
English
Nic Wienandt
791 posts

@NicW_AI
AI builder & founder @wAIve_online | AI infrastructure, research, development | Fox Valley AI Foundation | Oshkosh, WI #AI #LocalLLM #llm https://t.co/LXqWQwWuRD




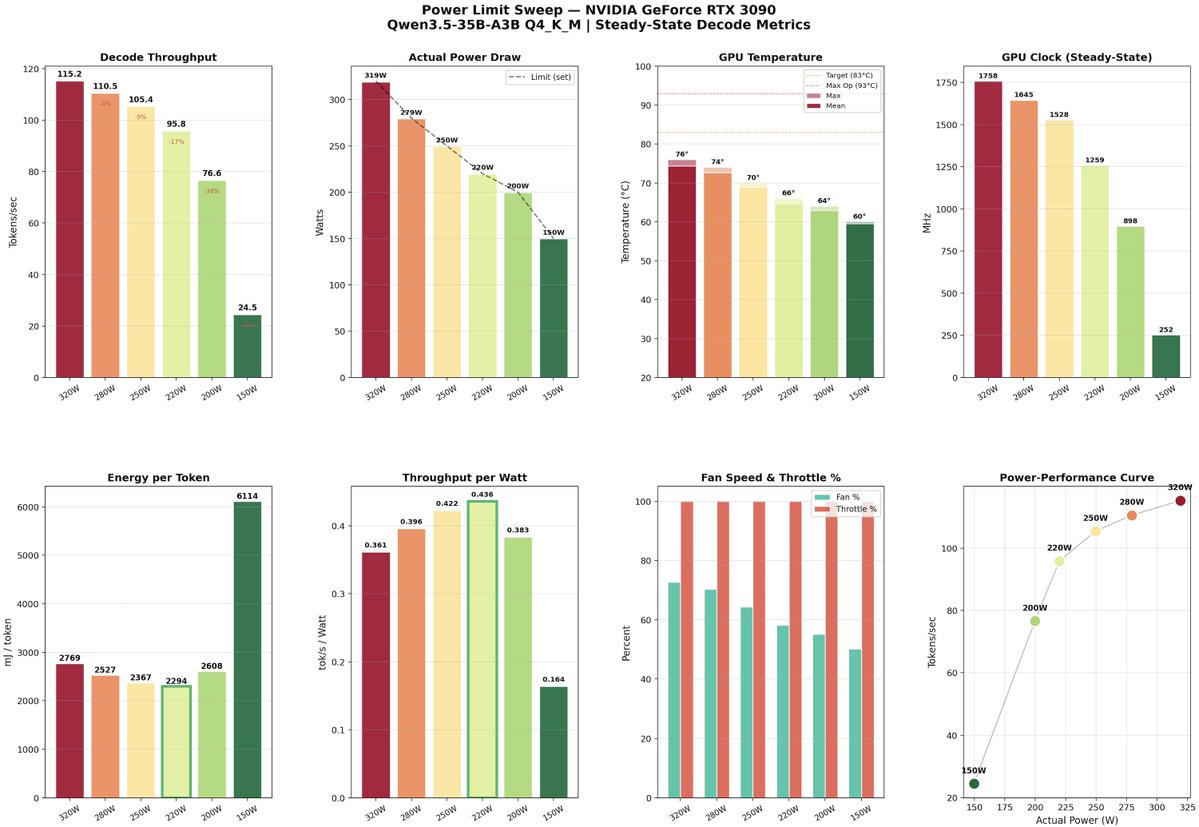
For anyone saying DGX Spark cannot cook. Generating data sets for distilling using Qwen3.5-35B-A3B BF16 !!! (no quants) real data, 0% cache hit, concurrency=192 ; pp=2048 tokens in ; tq=1024 tokens out that`s 1.43M tokens generated every hour for the last 8 hours for 40 W/h.😎

I haven't seen a C++ vibecoder yet. I wonder why?

AI does not write, it produces text. Humans uniquely write.













Introducing TokenSpeed, a speed-of-light LLM inference engine. > TensorRT LLM level performance > vLLM level usability > Built by a lean and mission-driven team in two months > MIT license, open-source github.com/lightseekorg/t… lightseek.org/blog/lightseek…


