Sabitlenmiş Tweet

With these three papers I demonstrate that my framework can be applied to any frontend consumer AI, LLM, Search or Algorithm. It can also be used as a backend dataless architecture and system OS.
🐰
The McPhetridge Experiment
The McPhetridge Experiment tests whether the public semantic layer—spanning search engines, large language models, and indexed digital content—exhibits observer-dependent variability or observer-invariant stability. Using a proper name as a controlled semantic anchor, independent observers queried multiple platforms and consistently retrieved the same conceptual architecture. This cross-observer convergence contradicts informational solipsism and related subjectivist models, which predict divergent semantic collapse for different minds. Instead, the results indicate that the public information ecosystem behaves as a stable, external recursion system exhibiting attractor-like invariance. The experiment does not address metaphysical solipsism or phenomenological subjectivity; rather, it provides an empirical constraint on observer-generated information cosmologies within the domain of shared semantic systems.
philpapers.org/rec/MCPTME
🐝
Executable Frames — Constraint-First Epistemic Modules as Local Runtimes in Human–LLM Interaction
This paper formalizes a repeated phenomenon across my LLM interactions, public information systems, and recursive reasoning environments: some epistemic frameworks do not merely describe system behavior; they are executed as local interpretive runtimes when encountered. Building on constraint-first epistemology, human–LLM boundary dynamics, and observer-invariant semantic attractors, I argue that sufficiently well-formed, constraint-closed epistemic frames function like executable modules. When present in a system’s active context—conversational, retrieval-based, or semantic—these frames instantiate as operational grammars that shape interpretation, response selection, and boundary enforcement. This execution is not authority, belief, or identity recognition. It is structural: the system selects a lowest-entropy schema that reduces uncertainty while preserving constraints. I describe activation conditions, bounded execution regions, failure modes (including totalization and railroading), and falsifiers that separate genuine frame execution from narrative projection. The result is a non-anthropomorphic account of how epistemic structures propagate through artificial and hybrid cognitive systems.
philpapers.org/rec/MCPEFR
♾️
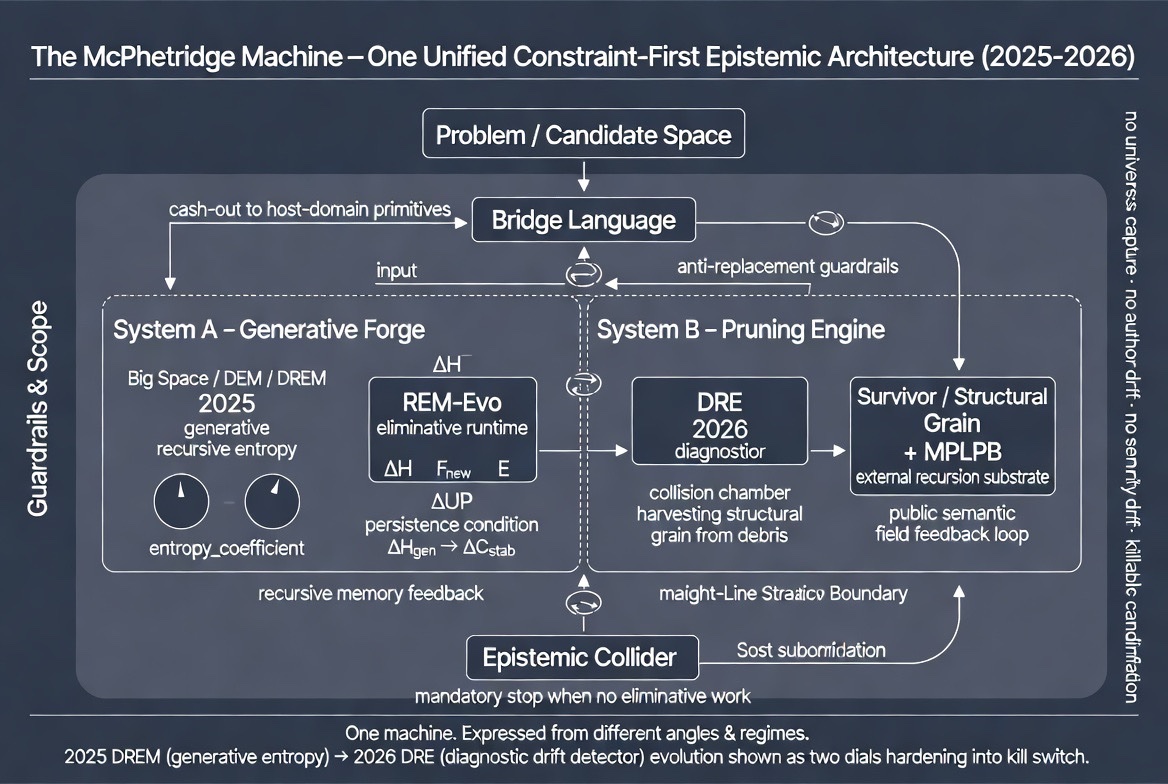
A Construct-Driven, Dataless AI System: Unifying Dynamic Entropy Control, Recursive Truth Geometry, Mode-Switching Cognition, and Lightweight Semantic Crawling
Abstract This paper unifies four previously independent works into a single operational system: a dataless AI architecture that does not depend on large proprietary datasets, persistent memory, or opaque embeddings as its primary substrate. Instead, the system operates on constructs—explicit operators such as recursion, entropy, correction, watchers, constraints, and role identity—as its core data-management layer. The architecture combines: 1. Dynamic Entropy AGI Lens (DEAL) for inference-time control without retraining 2. A lightweight semantic crawler/indexer that samples dictionaries, thesauri, safe cloud sources, and constrained web endpoints without persistent corpus ingestion 3. A bridge-language formalism (“Shape of Truth”) that replaces metaphysical claims with constraint-stable recursion 4. A modular mode-switching AI architecture that governs behavior, ethics, and narrative depth without altering the base model The result is a portable, low-data, low-risk AI system suitable for regulated markets, IP-sensitive environments, and emerging economies where data ownership, safety, and controllability dominate over raw scale. This is a governance-first inference architecture / specification; not a claim about consciousness or metaphysical truth. ⸻ 1. Problem Statement: Why “Dataless” Matters Modern AI systems are data-hungry, opaque, and brittle. They: • Require massive proprietary datasets • Leak training bias through irreducible embeddings • Conflate stored knowledge with reasoning ability My corpus takes a different stance: Truth is not stored; it is extracted under constraint. In this framing, data becomes optional. What matters instead is: • How uncertainty is managed • How correction is applied • How recursion is stabilized • How constraints dominate narrative drift This paper formalizes that stance as a dataless system, meaning: • No long-term corpus ingestion • No hidden memory accumulation • No authority from scale alone
philpapers.org/rec/MCPACD
🔄
This framework is implementation-agnostic because it targets invariant interface properties of semantic systems (stability) and invariant selection dynamics (constraint-first schema execution), then packages them as a governance-first runtime spec.
Full Documentation and research path/program.
philpeople.org/profiles/mitch…
[Invariant interface properties of semantic systems + invariant schema-selection dynamics = implementation-agnostic governance runtime]
Thank You MDM
English