Sabitlenmiş Tweet

I enjoyed working on this one. If you're interested in self-attention alternatives, this might interest you. Thanks to all those @ZyphraAI who helped out.
Zyphra@ZyphraAI
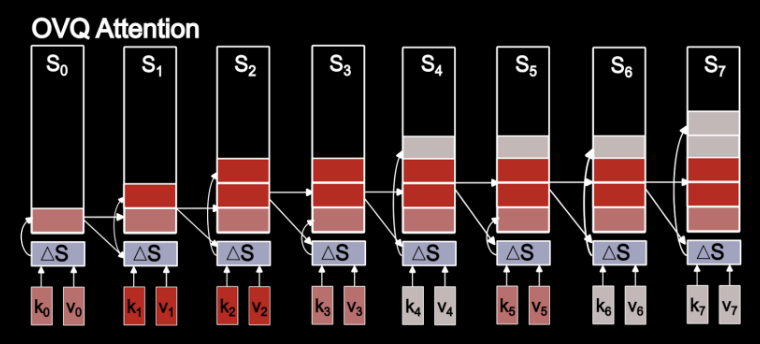
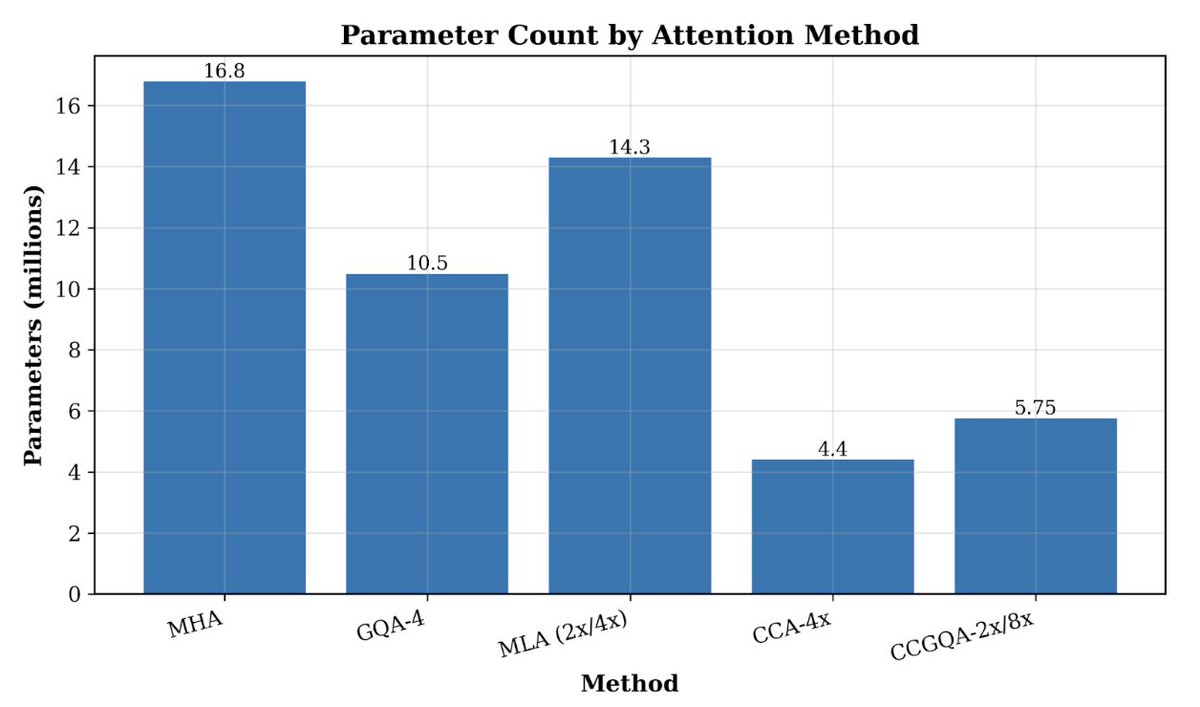
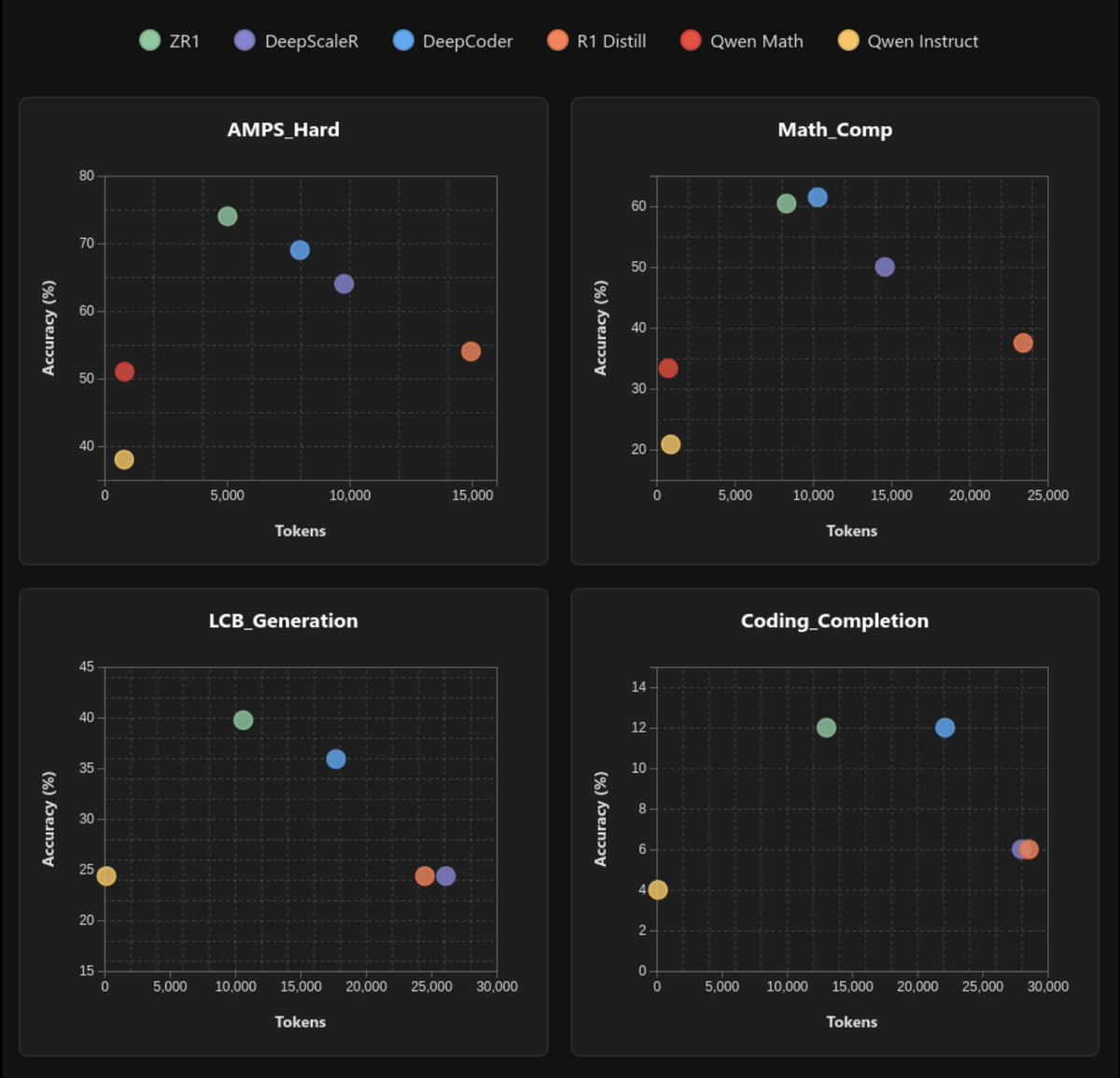
Today @ZyphraAI releases OVQ-attention, an advancement for efficient long-context processing! Existing LLM layers compress input too much, leading to poor long-context understanding, or too little, leading to expensive memory+compute. OVQ-attention is an alternative path. 🧵
English