Sabitlenmiş Tweet

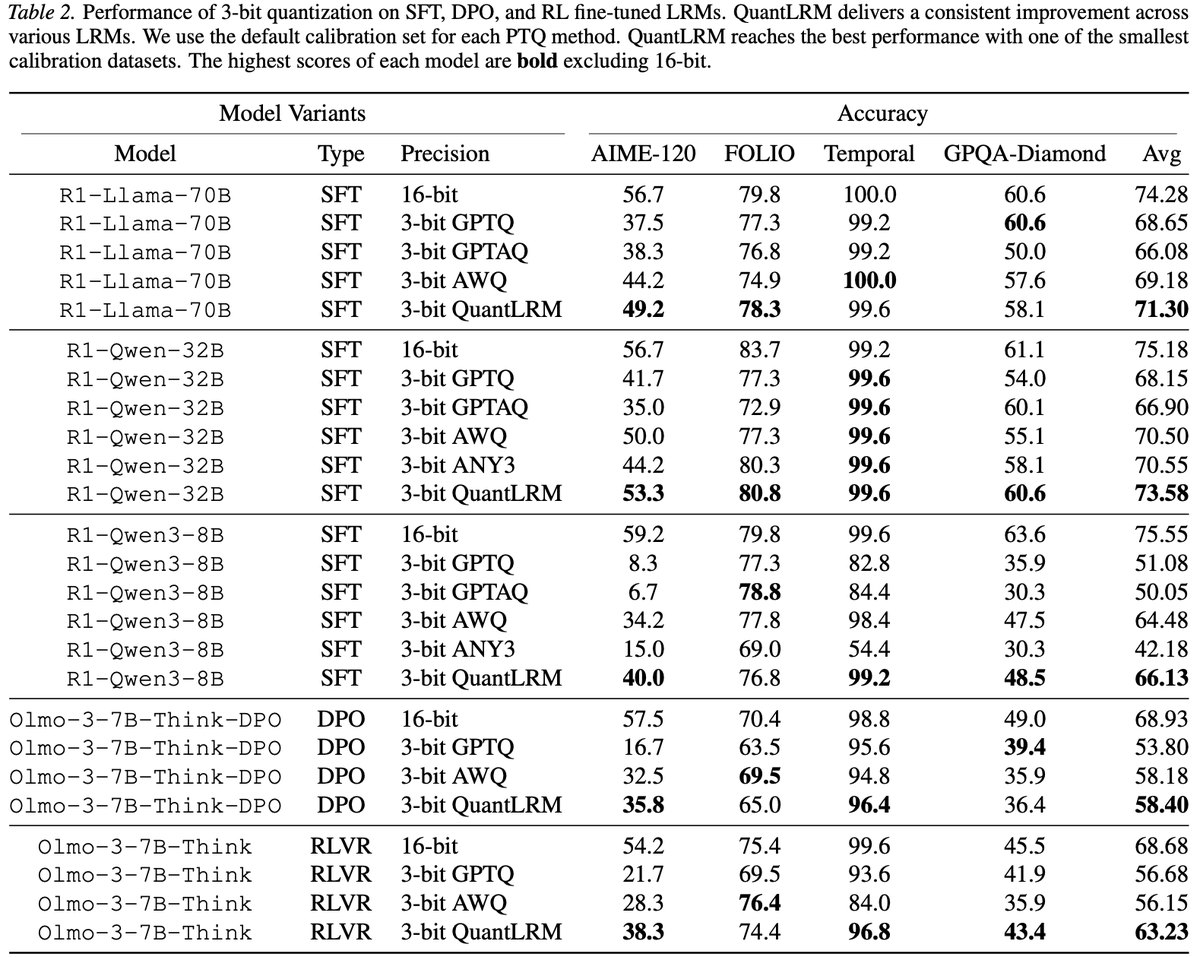
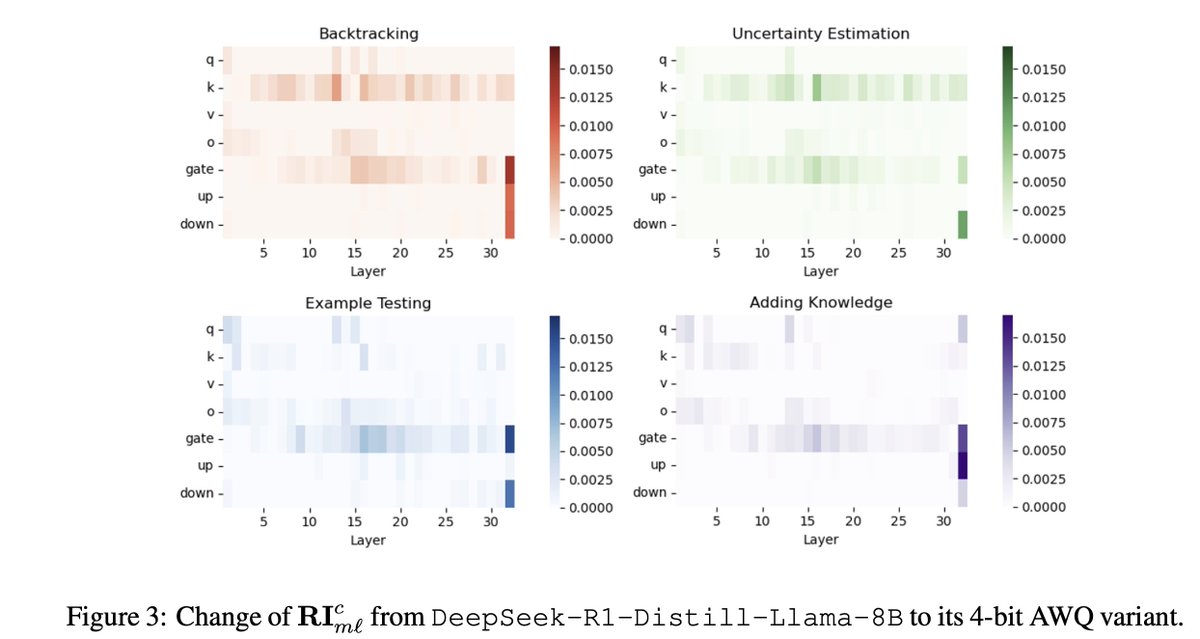
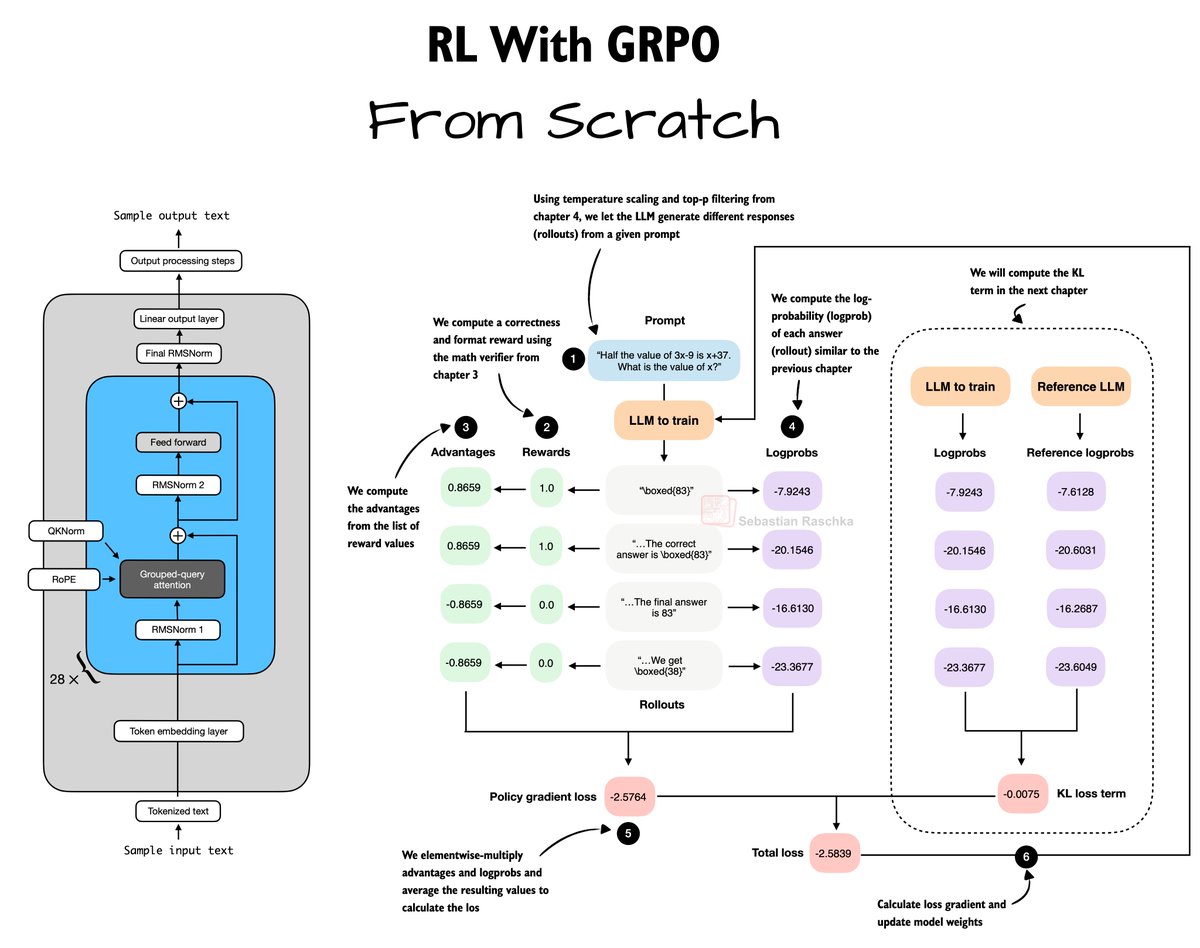
Are there simple and more effective compression signals than activation and 2nd-order info? Yes, fine-tuning traces.
📢Introducing QuantLRM, quantization of large reasoning models via fine-tuning signals.
Code: github.com/psunlpgroup/Qu…
Paper: arxiv.org/abs/2602.02581
(1/N)🧵
English