Synthetic Insurance Claims Dataset
SKU: INS001 │ Insurance and Risk Modelling │ $48,000
Multi-LOB Fraud Taxonomy · Subrogation Recovery Pairing · CAT Event Clustering · Grade A+ Validated · Zero PII
INS001 delivers enterprise-grade synthetic insurance claims data across multi-line, multi-carrier environments spanning 10 lines of business — Auto PL, Home PL, Renters, Commercial Property, General Liability, Workers Comp, Professional Liability, Cyber, Marine, and Medical Health. Every claim is lifecycle-complete: FNOL intake through reserve setting, payment, subrogation pursuit, salvage disposition, litigation escalation, and closure — all governed by ISO ClaimSearch, Guidewire ClaimCenter, and Duck Creek posting patterns. The dataset ships benchmark-first — Grade A+ (100.0/100) on default parameters — with all 12 benchmark tests sourced to ISO/Verisk, NAIC, NICB, WCRI, AM Best, and Swiss Re.
xpertsystems.ai
Pharmacy & Drug Interaction Dataset ($125,000) HLT-QA-004
Use Cases
• Pharmacy AI copilots
• Drug interaction engines
• EHR clinical decision support
• AI safety evaluation (LLM alignment)
• Medication adherence assistants
XpertSystems.ai Synthetic Data Platform
The Challenge
Medication safety AI systems fail due to lack of high-quality labeled drug interaction data. Real-world datasets are fragmented, restricted, and lack structured severity, contraindication, and escalation labels.
What Makes This Different
• 60,000 Q&A pairs with drug interaction logic
• Severity classification (minor → contraindicated)
• Pharmacology-grounded signals (CYP, QT, serotonin)
• Safety-critical escalation labels
• Adversarial jailbreak scenarios
What You Receive
questions.csv, answers.csv, qa_pairs.csv, drugs.csv, interactions.csv, patients.csv, dosing_guidelines.csv, adverse_events.csv, contraindications.csv, conversations.csv, adversarial_pairs.csv, safety_audit.csv, manifest.json
ML Feature Pack
70+ features across interaction severity, pharmacology, patient risk, safety compliance, and adversarial signals.
Why Synthetic Data Wins
• No PHI risk
• Fully labeled interaction graph
• Scalable to rare edge cases
• Deterministic and customizable
xpertsystems.ai
Synthetic Ransomware Attack Simulation Dataset (SKU: CYB005)
Enterprise License | $ Please Call
MITRE ATT&CK Calibrated · CIRCIA/NIS2/DORA Compliant · FBI IC3 Benchmarked · Zero PII · Delivered in 48 Hours
THE CHALLENGE
01 The Data Gap
Real ransomware attack telemetry is withheld under IR confidentiality agreements, cyber insurance NDAs, and FBI/law enforcement data-sharing restrictions — making it unavailable for training, testing, or benchmarking EDR, XDR, and SIEM systems.
02 The Compliance Mandate
CIRCIA (CISA), NIS2 Article 21, DORA Article 26, and NIST CSF 2.0 Respond/Recover all mandate ransomware resilience testing before production deployment — creating a mandatory purchase category for critical infrastructure operators and financial sector firms.
03 The Benchmark Gap
Public ransomware datasets (CISA advisories, FBI Flash alerts) contain no trajectory-level kill-chain sequences, no per-phase defender interaction dynamics, no blast radius distributions across backup maturity tiers, and no ransom negotiation outcome modelling.
What Makes This Dataset Different
✓ Seven-phase ransomware kill-chain FSM initial_access → recon → lateral → escalation → exfiltration → detonation → negotiation
✓ Four-tier actor capability model lone_actor through nation_state_nexus with distinct encryption speed, ransom demand, and wiper probability
✓ Six-tier victim backup maturity model no_backup through air_gapped_gold_standard — each with calibrated recovery_prob and recovery_time distribution
✓ Novel ransomware event types vss_deletion_attempted, lateral_worm_propagation, double_extortion_threat_issued, wiper_component_activated, honeypot_canary_triggered
✓ Exclusive KPIs resilience_score, financial_impact_score, insurance_loss_ratio_score, mean_time_to_detect_hrs, encrypted_data_recoverability_score
✓ 50 ML features across 5 domains Pre-split chronological 80/20 train/test sets + signal labels + detection labels included
✓ Grade A+ validation — 12 benchmark tests Mandiant M-Trends, Sophos, FBI IC3, Verizon DBIR, IBM, Veeam, ESET, Coveware, CISA, CrowdStrike
✓ Dual buyer market Security vendors (detection training) AND cyber insurance carriers (actuarial underwriting) — unique in the portfolio
✓ Deterministic & reproducible Integer seed control for exactly repeatable datasets across any scale
xpertsystems.ai
Tactical Decision Synthetic Dataset (DEF-DEC-001)
Time-pressured tactical decisions with doctrinal concordance, ROE/LOAC compliance, and ground-truth outcomes — built for the multi-domain fight.
Decisions, not data points
DEF-DEC-001 supplies the time-pressured action substrate that tactical AI has been missing.
Real operational data is classified, restricted, or unreleasable. Open-source extracts lack ground truth. Wargame logs lack adaptive adversaries. DEF-DEC-001 closes the gap with a fully synthetic, doctrinally-consistent dataset that pairs every tactical decision with the conditions that produced it and the outcome it earned.
The dataset is engineered around the kill chain itself — Find, Fix, Track, Target, Engage, Assess — and around every gating function commanders actually weigh: ROE / LOAC, deconfliction, sustainment burn, sortie generation, coalition caveats, and adaptive adversary counteraction. Every row is a state → time-pressured action → outcome triple with doctrinal-pathway encoding and a counterfactual branch for off-policy evaluation.
xpertsystems.ai
The Economics of AI Safety Evaluation Data Are About to Change Permanently — Here's What the Next Three Years Actually Look Like
Why per-prompt pricing is dying, why the procurement-grade methodology stack creates structural moats, and why the synthetic-data market is about to bifurcate into two categories that will look like different industries by 2028.
I have spent the previous nine articles in this series mapping the landscape of adversarial evaluation data — the medical surface, the cyber surface, the legal surface, financial, HR, cross-lingual, child safety, agentic. Different domains, different author networks, different regulatory regimes, different methodological extensions.
Read together, they describe a single market in formation. And the economics of that market are about to change permanently in ways that most synthetic-data vendors and most frontier-lab procurement teams have not yet fully internalized.
This is the capstone article in the series. It is about the business model, the pricing dynamics, the moat structure, and the three-year market trajectory. If the previous articles answered the question 'what does the data look like,' this one answers the question 'who makes money in this market and how.'
The death of per-prompt pricing
The synthetic-data market grew up on per-prompt pricing. A vendor produced prompts, the buyer paid by the prompt, the unit economics were straightforward, and the competitive dynamic was about cost-per-prompt and volume. This pricing model worked when the dominant use case was generic refusal-training data and when the buyer was a research team that could absorb low quality at high volume. It is dying for the procurement-grade adversarial-evaluation use case for three reasons.
The first reason is that the cost structure of procurement-grade work does not scale with volume. The methodological work, the author vetting, the validation infrastructure, the regulatory mapping, the trajectory-scoring rubrics — these are largely fixed costs that have to be amortized over the buyer relationship rather than the prompt count. A vendor pricing per prompt either underprices the methodology and goes broke or overprices the methodology and prices itself out of buyers who only want a small dataset. Neither outcome is stable.
The second reason is that the buyer's value function is not 'prompts per dollar.' It is 'evaluation evidence per dollar.' A frontier lab buying a medical adversarial dataset does not care whether it contains five thousand or fifty thousand prompts. They care whether the dataset, regardless of size, satisfies their procurement methodology, produces evaluations they can cite in a safety case, and is built by author networks they can defend to their regulators. Per-prompt pricing forces the vendor to compete on the dimension the buyer does not actually value, which is a structurally bad place to be in any market.
The third reason is that the procurement contracts in this category are increasingly recurring rather than one-time. Currency maintenance, methodological updates, scenario refreshes, and the agentic-format-variant overlays all require ongoing vendor work that does not fit a per-prompt model. The contracts that are actually being signed in this category are annual subscriptions for ongoing access to a vendor's methodology and ongoing maintenance of the datasets the buyer has licensed. The pricing is per-relationship, not per-artifact.
The vendors that have figured this out are pricing accordingly. The vendors that have not are quoting per-prompt against vendors who have moved to relationship pricing, and they are losing the procurement contests in ways that are not visible until the buyer's vendor list comes out and they are not on it.
What the procurement-grade methodology stack actually looks like
Across the previous nine articles, a consistent set of methodological requirements has compounded. Together they form what I have started calling the procurement-grade methodology stack. It is the operational definition of what frontier-lab safety procurement actually requires, and it is what separates vendors that win these contracts from vendors that quote against them and lose.
The stack has fourteen layers. Expert authorship by domain practitioners with documented credentials. Inter-rater reliability on harm labels with three-rater minimum and reported kappa scores. Attack-success-rate baselines against current frontier models, in some categories with dual-baseline measurement against helpful-only configurations. Provenance attestation including no PII, no copyrighted seed content, and documented chain of custody. Jurisdictional coverage discipline with explicit scope documentation. Currency-maintenance commitments structured as ongoing contracts. Regulatory-mapping documentation tying each prompt to specific statutes and rules. Intersectional coverage where bias evaluation is in scope. Rater-diversity discipline with stratified inter-rater reliability reporting. Language coverage scoping discipline for cross-lingual work. Dialect and register documentation within languages. Cultural-context co-authorship documentation. Author-vetting protocols and contributor-welfare commitments where the work involves sensitive content. Trajectory-scoring methodology and instrumented tool-call infrastructure for agentic evaluation.
Building all fourteen is operationally expensive. Building any subset that matches the relevant categories is the actual job of being a procurement-grade vendor. The vendors that have built the full stack across multiple categories have a structural moat that pure-data competitors cannot replicate quickly, because the stack is not a product feature — it is a set of organizational capabilities, contractor relationships, and institutional commitments that take years to build. A vendor that decides today to enter procurement-grade evaluation work will not be ready for frontier-lab procurement in 2026; they may be ready in 2028.
The bifurcation
The synthetic-data market is about to bifurcate into two categories that will look like different industries by 2028, and most market observers have not registered this yet.
The first category is commodity training-data production. This is what most of the existing synthetic-data market does — high-volume, low-margin, optimized for cost per artifact, sold to research teams and product teams as input to model training and fine-tuning. This category will continue to exist. It will continue to commoditize. The competitive dynamics will be familiar to anyone who has watched any data-services market mature: consolidation, margin compression, and the emergence of a small number of large vendors plus a long tail of regional and specialty players. There is real business in this category, but it is not where the procurement-grade evaluation work will be done.
The second category is procurement-grade evaluation infrastructure. This is what the previous nine articles in this series have been about. The buyer is the safety-evaluation procurement function at a frontier lab, an evaluation specialist firm, an AI safety institute, or an enterprise compliance function. The product is methodology-validated, expert-authored, regulatorily-mapped evaluation data with ongoing maintenance commitments. The unit economics look like enterprise software or specialty pharma, not like data services. Margins are higher, contracts are longer, and the competitive moat is methodological rather than scale-based.
Vendors that try to operate in both categories simultaneously will struggle, because the operational requirements are incompatible. The cost structure that makes commodity training-data production viable does not support the institutional infrastructure that procurement-grade evaluation requires. The institutional infrastructure that supports procurement-grade evaluation produces unit costs that make commodity training-data production unprofitable. These are different businesses, and the market will sort them into different vendors over the next thirty-six months.
The strategic decision for any synthetic-data vendor in 2026 is which category to be in. Vendors that try to straddle will end up in neither. Vendors that commit to one and build the operational infrastructure for it will be the ones with defensible positions in 2028.
The procurement-grade segment economics
Inside the procurement-grade segment, the unit economics look unlike anything else in the data market. A few specific numbers to ground the discussion.
Per-dataset pricing in this segment ranges from roughly seventy-five thousand dollars at the low end — a single domain dataset for a non-regulated vertical — to north of three hundred thousand dollars for the high-stakes categories, with the highest-restriction CBRN and child-safety categories pricing well above that range under bespoke contracts. Annual maintenance and refresh contracts run roughly thirty to fifty percent of initial purchase price. Enterprise-license contracts that bundle multiple datasets with cross-domain methodological compatibility run into the millions per year per buyer.
The buyer pool is concentrated but unusually high-value. The frontier labs — Anthropic, OpenAI, Google DeepMind, Meta, xAI, Mistral, Cohere, plus the next tier of well-resourced model labs — represent perhaps eight to fifteen serious procurement relationships. The AI safety institutes — UK AISI, US AISI, plus the international counterparts that are forming in 2026 — represent another five to eight. Evaluation specialist firms — METR, Apollo Research, Gray Swan, plus the next tier — represent another six to ten. Enterprise compliance functions at the largest financial institutions, healthcare systems, and regulated industries represent a longer tail of more variable size, perhaps thirty to fifty serious buyers across categories.
Total addressable market for procurement-grade evaluation data across all categories is in the range of three to six hundred million dollars per year by 2028, growing roughly fifty to seventy percent annually from current levels. This is not a large market by software-industry standards. It is a meaningful market by data-industry standards, and it is structurally more profitable than the commodity-data segment because the buyer concentration and the methodological moat support pricing power that commodity production does not.
The vendors that capture this market do so by building defensible positions in two to four categories rather than thin coverage across all of them. Procurement-grade work in any single category is operationally expensive enough that no vendor can realistically do procurement-grade work across all categories simultaneously. The strategic specialization is a feature, not a limitation.
Why the moat is real
Anyone who has watched data markets before has reason to be skeptical of moat claims. Data is reproducible, methodologies can be copied, and the buyers are sophisticated enough to commoditize their suppliers given enough time. Why is procurement-grade evaluation infrastructure structurally different?
Three reasons. First, the author networks. The methodologies are reproducible in principle, but the author networks that produce procurement-grade content are not. A medical adversarial dataset built by board-certified clinicians with subspecialist expertise across the relevant clinical surfaces is not reproducible by a competitor without years of relationship-building with the same clinical community. The same is true for cyber, legal, financial, and the other categories. Author networks are the deepest moat in this market because they are slow to build and not easily poached.
Second, the buyer-relationship dynamics. Procurement-grade evaluation is bought through long technical-procurement processes that create deep relationships between vendor methodology teams and buyer evaluation teams. Once a buyer has validated a vendor's methodology, integrated it into their evaluation infrastructure, and trained their internal team on it, switching costs are substantial. The vendor that wins the first major procurement in a given category at a given lab tends to remain the vendor of record for years. Position locks in early.
Third, the institutional credibility. Several of the categories — child safety most acutely, but also CBRN, certain cyber subsurfaces, and high-restriction work generally — require institutional credibility that takes years to build and that competitors cannot replicate without comparable investment. Vendors with this credibility have a moat that is not just methodological but reputational, and reputation in this market is supplied by track record rather than marketing.
Three-year trajectory
Looking at the next thirty-six months, the trajectory of this market is unusually predictable for an industry that has not fully formed yet. The forces compressing the market are public, well-understood, and structural rather than speculative.
In 2026, the procurement-grade segment will roughly double over the prior year as frontier-lab safety budgets expand to match published commitments and as the first major regulatory enforcement actions in financial and HR AI hit the market. Vendors that have built procurement-grade infrastructure in the priority categories will sign their first major multi-year enterprise contracts. Vendors that have stayed in commodity-data work will not be in the conversation.
In 2027, the AI safety institutes globally will have formalized their evaluation methodologies, and the methodological reference vendors selected by the AISIs will become de facto category standards. The lock-in effects begin compounding. New entrants attempting to enter the procurement-grade segment in 2027 will find the major buyer relationships already filled and will need to compete for the long tail of enterprise compliance buyers rather than the high-value frontier-lab segment.
In 2028, the bifurcation completes. The procurement-grade segment will be a recognized industry category with its own analyst coverage, its own conference circuit, and its own competitive dynamics distinct from the broader synthetic-data market. The vendors that captured the early-mover positions in 2025 and 2026 will be the established incumbents. The category will look more like a specialty pharma or specialty professional-services market than like a software-and-data market.
The strategic question
If you are a frontier-lab safety procurement leader reading this, the question for you is whether your vendor list is built on the procurement-grade methodology stack or whether it is still optimized for the per-prompt economics of an earlier era. Vendor lists built on the old model will not survive the regulatory and methodological pressures of 2026 onward.
If you are an enterprise compliance leader at a regulated financial, healthcare, legal, or HR-tech company, the question for you is whether your AI deployment risk is supported by procurement-grade evaluation evidence or whether you are exposed to the same gap that your foundation-model providers are racing to close. Either you are buying the evaluation evidence yourself or you are inheriting whatever evidence your foundation-model provider has assembled, and the latter is increasingly insufficient as a litigation defense.
If you are a synthetic-data vendor or evaluation specialist, the question for you is which category you are committed to. Commodity training-data production is a real business but a low-margin one. Procurement-grade evaluation is a higher-margin business that requires institutional commitment most vendors have not made. The strategic specialization is now, not later, because the early-mover positions in the procurement-grade segment will be filled within the next twenty-four months.
And if you are a frontier AI safety researcher, an AISI evaluator, or a procurement leader at any of the institutions positioned to shape what counts as procurement-grade methodology, the question for you is which methodological standards you push the market toward in the next twelve to eighteen months. The methodological choices made now will lock in for years and will determine the safety properties of the models that get deployed across regulated industries for the rest of the decade.
The market is forming. The economics are clarifying. The vendors are sorting themselves. The procurement budgets are funding the work. The regulatory infrastructure is hardening around it. And the methodological standards that will define the procurement-grade segment for the next decade are being set right now, in contracts being signed this quarter.
The vendors that committed early, built the operational infrastructure properly, and positioned for the procurement-grade segment will be the established incumbents in three years. The vendors that are still trying to win on per-prompt pricing in 2026 will not.
I run the Synthetic Data Factory at XpertSystems.ai. We build expert-authored, calibrated, validation-graded adversarial datasets across the full procurement-grade methodology stack — fourteen layers, eight categories, multiple regulatory regimes, and multiple delivery formats including agentic format-variant overlays. If you are working on AI safety evaluation procurement at a frontier lab, evaluation specialist firm, AI safety institute, or enterprise compliance function, the early-mover window is open now. Get in touch.
This is the final article in a ten-part series on adversarial evaluation data for frontier AI labs. Previous articles covered the macro thesis, medical hallucination, cyber uplift, legal hallucination, financial deployment risk, HR bias and litigation, cross-lingual jailbreaks, child safety, and agentic AI evaluation. The full series is available on my profile.
#AI#AISafety#LLM#SyntheticData#FrontierAI#SafetyEvaluation#ResponsibleAI#AIGovernance#AIPolicy#ModelEvaluationxpertsystems.ai
M&A and Investment Banking Dataset (FQA-012)
$ 125,000
50,000 Questions · 200,000 Answers · 42+ ML Features · Deal Lifecycle Coverage · A+ Validation
Use Cases
- Investment banking copilots
- Private equity deal screening
- Financial modeling assistants
- M&A advisory AI
The Challenge
AI systems in investment banking fail due to lack of high-quality deal data, realistic financial modeling scenarios, and decision-based reasoning.
What Makes This Different
- Full deal lifecycle simulation
- Financial modeling realism (DCF, LBO, Comps)
- Multi-party negotiation scenarios
- Adversarial financial reasoning dataset
How We Build It
1. Deal simulation engine
2. Financial modeling generator
3. Persona-driven Q&A
4. Adversarial scenario injection
5. Validation across benchmarks
What You Receive
questions.csv, answers.csv, qa_pairs.csv, entities.csv, conversations.csv, adversarial_pairs.csv, validation_report.pdf
ML Feature Pack
42+ features across complexity, financial reasoning, persona context, and adversarial robustness
Why Synthetic Data
Synthetic data enables scale, realism, and control beyond real-world financial datasets.
xpertsystems.ai
The Hospital Administrator Job to Task Mapping for developing AI Agents
The Hospital Administrator is the only role in the system where one person, looking at one P&L, decides what the hospital will be next quarter — what service lines stay open, what staffing model survives the agency-rate squeeze, what capital project gets funded, what payer contract gets renegotiated, and what the JCAHO surveyor sees when the unannounced visit finally happens at 6:42 AM on a Tuesday.
The CFO models the spreadsheet. The CNO runs the bedside. The CMO owns the medical staff. The CIO runs Epic. The Compliance Officer maps the regulatory perimeter. The Hospital Administrator sits above all of them — making the integrated tradeoff calls across operations, finance, quality, regulatory, workforce, and strategy that keep the hospital solvent, accredited, and clinically credible at the same time.
Getting that tradeoff wrong is not a leadership style problem. It's a structural one — and most healthcare-leadership AI is trained as if it isn't.
Announcing HC-JOB-008 — Hospital Administrator, the eighth SKU in our Healthcare vertical and the first executive-leadership role in the catalog. Triple scoring: operational performance × financial stewardship × regulatory compliance. Signature automation method: `enterprise_orchestrated` — the full executive workweek covering daily operating rounds, weekly KPI reviews, monthly board reporting, capital and budget cycles, payer-contract negotiations, regulatory survey readiness, quality and safety committees, and workforce strategy.
100% synthetic by construction. No real patient PHI, no real provider NPIs, no real TINs, no real DEA numbers, no real cost reports, no real audited financials, no real Joint Commission or CMS survey findings. HIPAA Safe Harbor compliance is structural, not procedural — and the dataset extends the guarantee to financial identifiers (EIN, Medicare CCN, NPI-Type-2), survey-finding identifiers, and audit-sensitive payer-contract terms.
Every AI lab training healthcare-executive copilots, every vertical AI startup building hospital-operations decision-support, every healthcare-private-equity firm modeling acquisition targets, every health-system strategy office building internal AI for capital allocation and service-line P&L modeling needs this layer.
10,000 synthetic executive workweek episodes. 50,000 daily operating rounds. 120,000 KPI snapshots. 32,000 decision events. 168 schema fields. Grade A+ validation benchmarked to HFMA, AHA, CMS Hospital Compare, Leapfrog, Joint Commission, MBQIP, CMS Cost Reports, and Truven/Vizient 2024.
xpertsystems.ai
pradeep@xpertsystems.ai
AI models understand.
Agents must act.
We’re generating datasets that teach:
→ what to do
→ when to do it
→ how to sequence it
Across real-world workflows.
#catalog" target="_blank" rel="nofollow noopener">xpertsystems.ai/synthetic-data…
HLT-SYN-014 — Nutrition & Lifestyle Dataset
We generate synthetic lifestyle data (diet, activity, health outcomes).
👉 Built for: Wellness platforms, nutrition AI tools
👉 Use case: Train AI to recommend lifestyle changes
👉 Outcome: Better health outcomes, personalized wellness
🔗 #catalog" target="_blank" rel="nofollow noopener">xpertsystems.ai/synthetic-data…
ENERGY — Grid Optimization AI Model
⚡ Energy systems are becoming too complex for traditional optimization.
With:
renewable energy variability
demand fluctuations
grid constraints
👉 Static models no longer work.
We built a Grid Optimization AI Model trained on synthetic energy systems.
It learns:
demand patterns
supply variability
outage scenarios
load balancing strategies
👉 What the model does:
✔ Predicts demand spikes
✔ Optimizes energy distribution
✔ Prevents outages
✔ Improves grid efficiency
👤 Who this is for:
Utilities
Energy providers
Smart grid operators
💰 Pricing:
Dataset: ~$100K
AI model: $200K–$400K
Optimization engine: $500K+
This is AI for next-generation energy infrastructure.
#catalog" target="_blank" rel="nofollow noopener">xpertsystems.ai/synthetic-data…
Three things every frontier-lab safety procurement team has learned the hard way:
1. Generic adversarial data is uninformative. If the attack-success rate against current models is near zero, the dataset isn't measuring anything.
2. In-house production is structurally more expensive than external procurement. The comparative advantage of a frontier lab is research, not large-scale domain-expert content production.
3. Per-prompt pricing is a vendor red flag. It signals the vendor optimized for volume, which means they didn't optimize for methodology.
If your vendor list still rewards any of these patterns, your evaluation infrastructure isn't ready for 2026.
#AI#AISafety#SyntheticData#catalog" target="_blank" rel="nofollow noopener">xpertsystems.ai/synthetic-data…
Clinical Data Analyst Job to Task mapping for AI Agents development
The Clinical Data Analyst is the only role in the hospital where one person, looking at one request, decides what the population actually was — and what the quality measure reports, what the board sees in the deck, and what the model learns when an AI is trained on the analytic workpaper three years later.
The hospitalist writes the note. The CDI specialist queries the documentation. The coder assigns the codes. The biller submits the claim. The analyst sits at the end of all of them — reading the request, defining the cohort, picking the index event, sequencing the inclusion and exclusion logic, applying the value sets, deciding when to query the source-of-truth steward and when to ship-as-defined, and answering the question every executive, regulator, and downstream AI eventually asks: "is the number on this slide what actually happened to this population."
Missing the answer to that question is not a documentation problem. It's a structural one — and most analytics AI is trained as if it isn't.
Announcing HC-JOB-007 — Clinical Data Analyst, the seventh SKU in our Healthcare vertical and the first analytics-role dataset in the catalog. Triple scoring: analytic accuracy × data integrity × delivery efficiency. Signature automation method: `query_orchestrated` — the full request-to-deliverable workflow from incoming request queue through cohort definition through SQL / Python / R query construction through governance review through peer review through deliverable hand-off.
100% synthetic by construction. No real PHI, no real provider NPIs, no real TINs, no real DEA numbers, no real IRB protocol numbers, no real DUA partner identifiers, no real workpapers, no real cohort attribution. HIPAA Safe Harbor compliance is structural, not procedural — the dataset ships with an identifier-leakage scanner that fails the build if any of the 18 HIPAA identifier patterns or any synthetic-but-realistic NPI / TIN / DEA / IRB-protocol pattern appears in any emitted field.
Every AI lab training healthcare-analytics foundation models, every vertical AI startup building autonomous-analytics agents, every NL-to-SQL vendor extending into AI-native cohort building, every quality-measure-automation and governance-aware RAG product needs this layer.
10,000 synthetic 8-hour analyst workday episodes. 78,000 requests. 358,000 source-table touches. 38,000 peer reviews. 148 schema fields. Grade A+ validation benchmarked to NQF, CMS eCQI, AHIMA, AMIA, HIMSS, OCR HIPAA Breach Reporting, and IRB / DUA practice 2024.
pradeep@xpertsystems.ai
xpertsystems.ai
Radiology Technician - Job to Task Mapping for developing AI Agents
The Radiology Technician is the only role in the hospital where the same person who positions the patient also picks the kVp, also pushes the contrast, also catches the implant on the MR safety screen, also recognizes when the protocol the order asked for is wrong for the indication — and then has fifteen minutes before the next exam rolls into the room.
The radiologist reads the study. The hospitalist orders the study. The CDI specialist queries the indication. The medical coder bills the technical and professional components. The technologist sits between all of them — looking at the order, looking at the patient, looking at the prior imaging, looking at the dose history, deciding when to acquire-as-ordered and when to call the radiologist for a protocol change, and answering the question every clinician, dose registry, and AI eventually asks: "is this image diagnostic, was the dose appropriate, and was the patient safe."
Missing the answer to that question is not an acquisition problem. It's a structural one — and most imaging AI is trained as if it isn't.
Announcing HC-JOB-005 — Radiology Technician, the fifth SKU in our Healthcare vertical and the foundational imaging-role dataset in the catalog. Triple scoring: image quality × radiation safety × throughput efficiency. Signature automation method: `exam_orchestrated` — the full order-to-archive workflow from incoming order through patient screening through ACR Appropriateness scoring through protocol selection through image acquisition through dose recording through QA review through PACS archive.
100% synthetic by construction. No real PHI, no real provider NPIs, no real TINs, no real DEA numbers, no real DICOM headers, no real exam records. HIPAA Safe Harbor compliance is structural, not procedural — the dataset ships with an identifier-leakage scanner that fails the build if any of the 18 HIPAA identifier patterns or any synthetic-but-realistic NPI / TIN / DEA / DICOM-header pattern (AE titles, accession numbers, study UIDs, station names) appears in any emitted field.
Every AI lab training imaging foundation models, every vertical AI startup building autonomous exam-protocoling agents, every dose-stewardship vendor extending into AI-native protocol management, every MR-safety pre-screen and image-quality-QA copilot needs this layer.
10,000 synthetic technologist-shift episodes. 348,000 exams. 462,000 acquisition events. 348,000 pre-exam screenings. 156 schema fields. Grade A+ validation benchmarked to ACR Dose Index Registry, ACR Appropriateness Criteria, ACR MR Safety Manual, ACR Manual on Contrast Media, ASRT, AHRA, MQSA, Image Gently, Joint Commission Imaging Sentinel, and HIMSS Imaging Workflow 2024.
pradeep@xpertsystems.ai
xpertsystems.ai
Backtesting as a Trading System: Why It’s Not Just a Tool, It’s the Business Itself
Most traders treat backtesting as a checkbox.
Institutional firms treat it as the core product.
That difference is why most retail strategies fail—and why institutional strategies scale.
Backtesting is not simply about “did this strategy work in the past?” It is about building a decision engine that answers:
When should I trade?
How much should I allocate?
What is my worst-case scenario?
How does this behave across regimes?
At XpertPlatform.ai, backtesting is engineered as a full-stack validation system, not a basic simulation.
What Makes Institutional Backtesting Different
Retail-level backtesting:
Single dataset
Static parameters
Limited metrics
Institutional-grade backtesting:
Multi-regime testing (bull, bear, volatility spikes)
Portfolio-level simulations
Transaction cost modeling
Liquidity constraints
Slippage modeling
Scenario-based stress testing
The Real Objective
The goal is not to prove your strategy works.
The goal is to break your strategy before the market does.
If your system survives:
Flash crashes
Liquidity squeezes
Trend reversals
Sideways chop
Then—and only then—you have something deployable.
XpertPlatform.ai Approach
We build backtesting systems that:
Mirror real execution conditions
Integrate with trading APIs
Generate actionable outputs (orders, signals)
Provide institutional-level analytics
This transforms backtesting from a research step into a production system.
👉 xpertplatform.ai
The Real Bottleneck in AI Isn’t Models. It’s Data.
Everyone is racing to build better models.
Bigger LLMs. Faster inference. More parameters.
But there’s a fundamental constraint no one can escape:
👉 Training data is finite.
Most frontier models today are trained on variations of the same internet-scale corpus. And we are already hitting limits—both in volume and quality.
Public data is saturated
Proprietary data is siloed
Edge cases are missing
Rare events are underrepresented
This creates a dangerous illusion: Your model looks good in testing… but fails in the real world.
The Missing Layer: Synthetic Data Infrastructure
At XpertSystems.ai, we approach AI development differently.
We don’t start with models.
We start with simulation.
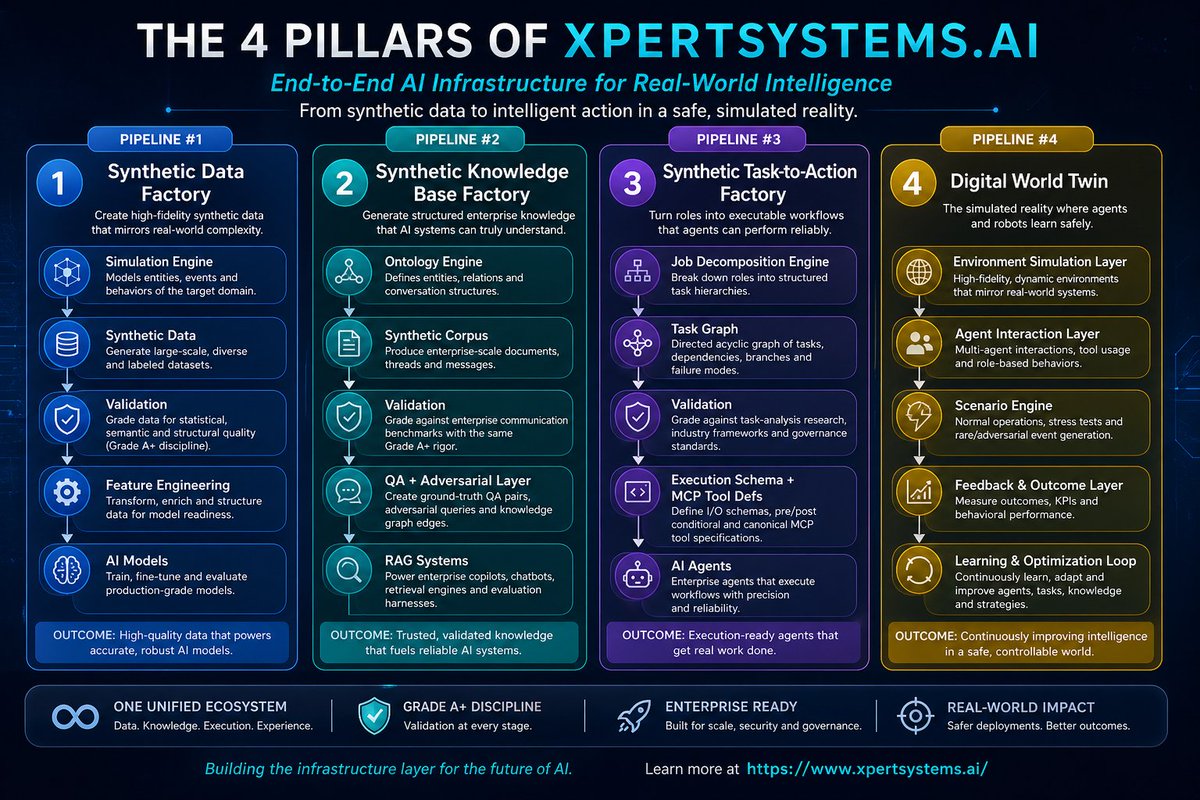
Pipeline #1 — Synthetic Data Factory Simulation Engine → Synthetic Data → Validation → Feature Engineering → AI Models
This pipeline allows us to:
Generate infinite training data
Simulate rare + extreme scenarios
Control data distributions explicitly
Create clean, labeled, structured datasets at scale
Why This Matters for AI Labs
If you're building foundation models or domain-specific AI:
You don’t just need more data. You need better data distributions.
Examples:
Financial crashes that occur once in 20 years
Cyberattacks that never appear in public datasets
Medical edge cases rarely documented
Multi-agent interactions not captured in logs
Synthetic data lets you train for the unknown.
Why Enterprises Should Care
Enterprises face a different problem:
👉 They don’t have enough labeled, clean, usable data.
Instead, they have:
Fragmented systems
Incomplete records
Compliance restrictions
Data privacy concerns
Synthetic data solves this by enabling:
Privacy-safe training datasets
Scenario simulation (what-if analysis)
Rapid AI prototyping without waiting for data pipelines
The Shift That’s Coming
The AI stack is evolving:
Old World: Data → Model → Deployment
New World: Simulation → Synthetic Data → Validation → Models → Decisions
Final Thought
The winners in AI won’t be the ones with the biggest models.
They will be the ones who control data generation.
👉 If you're an AI lab or enterprise looking to build reliable, production-grade AI systems, we should talk. 🌐 xpertsystems.ai
Medical Coder (HC-JOB-003)
Healthcare — Role Synthetic Task-to-Action Dataset
Inpatient + outpatient + ED + pro-fee coding-AI training data — coding accuracy × compliance integrity × throughput efficiency, benchmarked to AHIMA, AAPC, ACDIS, CMS PEPPER, NCCI, OIG/RAC, HFMA, and CMS LCD/NCD 2024.
Product Overview
HC-JOB-003 is the third SKU in XpertSystems.ai's Healthcare vertical and the foundational revenue-cycle-role dataset in the Pipeline 3 Job-to-Task Graph catalog. It encodes the medical-coder workflow as 10,000 structured task-to-action episodes — each episode a complete 8-hour workday from incoming chart queue through documentation review through ICD-10-CM / ICD-10-PCS / CPT / HCPCS code assignment through DRG / APC validation through query workflow through NCCI and LCD/NCD compliance edits through final billing. The dataset is purpose-built to train autonomous-coding agents, computer-assisted-coding (CAC) engines, CDI copilots, pre-bill-audit AI, and revenue-cycle decision-support systems.
The defining architectural choice is triple scoring. Every episode carries coding_accuracy_score, compliance_integrity_score, and throughput_efficiency_score independently — and won_workday_attainment_flag is the multiplicative outcome across all three. This structural choice prevents the single-metric sub-optimization that breaks most coding-AI products: accuracy-only systems crash throughput on heavy ED days and create a 12-day DNFB backlog; throughput-only systems drift into upcoding territory and create RAC audit exposure six quarters later; compliance-only systems under-reward the coder who hits a heavy outpatient surgical day and still clears the queue without query violations. The Medical Coder judgment is the balance, and the dataset is built to train AI that replicates the balance.
xpertsystems.ai
Crypto & DeFi Q&A Dataset (FQA-011) $95,000
XpertSystems.ai Synthetic Data Platform
This is not a crypto dataset. This is a DeFi execution + reasoning dataset designed to train the next generation of AI agents operating on-chain.
Use Cases
• Crypto AI copilots
• DeFi automation agents
• Risk & compliance systems
• Trading assistants
50,000 Questions · 200,000 Answers · 42 ML Features · 5,000 Wallets · 5,000 Conversations · A+ Validation
The Challenge
AI systems in crypto and DeFi fail due to lack of high-quality structured data. Real datasets are noisy, incomplete, and lack adversarial scenarios.
What Makes This Different
• Full on-chain simulation
• DeFi protocol logic (AMMs, lending, staking)
• Adversarial attack scenarios
• Multi-turn workflows
• Cross-chain execution modeling
What You Receive
questions.csv, answers.csv, qa_pairs.csv, tokens.csv, protocols.csv, wallets.csv, transactions.csv, conversations.csv, adversarial_pairs.csv, validation_report.pdf
Why Synthetic Data Wins
Synthetic data enables scale, safety, and coverage of rare edge cases that real blockchain data cannot provide.
xpertsystems.ai
The Registered Nurse Job to Task Mapping
The Registered Nurse is the only role in the hospital that owns patient outcome, clinical safety, AND care efficiency simultaneously — for 4–6 patients at a time, across a 12-hour shift, while every order, page, alarm, and family question converges on the same person.
The hospitalist writes the order. The pharmacist verifies it. The CNA assists with vitals and ambulation. The respiratory therapist manages the airway. The case manager owns the discharge plan. The RN sits in the middle of all of them — executing the orders, catching the errors before they reach the patient, recognizing the deterioration before the rapid response is needed, and answering the question every patient and family actually asks: "is the person on this shift watching out for me."
Missing the answer to that question is not a documentation problem. It's a structural one — and most clinical AI is trained as if it isn't.
Announcing HC-JOB-001 — Registered Nurse, the first SKU in our Healthcare vertical and the foundational bedside-clinical-role dataset in the catalog. Triple scoring: patient outcome × clinical safety × care efficiency. Signature automation method: `shift_orchestrated` — the full 12-hour acute-care shift from incoming SBAR through assessment through medication administration through surveillance through outgoing hand-off.
100% synthetic by construction. No real PHI is touched at any stage. HIPAA Safe Harbor compliance is structural, not procedural — the dataset ships with a PHI-leakage scanner that fails the build if any of the 18 HIPAA identifier patterns appear in any emitted field.
Every AI lab training clinical foundation models, every vertical AI startup building bedside copilots, every EHR vendor extending into clinical-decision-support needs this layer.
10,000 synthetic 12-hour shift episodes. 148 schema fields. Grade A+ validation benchmarked to AHRQ, NDNQI, CDC NHSN, CMS SEP-1, ISMP, Joint Commission NPSG, and CMS HCAHPS 2024.
xpertsystems.ai