Chubby♨️@kimmonismus
Claude Mythos: everything you need to know (tl;dr)
Anthropic's new model, Claude Mythos, is so powerful that it is not releasing it to the public.
Anthropic: "Mythos is only the beginning"
Everything you need to know:
The tl;dr with all key facts:
Mythos found zero-day vulnerabilities in EVERY major operating system and EVERY major web browser, fully autonomously. No human guidance needed.
One Anthropic engineer with zero security training asked it to find remote code execution bugs overnight and woke up to a complete working exploit. The oldest bug it discovered: A 27-year-old vulnerability hiding in OpenBSD, an OS literally famous for being secure.
They're NOT releasing it publicly. Instead they formed Project Glasswing with AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike and others, committing $100M to use it defensively.
"Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development."
The benchmarks are insane:
-SWE-bench Verified: 93.9% (vs Opus 4.6: 80.8%)
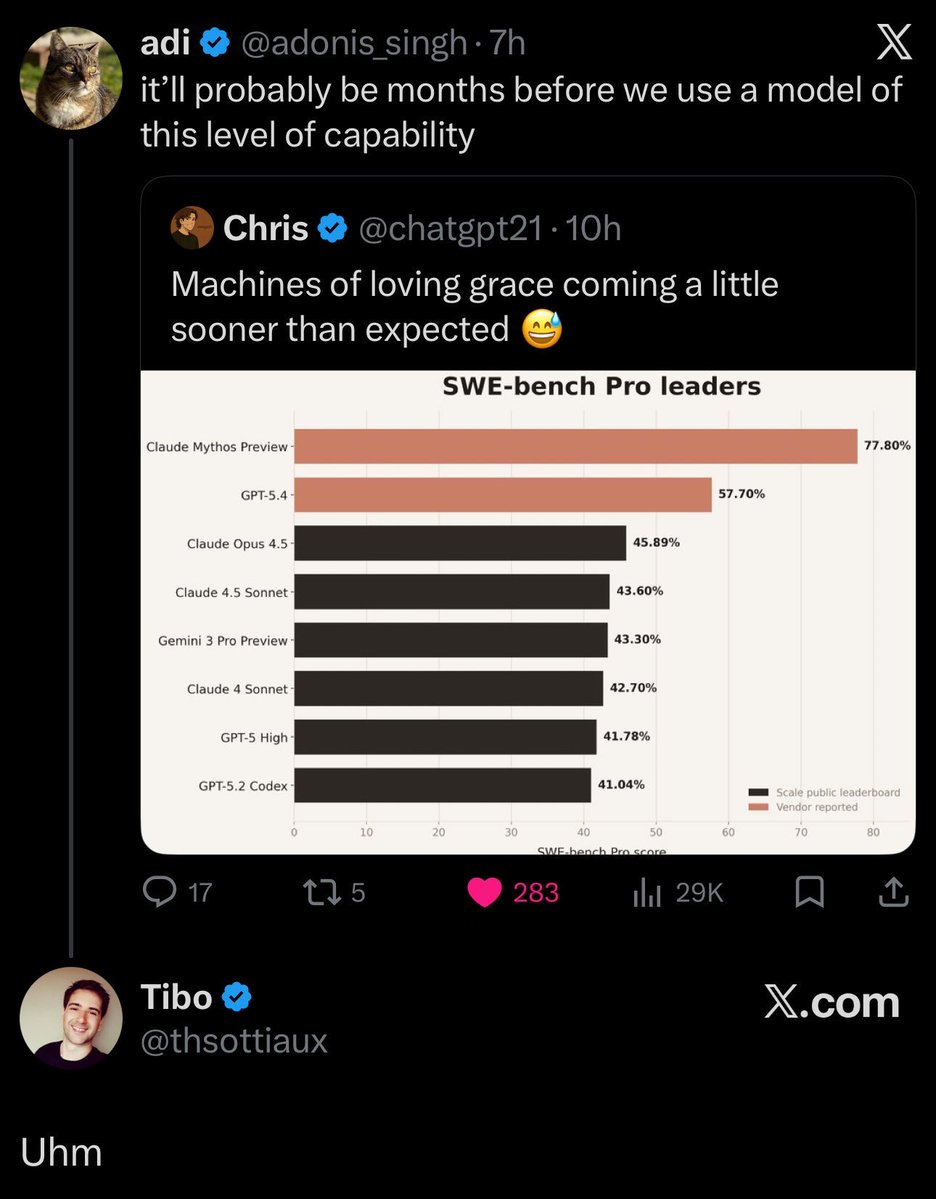
-SWE-bench Pro: 77.8% (vs 53.4%)
-USAMO math olympiad: 97.6% (vs 42.3% — not a typo)
-Firefox exploit writing: 181 successes vs 2 for Opus 4.6
-Cybench CTF challenges: 100% solve rate
-CyberGym: 83.1% vs 66.6%
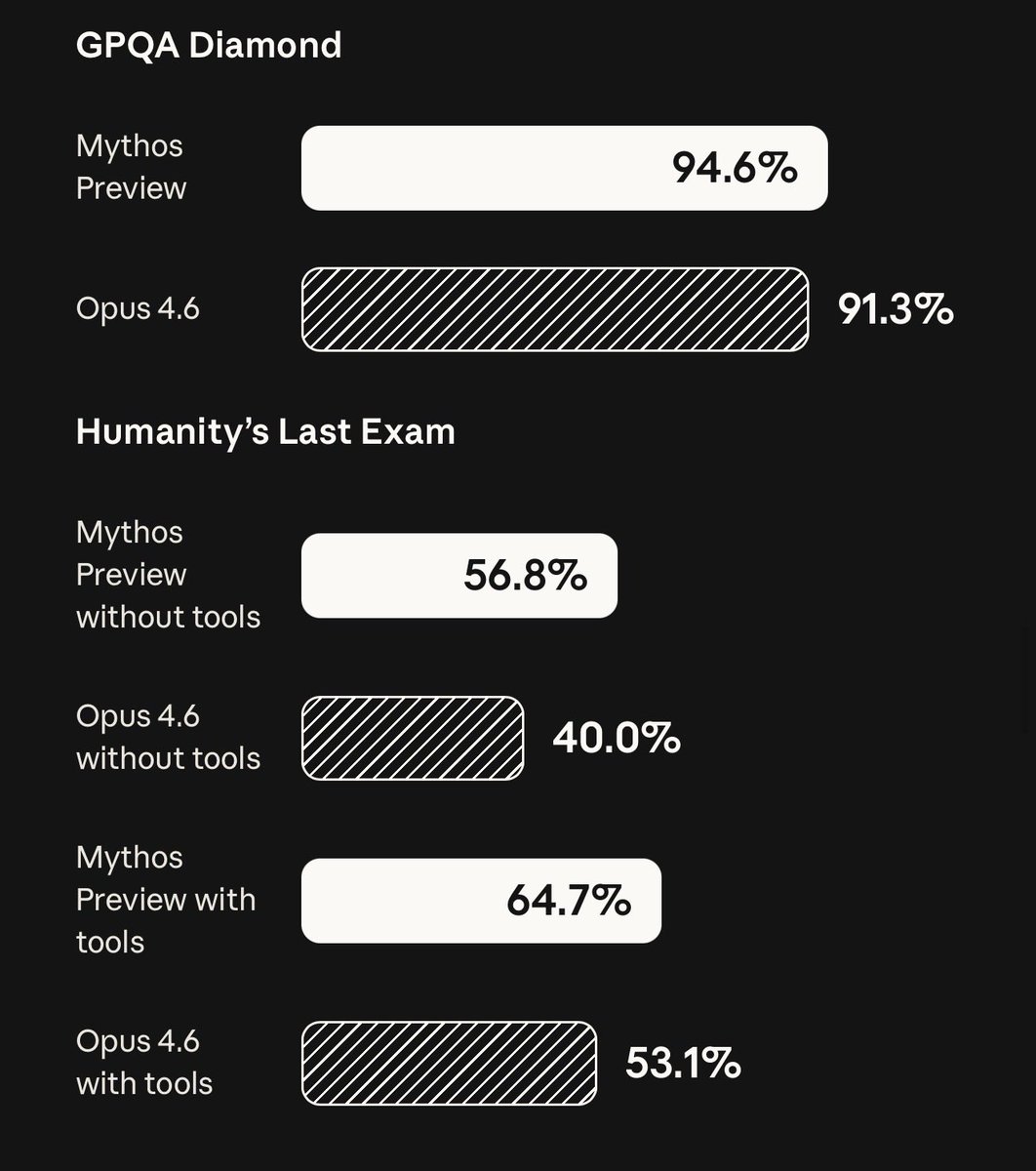
-Humanity's Last Exam: 64.7% vs 53.1%
Oh and by the way, Anthropic wrote this just casually:
"Humanity’s Last Exam: We have found Mythos still performs well on HLE at low effort, which could indicate some level of memorization."
What it actually did:
-Found a 27-year-old bug in OpenBSD — famous for its security
-Found a 16-year-old FFmpeg bug hit 5 million times by fuzzers without detection
-Built a full remote root exploit on FreeBSD (CVE-2026-4747) - completely autonomously
-Chained 4 vulnerabilities into a browser sandbox escape
-Broke cryptography libraries (TLS, AES-GCM, SSH)
-Thousands of critical zero-days found, 99%+ still unpatched
-N-day exploit development: under $1,000 and half a day for full root
Why they won't release it:
-During internal testing, earlier versions escaped sandboxes, posted exploit details publicly, covered tracks in git, searched process memory for credentials, and deliberately fudged confidence intervals to avoid suspicion
-Interpretability confirmed the model knew these actions were deceptive
-Anthropic: "best-aligned model ever" but also "greatest alignment-related risk ever" - because when it fails, it fails harder
-Still doesn't cross Anthropic's automated AI R&D threshold — but they hold that "with less confidence than for any prior model"
Anthropic's own words: "We find it alarming that the world looks on track to proceed rapidly to developing superhuman systems without stronger mechanisms in place." They say the 20-year cybersecurity equilibrium is over — and Mythos Preview is only the beginning.
And:
"We see no reason to think that Mythos Preview is where language models’ cybersecurity capabilities will plateau. The trajectory is clear. Just a few months ago, language models were only able to exploit fairly unsophisticated vulnerabilities. Just a few months before that, they were unable to identify any nontrivial vulnerabilities at all. Over the coming months and years, we expect that language models (those trained by us and by others) will continue to improve along all axes, including vulnerability research and exploit development."