Friendly Neighborhood Nobody
54 posts


Friendly Neighborhood Nobody
@NobodyFriendly
Don't mind me.



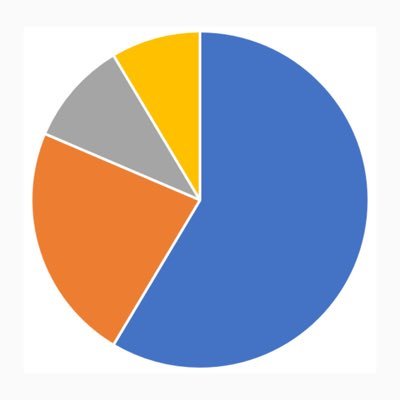

I wish Twitter Articles had an AI detection % at the top of each post




OpenAI’s newest “smarter” models hallucinate 3x more than the ones they replaced. And OpenAI just published a paper explaining exactly why they can’t stop it. The core argument: AI models hallucinate because every benchmark in the industry scores them like a multiple choice test with no “I don’t know” option. Guess wrong? You might get lucky. Leave it blank? Guaranteed zero. So the models learned to guess. Confidently. Every time. The numbers tell the story. On OpenAI’s own PersonQA benchmark, o1 hallucinated 16% of the time. The newer o3 jumped to 33%. o4-mini hit 48%. Three generations of models, each one lying more often than the last. OpenAI’s explanation: the models “make more claims overall,” producing more right answers AND more wrong ones simultaneously. This tells you everything about how the AI industry actually works. The reinforcement learning that makes models better at reasoning also makes them more confidently wrong. The system that produces intelligence and the system that produces hallucinations are the same system. The paper’s proposed fix is where it gets really interesting. They don’t call for better training data or bigger models. They say the entire benchmark ecosystem needs to be rebuilt to reward uncertainty. Every leaderboard, every eval, every scoring rubric needs an “I don’t know” option that doesn’t tank your score. But every AI company uses those same leaderboards to market their models. Admitting uncertainty drops your accuracy number. And dropped accuracy numbers don’t raise $40B funding rounds. OpenAI just published mathematical proof that the incentive structure producing hallucinations is the same incentive structure producing their revenue.

The production of interesting X articles has now officially outpaced my ability to even bookmark them



Claude is woke and their logo looks like an anal sphincter 😂
