Jason Wei@_jasonwei
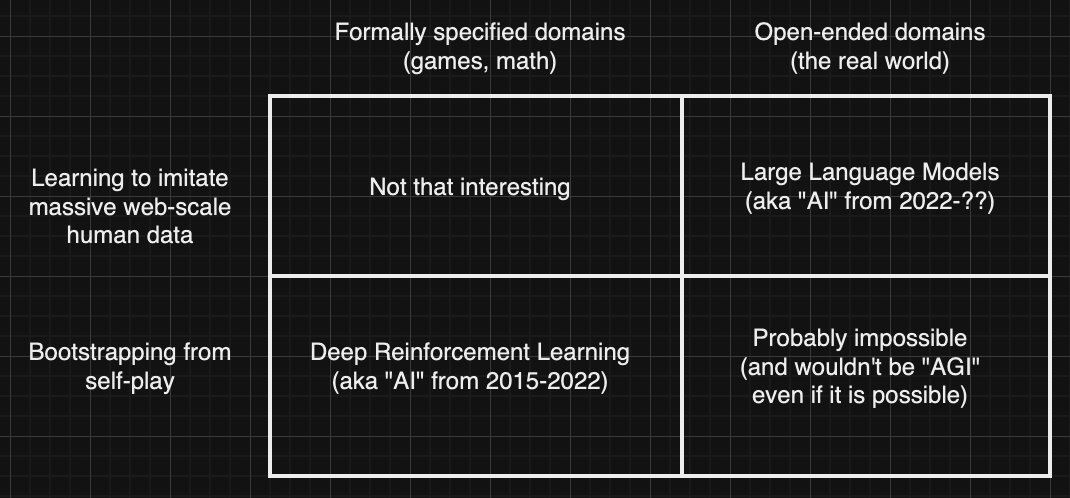
Enjoyed visiting UC Berkeley’s Machine Learning Club yesterday, where I gave a talk on doing AI research. Slides: docs.google.com/presentation/d…
In the past few years I’ve worked with and observed some extremely talented researchers, and these are the trends I’ve noticed:
1. When starting a project, average researchers tend to jump quickly to modeling proposals, architecture design, new ideas, etc. Great researchers often first spend time manually looking at data and playing with models to deeply understand the problem, before proposing an (often simple) approach.
2. Average researchers may often write hacky code that is not reusable and requires many separate steps. Great researchers are often also great software engineers—their code can be easily extended for future experiments, they write extensive tests, and they create infra to run many experiments quickly and visualize results with the fewest clicks.
3. While average researchers might work mostly by themselves or with one or two others, great researchers know that research is a social activity. They collaborate with people of varying experience, share results in writeups, and communicate their vision convincingly.
4. Average researchers might get stuck in rabbit holes—if they have experiments with only mediocre results, they spend 3 more weeks writing it up and submitting it to a conference. Great researchers quickly move on to something else when they know that one approach won’t be a breakthrough.
5. If an average researcher finds some success, they may try to keep doing that thing they are comfortable with for several more years, even if it becomes outdated. Great researchers pivot quickly and keep adapting to new advances and paradigms.
6. Average researchers often implement task-specific solutions, which are heavily optimized for a single task. Great researchers may also work on specific tasks, but they try to think of general approaches that can be applied to many other tasks.
7. Average researchers talk about and optimize for the number of papers or conference acceptances. I have never met a great researcher that still cares about such things.
(And by the way, being an average researcher shouldn’t be taken as an insult. It takes a lot of hard work to even do research at all :))