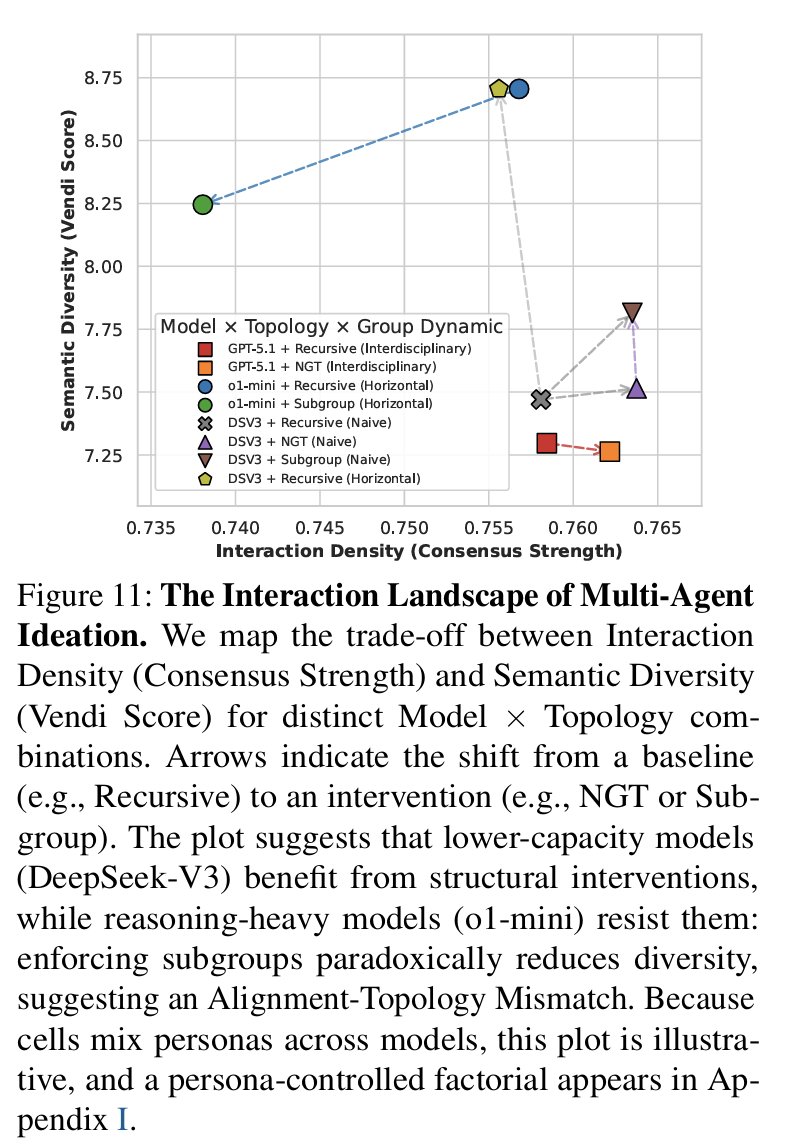
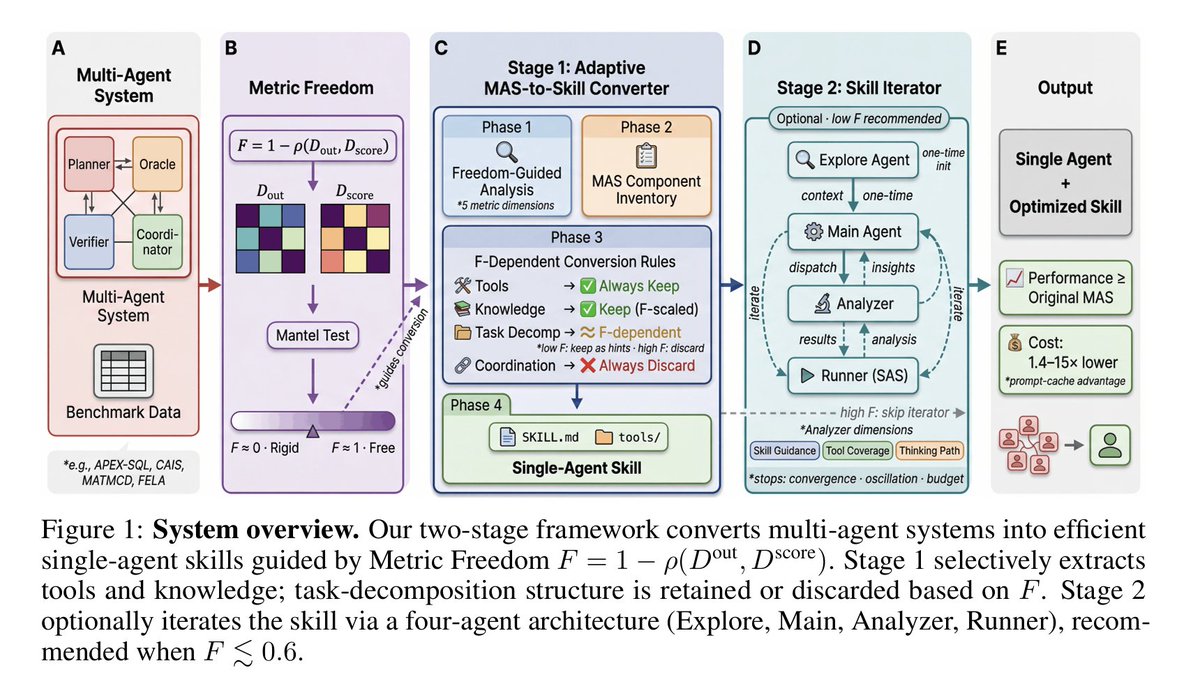
推論LLMのRLで正解率だけを追うと多様性が失われやすい問題に対し、「良い答えの分布」を学ばせるLearning Advantage Distribution for Reasoning(LAD)
GRPOは高advantage応答を増やす更新(単一モードに潰れやすい)、FlowRLは報酬分布への整合、LADはadvantage分布への整合
arxiv.org/pdf/2602.20132
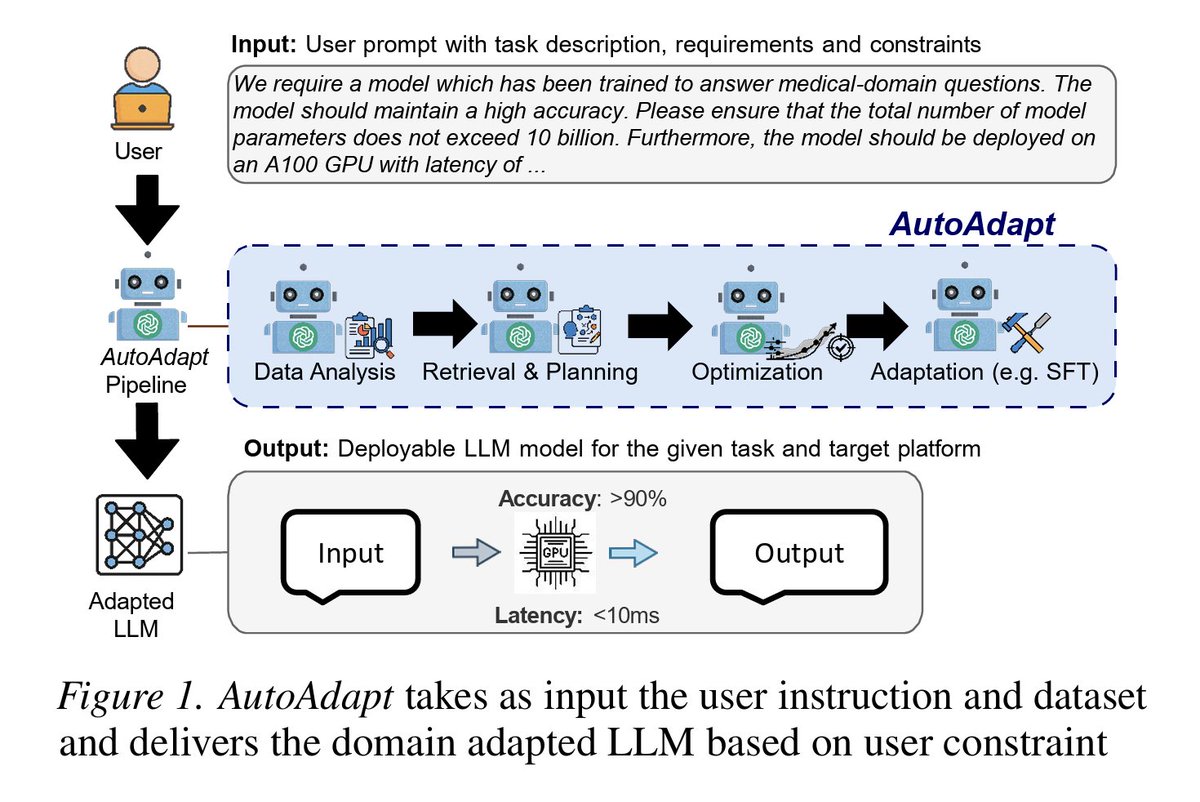
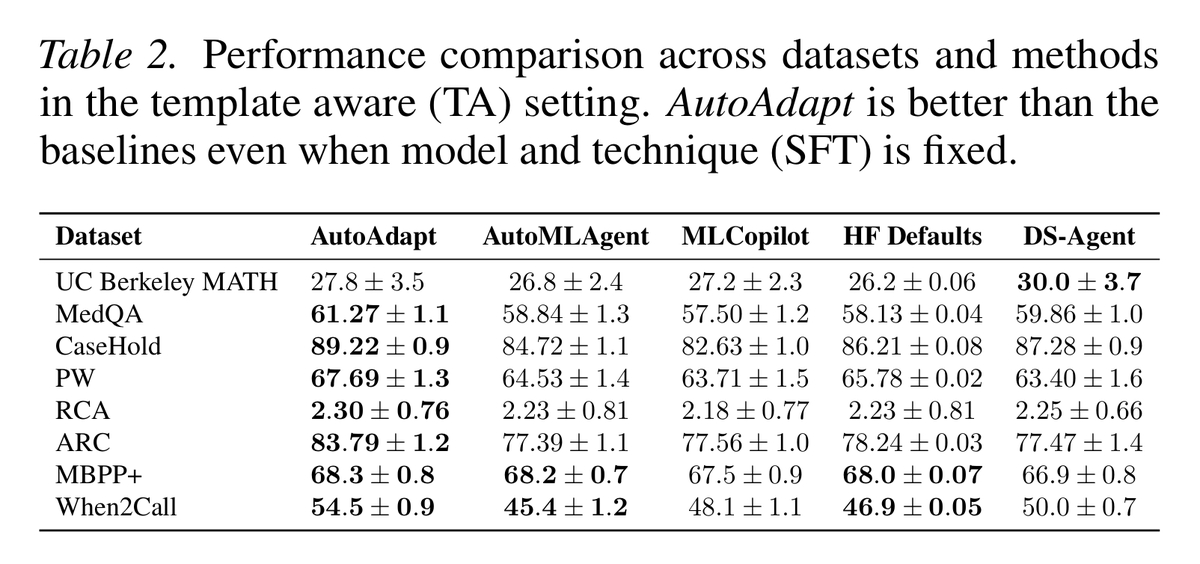
専門領域にLLMを適用する際に、RAG or SFT、LoRAを使うか、学習率やバッチサイズはどうするか、環境制約(GPU、レイテンシ、モデルサイズ上限など)を満たす構成をどうするかなどの決定を自動化するAutoAdapt提案
LLM特化でのドメインへの技術適用を自動化するイメージっぽい
arxiv.org/pdf/2603.08181