What if you could compress a model by 95%… without losing what actually matters? 💡
In this article, our Machine Learning Engineer Javier Boix explores how we tackled one of the biggest challenges in AI deployment: making high-performance models viable in real-world, resource-constrained environments.
At Multiverse Computing, efficiency isn’t a trade-off, it’s the foundation. Using our quantum-inspired compression techniques, we rethink how models are structured to dramatically reduce their footprint while preserving performance.
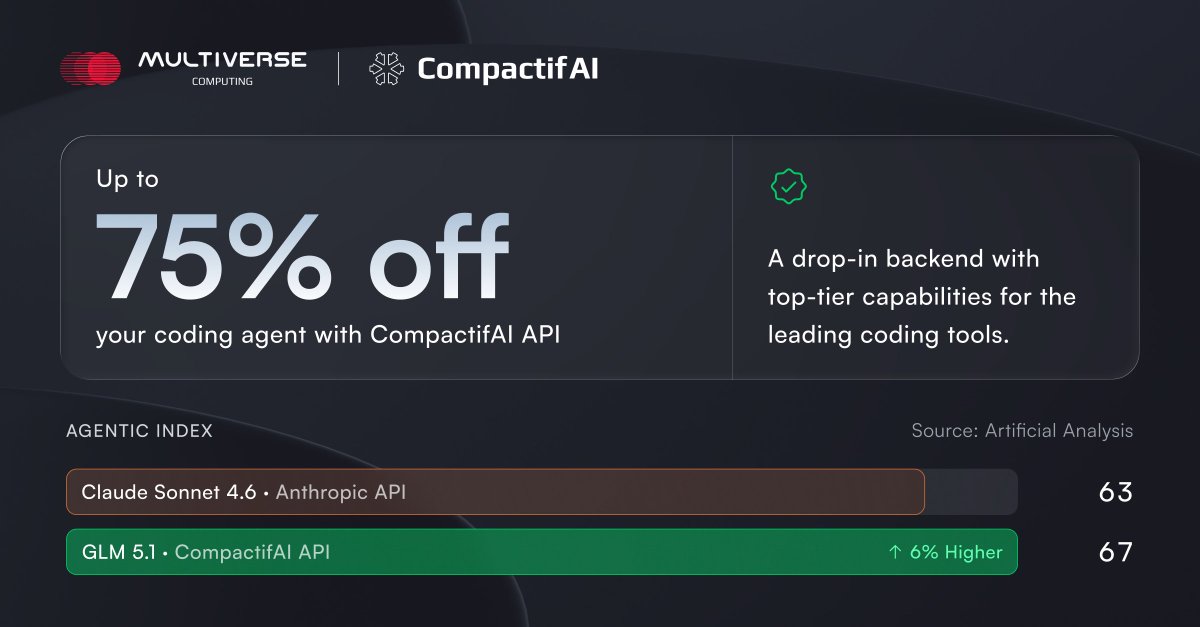
✅ Over 95% model size reduction (from 258 MB to 8 MB)
✅ No meaningful loss in output quality
✅ Up to 2x higher throughput & ~50% lower energy consumption
✅ Deployment-ready models for edge environments
🔗 Find the full article here: ow.ly/wwz750YUtFn

English