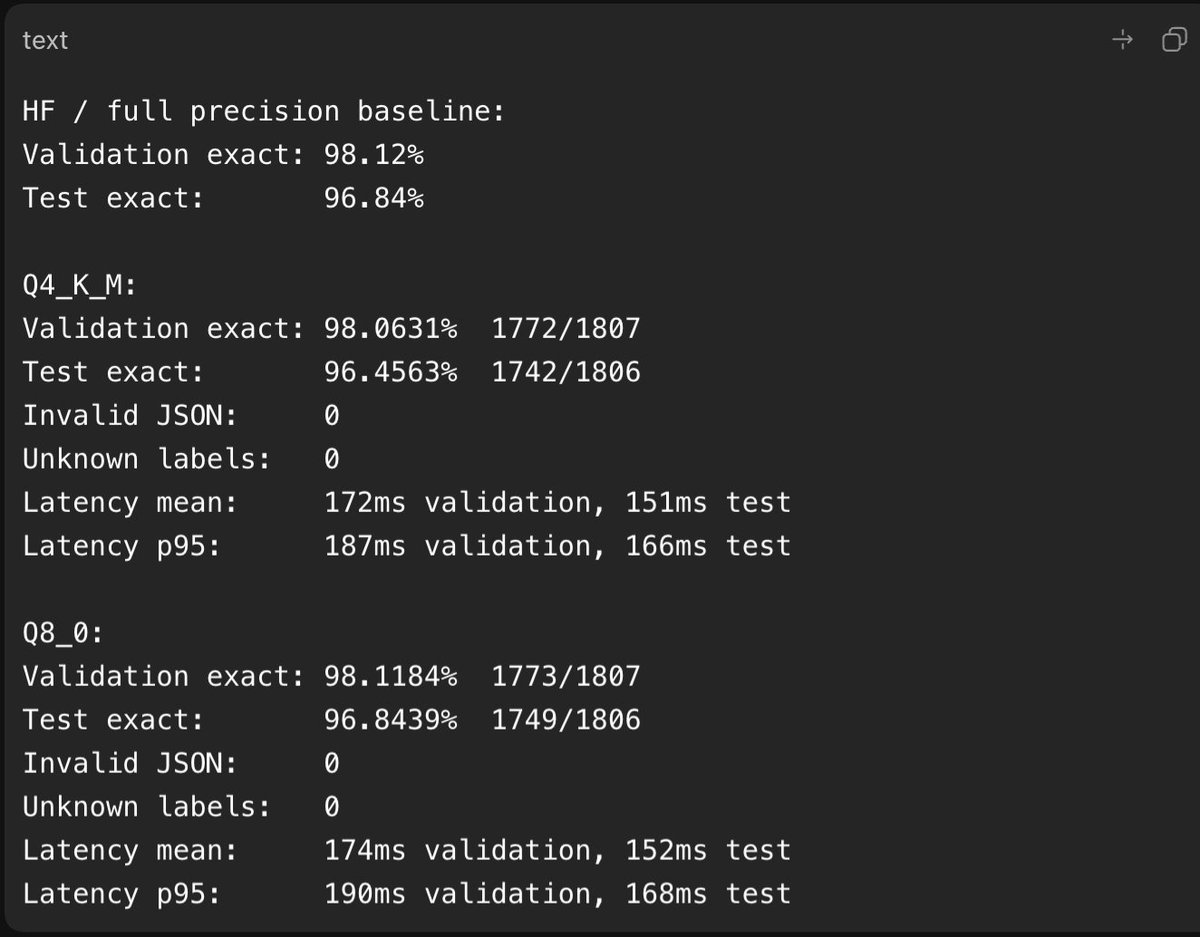
Sabitlenmiş Tweet

Seven years ago I went from 300 pounds to 200 pounds in six months without going to the gym once.
Before: 300 pounds w/ a 48” waist & 19” neck
After 200 pound w/ a 32” waist and a 16.5” neck
With a couple of exceptions, I’ve gone to the gym 5 days a week for the last 7 years.


English