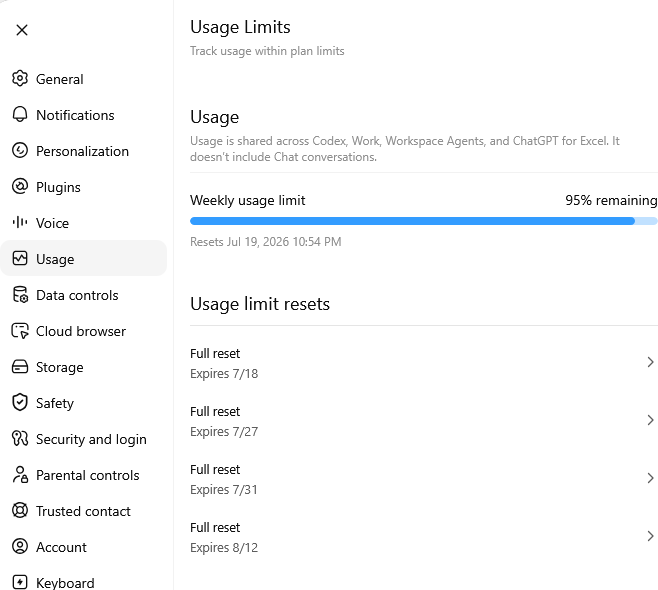
Sabitlenmiş Tweet

Evolution tends to move at its own pace, but it's always in motion.
No one can stop the future, even someone determined to bring it about.
Pantheon Season 2 Episode 7.
Criminally underrated show.
English
Lincoln 🇿🇦
40.1K posts

@Presidentlin
History never ends. Retired SA/UK bank swe. Whale watcher 🐋 Working on an SEO thing.


Wearing noice cancelling masks to talk to Claude is crazy





we're open-sourcing again on @huggingface! this time it's a VLM 🤗 MOSS-VL-Realtime is designed for real-time visual understanding: >11B | 256k context Apache-2.0 license > remain silent when more evidence is needed!! > can ask questions at any point during a video stream. > watching while generating a response > revise or interrupt its own response when the situation changes > chinese & english understanding pls try and give us feedback👇



Lincoln is happy. Fingers crossed we get another banked reset before 18 July. I played the house and won. I could have double won if I used my previous reset instead of letting it expire. Ah well. You have no idea how useful having the limits on the website is.