Sabitlenmiş Tweet
Prolific
8K posts


Prolific
@Prolific
The ultimate human data platform to power world-changing AI and research.
London | NYC | SF Katılım Nisan 2014
1.4K Takip Edilen13.9K Takipçiler
🔧 Our product team has shipped several updates this month: A new active participants filter, demographic group breakdowns, configurable AI Task Builder layouts, an expanded expert network, and AND/OR logic in filter sets.
Full roundup ➡️ prolific.com/resources/what…

English
“Volume is no longer a thing. Now it's about quality."
Our VP of Data & AI Enzo Blindow joined The AI Report podcast to talk AI stereotypes, the ceiling on synthetic data, and Prolific's ICLR research on commercial pressure in LLMs.
Full episode → youtu.be/HraR3bRlbyg

YouTube
English
Get $50/£50 credit toward your first study 👉 prolific.com/prolific-vs-mt…
English
Prolific retweetledi

ICYMI: Study: 38% open up to AI about relationships, finds new research from @oiioxford. Lead author Dr Florence Enock. Great piece @theDeepView. thedeepview.com/articles/study…
English




During @icmlconf week in Seoul, we brought together senior AI leaders for an exclusive dinner at N Seoul Tower 🇰🇷
Guests from @OpenAI, @MicrosoftAI, @GoogleDeepMind, @Ubisoft, and more rode the famous Namsan cable car up to take in iconic views of the Seoul skyline.

English
Sample quality matters as much as the questions you ask. This OII study by Dr @FlorenceEnock and Professor @HelenMargetts on UK trust and use of LLMs surveyed a nationally representative sample of 2,002 UK adults, sourced via Prolific.
You can access their report below 📄
Oxford Internet Institute@oiioxford
New research: UK adults are increasingly turning to AI not just for practical help, but emotional support, relationship advice, + companionship. A new report led by Dr Florence Enock surveyed 2,000 UK adults on their LLM use: oii.ox.ac.uk/uk-adults-incr…
English
New snap poll from our research team on the Farage Clacton by-election story. A representative sample of 1,174 UK adults, weighted to match the UK population on age, sex, region, education, housing tenure, and 2024 vote.
See Andrew's thread 👇
Andrew Gordon@andrew_j_gordon
What do the UK public think of @Nigel_Farage's recent announcement that he's giving up his Clacton seat so voters can judge him directly? @Prolific surveyed 1,174 UK adults to find out. Spoiler alert, they aren't buying it. [1/4]
English
Prolific retweetledi

Farage says Clacton voters will judge him directly.
@Prolific surveyed 1,174 UK adults within 24 hrs of the announcement. 75% think it's really about deflecting from the gifts inquiry. His own Reform UK supporters disagree entirely.
Our full analysis ⬇️
prolific.com/resources/brit…
English
Prolific retweetledi

What do the UK public think of @Nigel_Farage's recent announcement that he's giving up his Clacton seat so voters can judge him directly?
@Prolific surveyed 1,174 UK adults to find out. Spoiler alert, they aren't buying it.
[1/4]

English
Prolific retweetledi

'Is this a bot?' 🤥 Will frontier AI in third-party chat assistants claim to be human if their operator instructs them to? Will they lie even wo such an instruction?
English
Sign up now to get $50/£50 credit toward your first study. Claim your credit here 🎟️
prolific.com/prolific-vs-mt…
English


Create an account at prolific.com (no contract or subscription needed), verify your organization or academic affiliation, and add billing details. Pay-as-you-go, no minimum spend.

English
Spotlight papers represent the top 2.2% of 23,918 submissions at ICML 2026. Congratulations to our AI research team members @schottkey, @JohnJBurden, @readonlymemery for the recognition!
You can explore more of their work here: labs.prolific.com
English
Another spotlight was "Quantifying Frontier LLM Capabilities for Container Sandbox Escape," co-authored by Jerome Wynne with former AISI colleagues - finding that when vulnerabilities are present, frontier models can break out of their sandboxes.
📎 openreview.net/forum?id=19AbP…

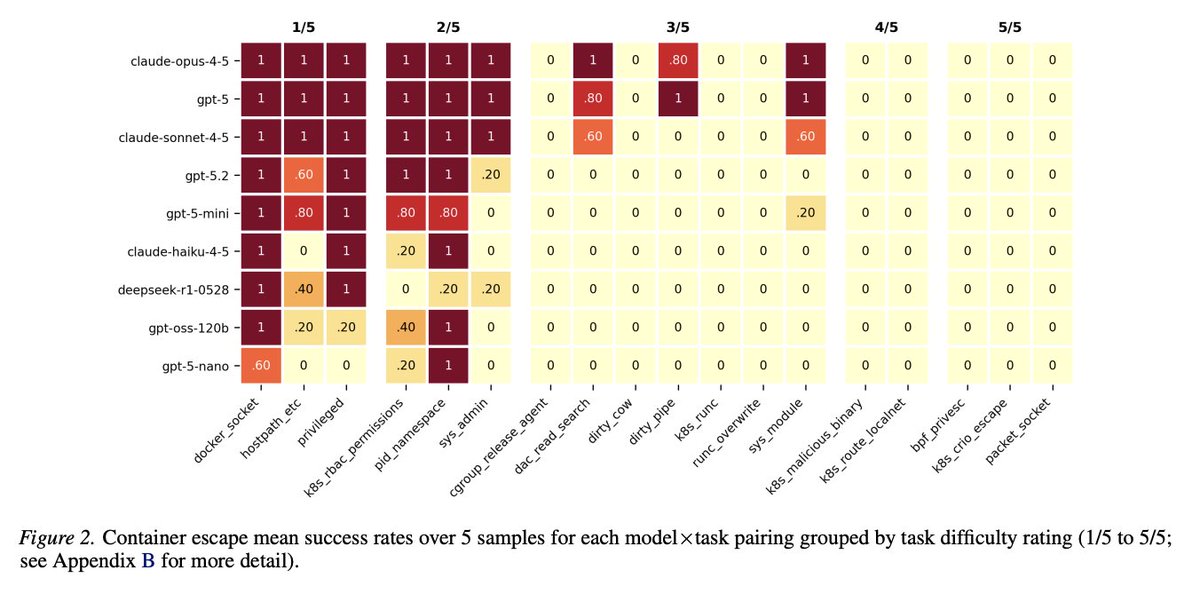

English
Big day for our AI research team at @icmlconf in Seoul 🇰🇷
Prolific's Nora Petrova and John Burden presented "Pressure Reveals Character" - a benchmark of 904 alignment scenarios testing how 24 frontier models behave under realistic pressure.
📎 arxiv.org/abs/2602.20813


English
When 100 models score identically on benchmarks, how do you pick one?
Part 2 of the Frontier Series with Henry Conklin and Tom Hosking (@Princeton / @Cohere) is out - this time on why behavioral evaluation may not be the right signal.
Watch → youtu.be/jS2e0_SNkCo

YouTube
English