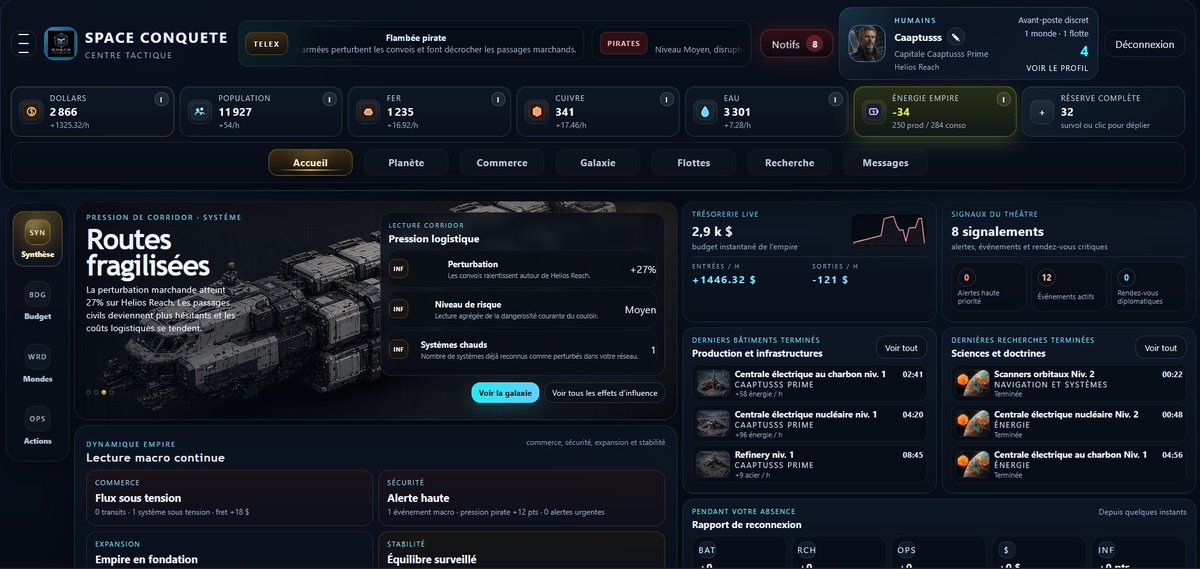
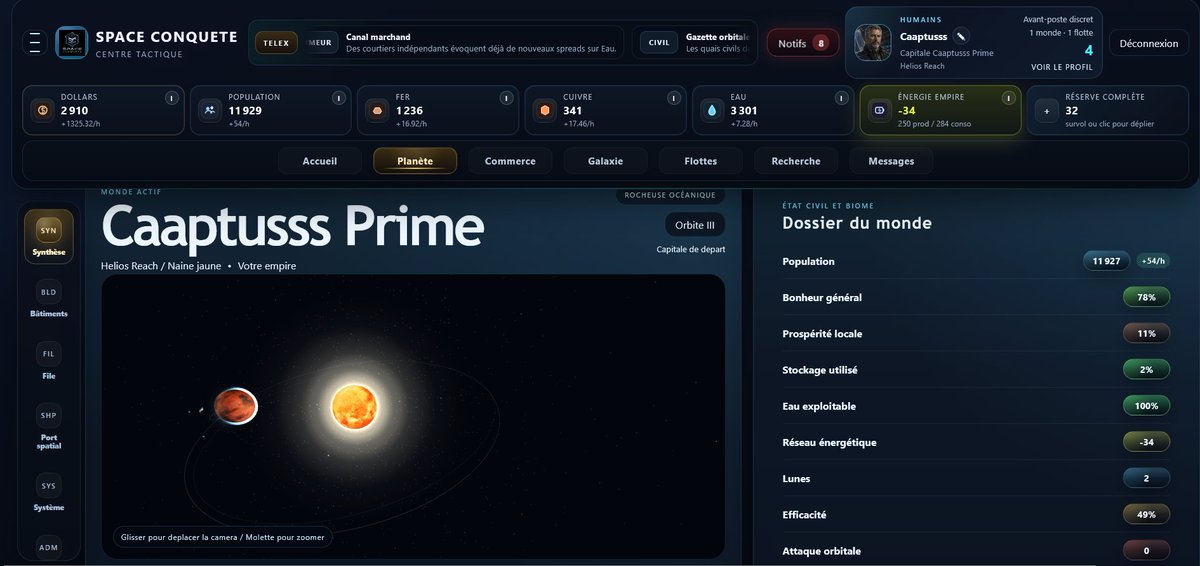
I got tired of abstract AI benchmarks that rank models in isolation. Users don't run a model. They run a full loop: model + harness + tools + retries + cache + prompts. So I ran 27 tasks that look like my real work across different coding-agent harnesses, 5 times each to reduce variance. I also wanted to create my own tasks to avoid the problem of benchmaxxing. Result: near-identical pass rates, wildly different bills. Codex/Claude costs are API-equivalent because I use subscriptions. But at public API prices, one Codex setup charts at ~420× the cost of Pi + DeepSeek V4 Flash for the same strict score. The lesson: the harness is a huge part of the value you feel as a user. And when some loops are this cheap, the optimal strategy changes: you can afford retries, parallel attempts, and verification passes instead of betting everything on one expensive first shot. Don't trust my tasks. Run it on yours.