Stereo depth is highly useful for robots. Meet WAFT-Stereo: #1 on ETH3D (BP-0.5), Middlebury (RMSE), and KITTI (all metrics); 61% less zero-shot ETH3D BP-0.5 error; 1.8-6.7x faster than prior SOTA. Key idea: classify disparity into bins, then iterative high-res warping.🧵1/2
Meet WAFT (Warping-Alone Field Transforms), our new optical-flow estimator. #1 on public benchmarks (Sintel & Spring), 1.3-4.1x faster than leading methods, and 2x lower memory. Key idea: replace cost volumes with high-res feature-space warping. Code and paper:👇
We tested 6 intrinsics prediction methods on InFlux. When projecting 3D points, even the best methods produced projections hundreds of pixels off.
Have a better method? Try our benchmark👇
🌐 Website: influx.cs.princeton.edu
📄 Paper: arxiv.org/abs/2510.23589
💻 Github: github.com/princeton-vl/I…
To construct this mapping, we use Hollywood-grade lenses that provide reliable lens metadata. We calibrate the lenses at many settings using multi-scale board and drone targets, and extract intrinsics via Kalibr, a toolkit we modified for improved robustness and accuracy. 🧵4/5
Estimating camera intrinsics from video is key to 3D reconstruction, but most methods assume they’re fixed per video. What if the camera keeps zooming and refocusing?
Meet InFlux, the first benchmark with per-frame ground truth for videos with dynamic intrinsics. 🧵1/5
Major update to Infinigen Articulated (formerly Infinigen-Sim)! You can now generate articulated 3D objects in 18 categories, simulation ready with physics parameters and improved efficiency. Also available: 20k pre-generated objects. Download links below👇
Princeton365 opens new frontiers for Novel View Synthesis, providing 360 scans of reflective and transparent scenes with precise camera poses—data that were previously unavailable, as conventional tools like COLMAP fail to recover accurate poses in such conditions. (3/4)
🧵 Working on SLAM or Novel View Synthesis but need a new challenge? Try Princeton365, our new video benchmark built to push your model to the limit. It features reflective and transparent scenes, wild camera motion, night-time shots, flashing lights, video within video, and more, all with millimeter-accurate ground truth camera pose! (1/4)
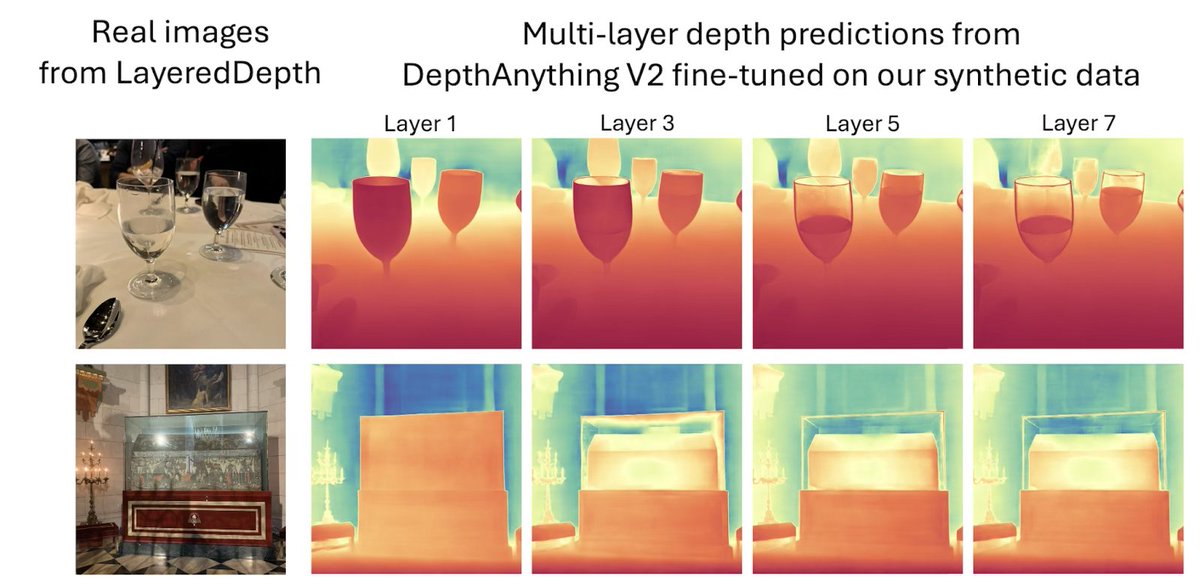
Depth models struggle with transparent surfaces. They may see a glass window, or what is behind it, but not both. Worse, they are often confused and inconsistent. How do we make them see the glass and see through it? Check out our ICCV 2025 paper “Seeing and Seeing Through the Glass: Real and Synthetic Data for Multi-Layer Depth Estimation”. (1/5)