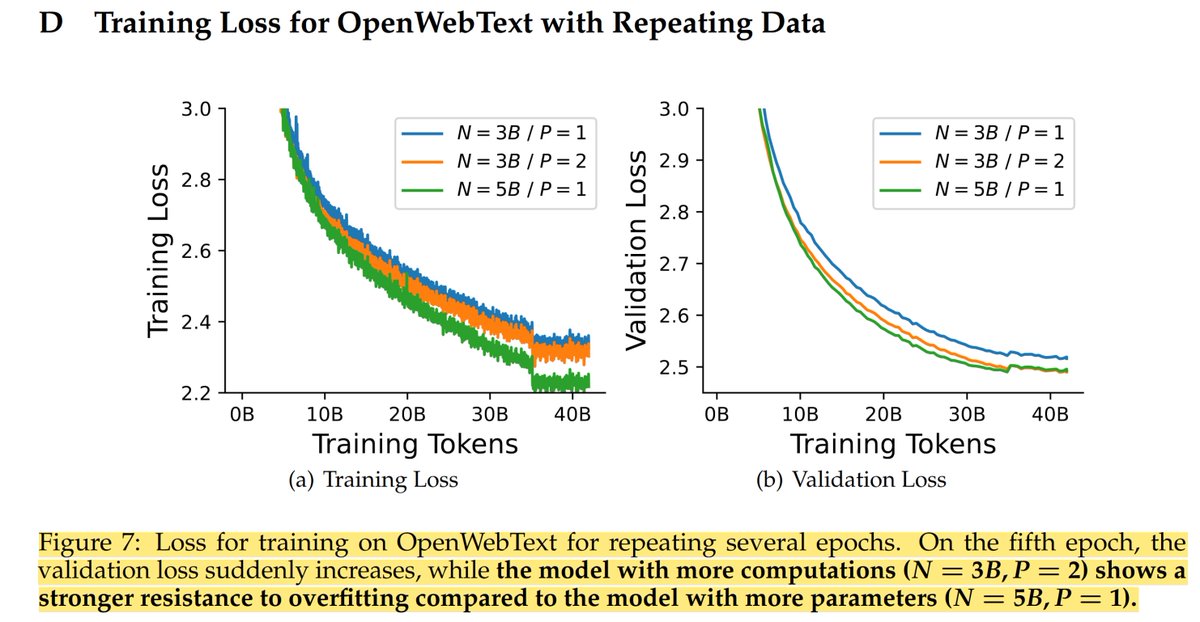
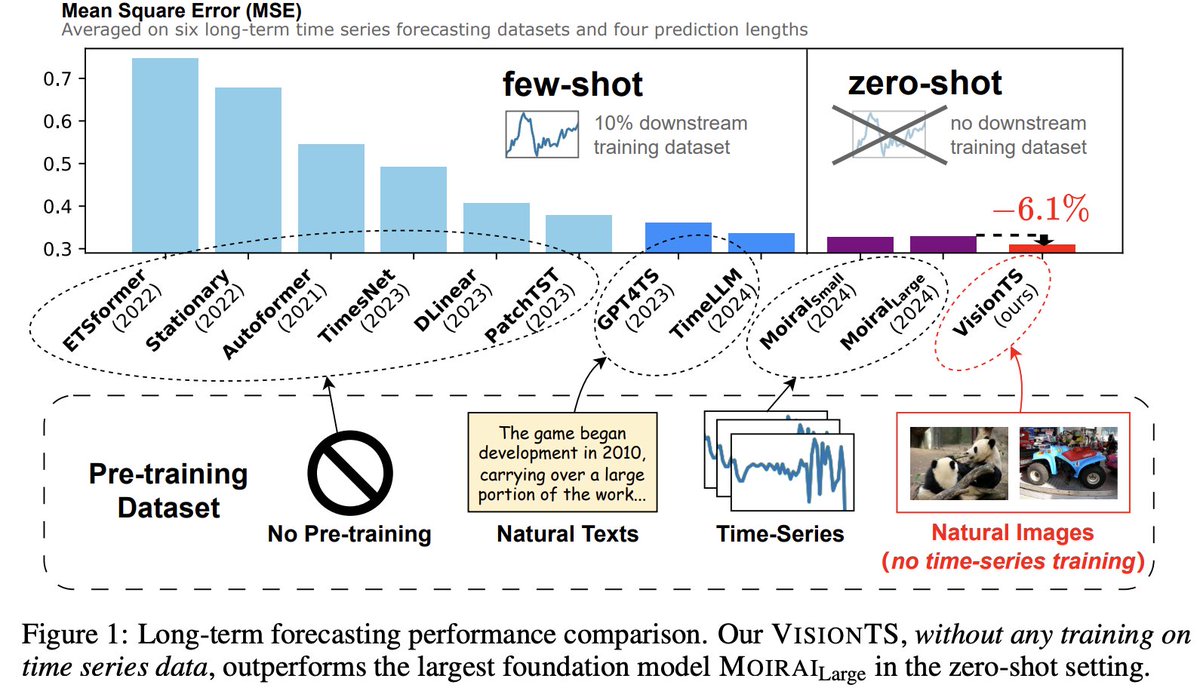
Scaling environment is all your need!
Binyuan Hui@huybery
How to scale training environments for coding agents? Let the agent build their own! 🙌 We introduce SWE-Universe 🪐, a scalable framework that turns GitHub PRs into real-world, multilingual, verifiable SWE environments. The agent configures each environment like a human expert, with extra safeguards for reliability. We’ve validated these environments in both mid-training and RL for Qwen3-Coder-Next, and will push environment synthesis further as a path toward agent self-improvement. Let's move on! 👉 huggingface.co/papers/2602.02…
English