@gramezzana @GiuseppeTat2 @dariodivico Il grullino ha ragione, in questo caso:
(da leonardo.com/it/about/manag…)

Italiano
Moles Harding
22.6K posts

@Moles_Harding
Addicted to chocolate. I make ends meet through simulations, but I’m not a soccer player. I detest white shirts.



Cancer used to be a death sentence. Now many are >90% survivable. Childhood leukemia: 5% → 92% HER2+ breast: 25% → 90% CML: 22% → 87% This is not "luck". Its decades of funding towards time & infra that compounds discovery. Pancreatic cancer today is the breast cancer of 1985, and Glioblastoma ≈ leukemia of 1970. The scientists who will solve them are already in labs NOW. The question is whether we fund them long enough. Funding doesn’t just support science. It literally rewrites outcomes. This plot is proof. Source: SEER + NIH via @Jori_health

Lo abbiamo detto e lo abbiamo fatto, con la nostra Alessandra Todde: il salario minimo a 9 euro l'ora è legge della Regione Sardegna. È un segnale molto importante quello che diamo. Riguarderà appalti e concessioni affidati dall'ente, da aziende sanitarie, società controllate ed enti locali affinché le paghe dei lavoratori non scendano sotto la soglia della dignità, intervenendo in settori in cui spesso quella dignità viene calpestata. È stato anche istituito un Comitato regionale per controllare e monitorare il rispetto degli standard di qualità del lavoro e per contrastare ribassi e sfruttamento sul lavoro con i fatti. Andiamo avanti, dalla parte giusta.






#Leonardo crolla in borsa: i retroscena dello strappo con Cingolani⬇️

If this is real, it could be one of the largest data breaches in China’s history. A hacker group claims it extracted over 10 petabytes of data from a state-run supercomputing facility, widely believed by experts to be the National Supercomputing Center in Tianjin. This center supports thousands of clients, including research institutes, aerospace programs, and defense-linked organizations. What’s reportedly in the data: - Documents marked “secret” in Chinese - Missile and bomb schematics - Aerospace and aviation research - Bioinformatics and fusion simulation data - Files linked to major state entities like AVIC and COMAC Cybersecurity experts who reviewed sample data say it matches what you would expect from such a facility, though the full breach is not independently verified. Even more concerning: - The attacker claims access lasted months without detection - Sample datasets were posted online via Telegram - Full access is reportedly being sold for hundreds of thousands of dollars in crypto At this stage, the scale and origin are still being verified. But if even partially true, it points to a serious vulnerability in infrastructure tied to China’s scientific and defense ecosystem. If a centralized system like this can be penetrated, what does that say about the security of the data it was processing? #China #Cybersecurity #CCP #DataBreach #Geopolitics #Tech cnn.com/2026/04/08/chi…

L'Associazione internazionale dei giudici è stata candidata al Nobel per la Pace. Una scelta che "ci costringe a riconoscere ciò che spesso resta sullo sfondo: che la pace, prima ancora che essere l’assenza di guerra, è la presenza di diritto". Leggi il commento integrale di Monica Mastrandrea su Lamagistratura.it: lamagistratura.it/primo-piano/la…




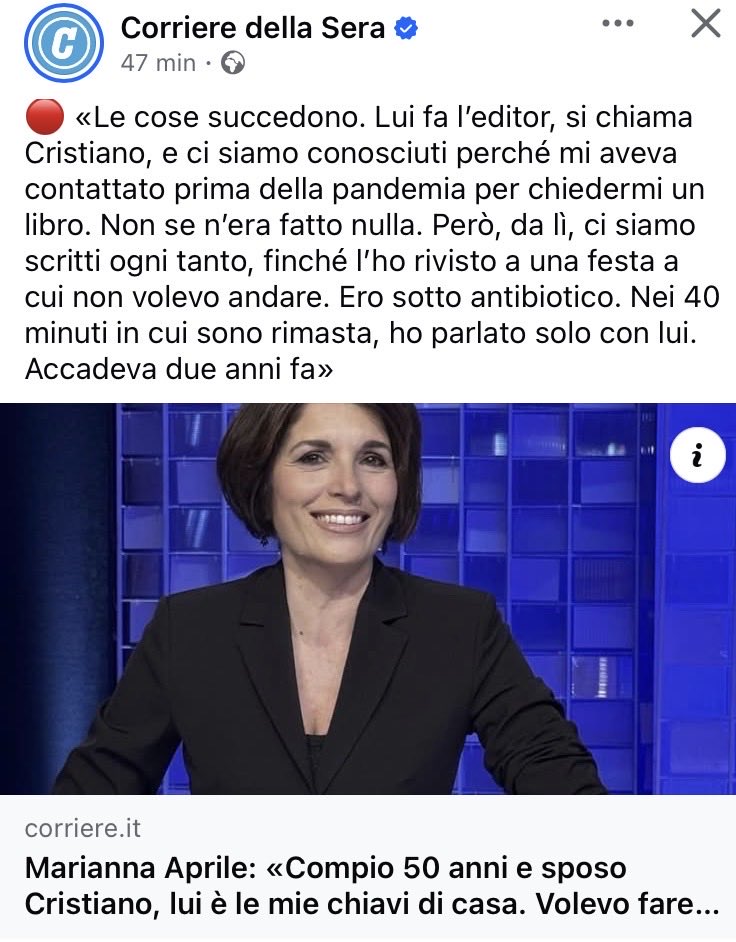
A parte l’intervista-marchetta da parte del quotidiano dello stesso gruppo per cui lavora per promuovere il suo nuovo libro, ma il “volevo fare la toga rossa”, detto come se fosse la cosa più normale del mondo, spiega molto della decadenza di questo Paese sotto tanti fronti



YouTube's copyright system is so broken that the people who steal your content can legally take YOUR video down. Here's what happened. La7, an Italian broadcaster, used footage from Nvidia's DLSS 5 announcement in their programming. Then Content ID scanned the internet and matched La7's upload as the "original." So when Nvidia's own video matched against La7's copy, YouTube's automated system sided with the copier over the creator. The system doesn't verify ownership. It verifies who uploaded first to the Content ID database. That's a completely different thing. Whoever registers the fingerprint first becomes the "rights holder" in YouTube's eyes, regardless of who actually made the content. This is the same architecture that lets music labels claim royalties on songs they don't own, lets random accounts claim game trailers they had nothing to do with, and lets bad actors weaponize takedowns against competitors. The cost of filing a false claim is near zero. The cost of fighting one is days of lost revenue and a channel in limbo. YouTube processes 500+ hours of video every minute. They built Content ID to automate copyright enforcement at that scale. But automation without verification creates a system where the incentives reward abuse. You can claim anything, face no penalty if you're wrong, and the burden of proof falls entirely on the actual creator. When your copyright system can be used to take down the original creator's own content, you haven't built copyright protection. You've built a weapon anyone can point in any direction.
Mentre ci prepariamo alla grigliata di Pasquetta gli algoritmi di rilevamento violazioni #copyright di YouTube ci regalano uno spassoso aneddoto di cui parlare durante il pranzo. 😬 NVIDIA pubblica il trailer del nuovo DLSS 5 con oltre 2 milioni di visualizzazioni in pochi giorni, La7 utilizza quelle stesse immagini all’interno di un servizio del telegiornale e il sistema automatico di YouTube registra la trasmissione di La7 come se fosse il contenuto “originale”, iniziando a distribuire violazioni di copyright a raffica a decine di youtuber oltre che a Nvidia stessa. Decine di creator vengono colpiti e, paradossalmente, anche il video originale di #Nvidia viene rimosso per “violazione del copyright di #La7”. Anche se inizialmente può sembrare a una lettura poco attenta, quanto accaduto non è colpa di La7, ma del sistema Content ID di Youtube, che in base a metriche interne blocca presunte violazioni chiedendo ai creatori di dimostrare se il video era loro oppure no. A questo punto, diventa sempre più importante poter dimostrare che un video è originale, che siamo noi gli autori, che non l'abbiamo copiato da altri. L'#informaticaforense può venire in aiuto tramite le tecniche di #notarizzazione delle prove informatiche, la data certa tramite marche temporali data certa o #blockchain, la documentazione di esistenza di un metodo di produzione di un dato, la catena di custodia che parte da qualcosa di nostro e arriva online dove poi altri potranno eventualmente acquisire una copia ma l'originale rimarrà nostro. Poi sicuramente gli agoritmi di Youtube potranno diventare più "intelligenti", ma anche per loro alla fine non è banale capire chi ha prodotto per primo un dato o meglio, chi ne è il proprietario, che non sempre è la stessa cosa. Qui di seguito il link al thread di X dove i vari youtube colpiti dallo #strike raccontano la loro esperienza. x.com/NikTek/status/…