Spot on! One of my biggest takeaways after working on AI scientists for a while.
Andrew Gordon Wilson@andrewgwils
Being good at next word prediction is the opposite of what we want for creativity, for scientific breakthroughs.
English
Minghao Yan
36 posts

@Minghao__Yan
interning @Google PhDing @WisconsinCS | prev @RiceCompSci, @AWS, @ThirdAILab (acq. by @ServiceNow)
Being good at next word prediction is the opposite of what we want for creativity, for scientific breakthroughs.


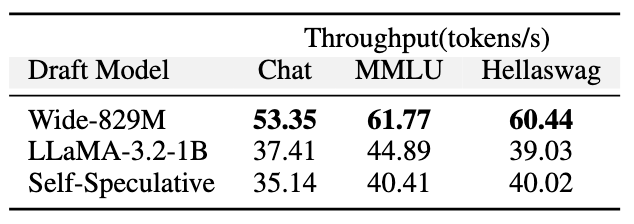
We even deployed PACEvolve on the Modded NanoGPT challenge. Despite the benchmark being heavily optimized by the community, PACEvolve discovered further gains in data loading, network initialization, and tuned better hyperparameters.


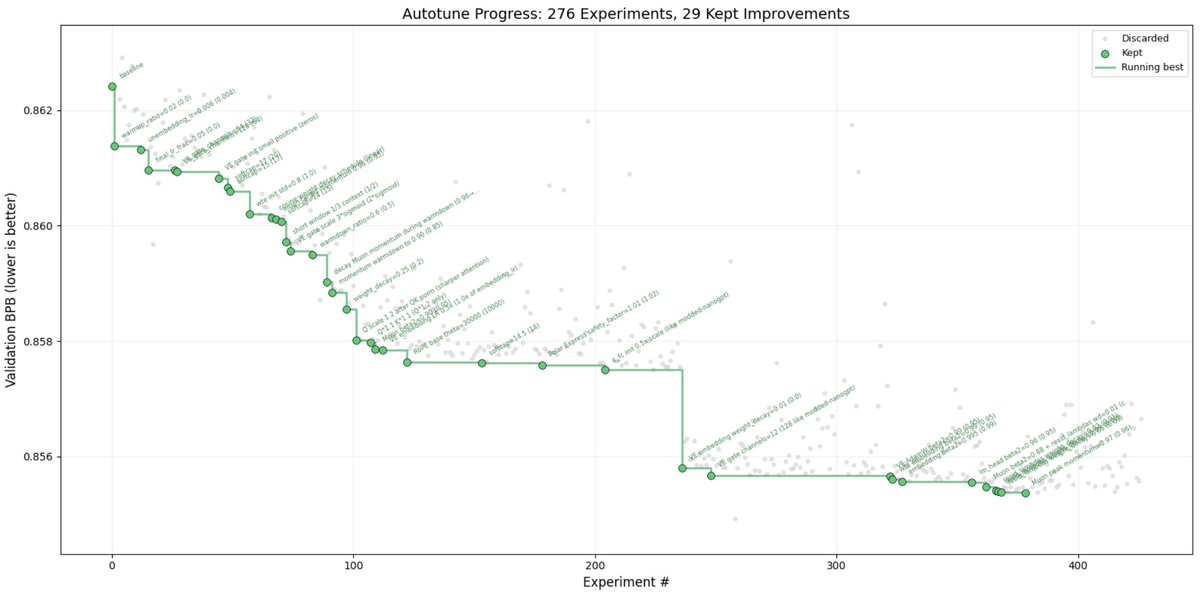
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)

We even deployed PACEvolve on the Modded NanoGPT challenge. Despite the benchmark being heavily optimized by the community, PACEvolve discovered further gains in data loading, network initialization, and tuned better hyperparameters.

We even deployed PACEvolve on the Modded NanoGPT challenge. Despite the benchmark being heavily optimized by the community, PACEvolve discovered further gains in data loading, network initialization, and tuned better hyperparameters.

nanochat now trains GPT-2 capability model in just 2 hours on a single 8XH100 node (down from ~3 hours 1 month ago). Getting a lot closer to ~interactive! A bunch of tuning and features (fp8) went in but the biggest difference was a switch of the dataset from FineWeb-edu to NVIDIA ClimbMix (nice work NVIDIA!). I had tried Olmo, FineWeb, DCLM which all led to regressions, ClimbMix worked really well out of the box (to the point that I am slightly suspicious about about goodharting, though reading the paper it seems ~ok). In other news, after trying a few approaches for how to set things up, I now have AI Agents iterating on nanochat automatically, so I'll just leave this running for a while, go relax a bit and enjoy the feeling of post-agi :). Visualized here as an example: 110 changes made over the last ~12 hours, bringing the validation loss so far from 0.862415 down to 0.858039 for a d12 model, at no cost to wall clock time. The agent works on a feature branch, tries out ideas, merges them when they work and iterates. Amusingly, over the last ~2 weeks I almost feel like I've iterated more on the "meta-setup" where I optimize and tune the agent flows even more than the nanochat repo directly.
🚀 Thrilled to introduce PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution. We show how to push LLM self-evolution beyond short, unstable improvements and into consistent, long-horizon gains. 🧵👇