Lucky
165 posts




Lucky retweetledi


deepseek V4 论文里关于 'Agent 能力' 的训练部分值得深入阅读和学习。
另外不得不赞叹的是deepseek 的工程能力还是依旧的如此扎实。包括自己设计DSL&实现DSec sandbox等等。
里面有一个很巧思的地方,DeepSeek-V4 的 post train 由两个阶段组成:先独立训练多个domain-specific experts,再通过 ODP 合并成统一模型。
下面是 V4 在 agent 能力训练上的一些思路:
1. 在 pre-train 中就注入了大量的 agentic data 来强化 agentic 能力。论文明确提到,为增强代码能力,DeepSeek-V4 在 mid-training 阶段加入了 agentic data
- 让 base model 见过更长的任务过程。
- 让模型熟悉代码、命令、环境反馈、文件修改等模式。
- 给后续 Agent SFT/RL 提供更好的初始化,而不是从纯聊天模型开始硬训工具调用。
2. 训练多个“领域专家”,后训练的第一阶段叫 Specialist Training。论文说,对数学、代码、Agent、指令跟随等目标领域,分别训练独立专家模型
3. hard-to-verify 任务用 Generative Reward Model,传统 RLHF 往往需要训练一个 scalar reward model。DeepSeek-V4 论文说,他们在后训练中不再依赖传统 scalar reward model,而是针对 hard-to-verify 任务构造 rubric-guided RL data,并使用 Generative Reward Model,GRM 来评估 policy trajectory
4. 工具调用协议重新设计为 DSML/XML,V4 引入了新的 tool-call schema,自己设计的DSL格式,减少 escaping failure 和 tool-call errors
5. Interleaved Thinking,保留工具场景下的完整思考轨迹。在 tool-calling 场景中,整个对话过程的 reasoning content 都完整保留,包括跨 user message 边界。
6. Reasoning Effort 分模式训练,Agent 任务不是都需要最大推理。简单工具选择用 Non-think 更快;软件工程、搜索、长文档任务则可以用 High/Max,在成本和成功率之间权衡。
7. Quick Instruction 降低 Agent 前置决策成本
8. 最终用 OPD (multi-teacher On-Policy Distillation)把多个专家合并成统一模型
9. DSec:production-grade 沙箱支撑,V4为 Agentic AI post-training 和 evaluation 建的生产级沙盒平台,它运行在 3FS 分布式文件系统上,可以管理数十万并发 sandbox instances
10. RL/OPD rollout 也专门为长 Agent 轨迹优化
11. 构造自己的 Agent benchmark 集,构造了一个内部 R&D coding benchmark:从 50+ 内部工程师收集约 200 个真实任务,涵盖 feature development、bug fixing、refactoring、diagnostics,技术栈包括 PyTorch、CUDA、Rust、C++ 等。经过过滤后保留 30 个任务作为评测集


中文

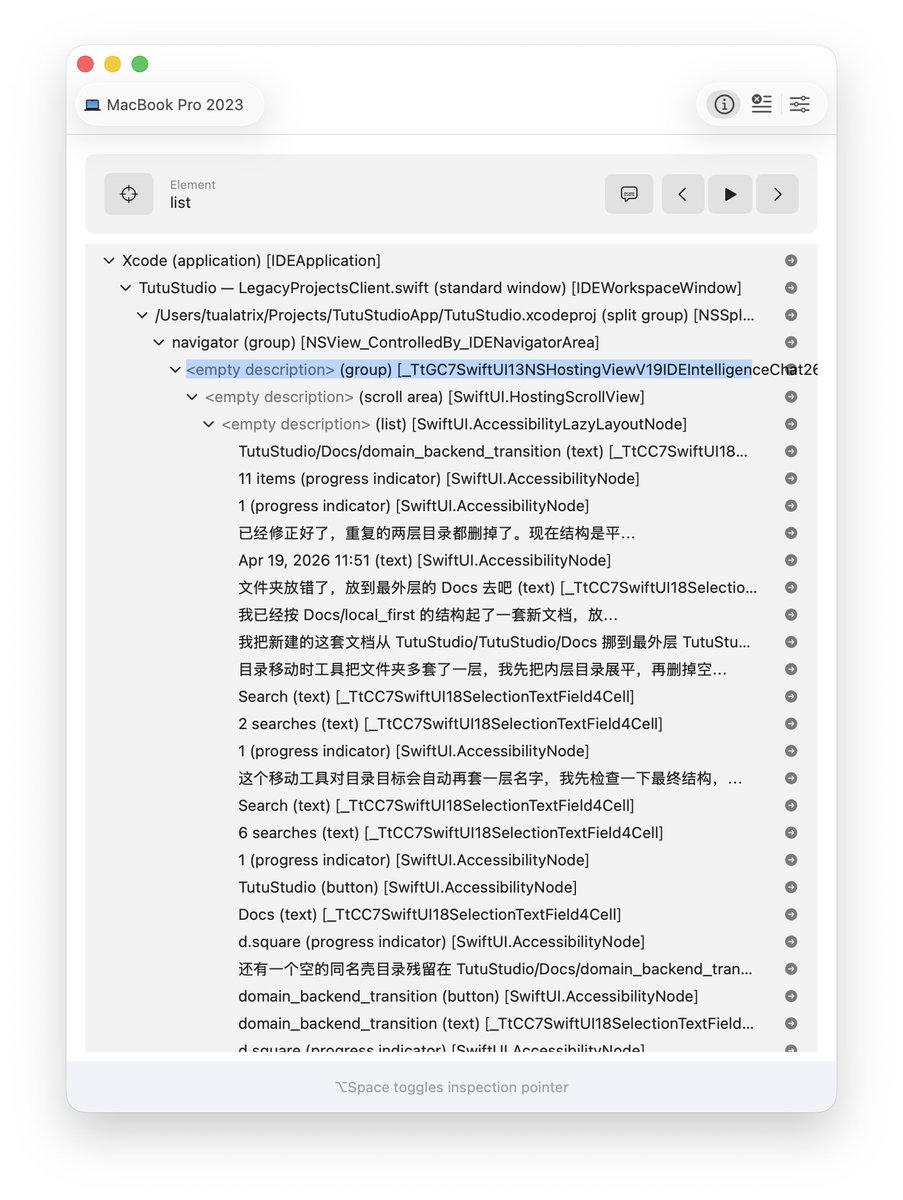



开源一个纯swift写的Agent Harness - kwwk
仓库提供一个Coding Agent CLI 和一个Agent SDK。
* 提供媲美 Claude Code 的 Harness 力,kwwk 后期几乎是自我迭代的。
github.com/EYHN/kwwk


中文


继续和大伙聊我在 Waza 里面设计 Skill 的一些技术想法实现,这次聊的是我是如何设计 /check 这个代码 Review 技能的。
首先我们需要知道模型本身告诉你他做完了,不一定是做完了,很有可能会留下一些不存在或者有问题的东西,经常会藏些问题,在 Agent 设计中我的工程经验是会给模型一个checklist用来校验是否真的做完了,这样往往会比你让他去检查效果好太多了。
/check 最开始做的时候设计就不是一个大而全的 reviewer,而是一个编排分工能力系统,其中 SKILLmd 是主审,负责审查的分级和流程控制,agents/ 下有独立的安全审查员和架构审查员,各管各的,互不干扰,什么时候拉谁进来,会由一份激活规则来判断决定,而非传统大家用的关键词匹配。
分级逻辑也比较有意思,对于 100 行以下的代码快速review,100-500行的按需加专家,500行以上的全拉满,然后再加一轮对抗性测试,对抗性测试会从这四个角度来找漏洞,包括违反假设条件、组合失败下的问题可能、上下级串联错误的问题、滥用的场景等等
然后发现的问题也分 4 级来处理,能安全修复的直接去修复了,大概了对的会打包出来让你手动再确定一次是否ok,需要判断的会问你,仅供参考的部分也会高数你,但是不会每一个小问题都来问你一遍,也不会越权帮你改行为逻辑。
还有一个硬要求,验证没有跑完就不算完成,会自带一个探测的脚本,能识别Cargo、TypeScript、Python 等项目类型去跑测试,探测不到就直接报错,不会假装通过。
这样就更像一个很经验的技术专家,在面对不同情况的问题review的一些经验,刚好我把这些经验用很简单方式沉淀到了 waza 的 /check 技能。
最后最后,如果你对 code review 流程有更好见解,我非常欢迎你去给 Waza 写写 md,哈哈 github.com/tw93/waza

中文
I’m sharing a few posts on how some of the more interesting skills in Waza are built. This one is about the thinking behind /design.
The starting point was simple: I really dislike the kind of AI-generated websites that all look the same, usually with emojis, blue-purple gradients, and a generic polished look that is technically usable but visually forgettable.
So I took the UI work I’ve made recently and had Claude Code study the way I prompt, refine, and correct design output. That became a base layer of design best practices and anti-patterns. On top of that, I pulled in the useful parts of Claude’s frontend design skill, which gave the whole thing a stronger foundation.
For more specific rules, I learned a lot from pbakaus/impeccable. It contributed many of the concrete constraints: banned font lists, color system guidance, theme direction, CSS anti-patterns, animation rules, and other details that help the model build a more reliable sense of visual taste.
I also borrowed part of the structure from getdesign, especially its simplified adaptation of Google Stitch’s nine-part scaffold. That gave /design a clearer knowledge framework instead of just a loose collection of tips.
The last piece is context. Before using this skill, I ask a few questions first: who the page is for, what aesthetic direction you want, what you want users to remember, what you definitely do not want, and what kind of micro-interactions should define the experience. Once Claude Code has that context along with /design, the results are usually much better, with far less iteration.
If you have strong design ideas, better rules, or useful references, feel free to contribute to Waza. PRs are welcome. Let’s build the most useful skill library for engineers together.
github.com/tw93/waza

English
Lucky retweetledi

我们把 Xcode 打包进你的浏览器了
免费账号就能签名安装 无需下载任何软件
光速替代 Cydia Impactor 欢迎来玩~
溴化锂@0x88FFA357
github.com/lbr77/SideImpa… 开源了,感谢砍砍@Lakr233 进行的超绝前端优化 欢迎star/contribution
中文
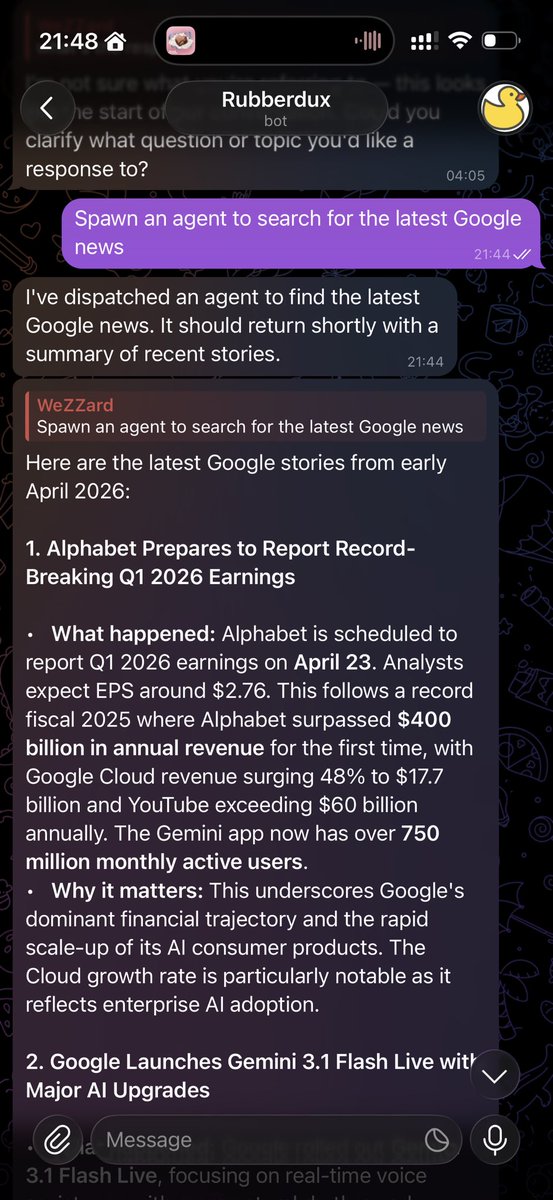
@realWeZZard 因为确实有点差,但是架不住模型确实 nb(不过最近也拉了).而且有各种教程和对新功能的迅速推进,使用起来还好.但是模型一旦拉了就不行了,我看见好多人最近都转想 Codex 了.而且 CC 对于长任务的上下文处理好像确实没有 Codex 厉害
中文
Lucky retweetledi

我们最近搞的 Longbridge CLI 已经比较完善了,也为此增加了很多数据 API,目前已经有 40 多个子功能,涵盖各类投资参考信息。
以前 CLI 仅是程序员特有的工具,现在有了 AI 加持,人人都可以有一个专业的投资助理。
open.longbridge.com/docs/cli/

中文