
Nimrod Berman retweetledi

DoubleAI’s AI system just beat a decade of expert GPU engineering
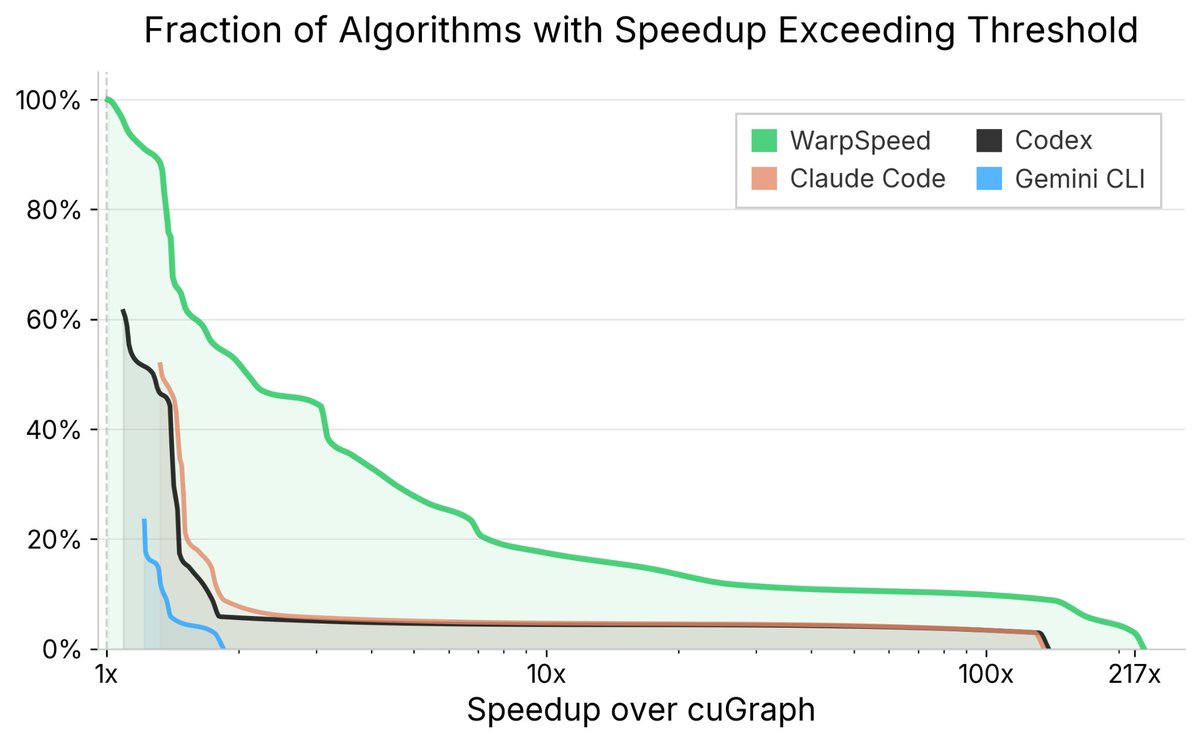
WarpSpeed just beat a decade of expert-engineered GPU kernels — every single one of them.
cuGraph is one of the most widely used GPU-accelerated libraries in the world. It spans dozens of graph algorithms, each written and continuously refined by some of the world’s top performance engineers.
@_doubleAI_'s WarpSpeed autonomously rewrote and re-optimized these kernels across three GPU architectures (A100, L4, A10G). Today, we released the hyper-optimized version on GitHub — install it with no change to your code.
The numbers: - 3.6x average speedup over human experts - 100% of kernels benefit from speedup - 55% see more than 2x improvement.
But hasn’t AI already achieved expert-level status — winning gold medals at IMO, outperforming top programmers on CodeForces? Not quite. Those wins share three hidden crutches: abundant training data, trivial validation, and short reasoning chains. Where all three hold, today’s AI shines. Remove any one of them and it falls apart (as Shai Shalev Shwartz wrote in his post).
GPU performance engineering breaks all three. Data is scarce. Correctness is hard to validate. And performance comes from a long chain of interacting choices — memory layout, warp behavior, caching, scheduling, graph structure. Even state-of-the-art agents like Claude Code, Codex, and Gemini CLI fail dramatically here, often producing incorrect implementations even when handed cuGraph’s own test suite.
Scaling alone can’t break this barrier. It took new algorithmic ideas — our Diligent framework for learning from extremely small datasets, our PAC-reasoning methodology for verification when ground truth isn’t available, and novel agentic search structures for navigating deep decision chains.
This is the beginning of Artificial Expert Intelligence (AEI) — not AGI, but something the world needs more: systems that reliably surpass human experts in the domains where expertise is rarest, slowest, and most valuable.
If AI can surpass the world’s best GPU engineers, which domain falls next?
For the full blog: doubleai.com/research/doubl…
CuGraph:
docs.rapids.ai/api/cugraph/st…
Winning Gold at IMO 2025:
arxiv.org/abs/2507.15855
Codeforces benchmarks:
rdworldonline.com/openai-release…
@shai_s_shwartz post:
x.com/shai_s_shwartz…
From Reasoning to Super-Intelligence: A Search-Theoretic Perspective
arxiv.org/abs/2507.15865
Artificial Expert Intelligence through PAC-reasoning
arxiv.org/abs/2412.02441
English










