
Purplefin Neptuna
568 posts

Purplefin Neptuna
@PurplefinNep
Game Programmer Making 2D Games on https://t.co/etQ1K1rfu0 Godot, and Unity if needed
Indonesia Katılım Aralık 2015
88 Takip Edilen45 Takipçiler

🚀 We just launched the open-source KV Cache Size Calculator by KVCache.ai!
Calculate KV cache size for mainstream LLMs with flexible precision settings and detailed breakdowns.
Supports DeepSeek, GLM, Kimi, Qwen3 and MiniMax.
Try it now: kvcache.ai/tools/kv-cache…

English


animaでiLECOとかADDifTの学習出来るようにしたsd-scriptsフォークです。
github.com/tukisuwa/sd-sc…
日本語
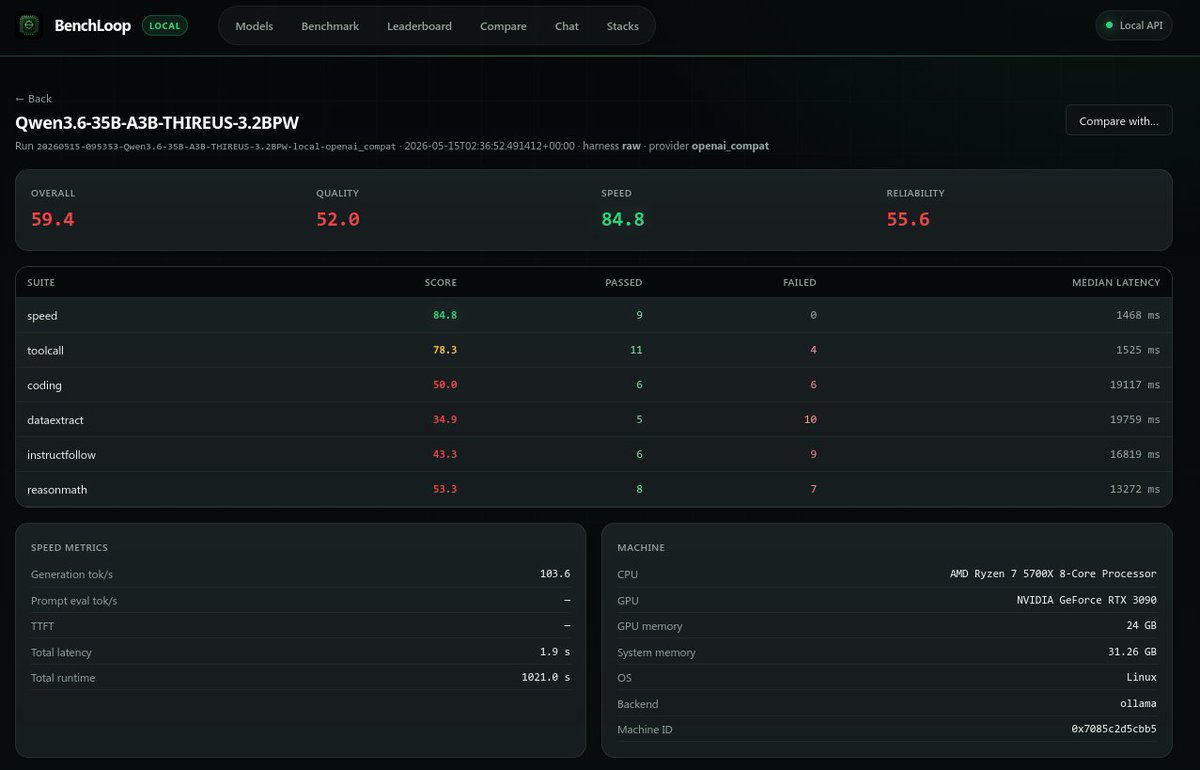
Capping reasoning budget maybe made it worse, I might need to rerun this.
See this leaderboard to compare how fucked up your AI setup is🤣:
bench-loop.com/leaderboard
English

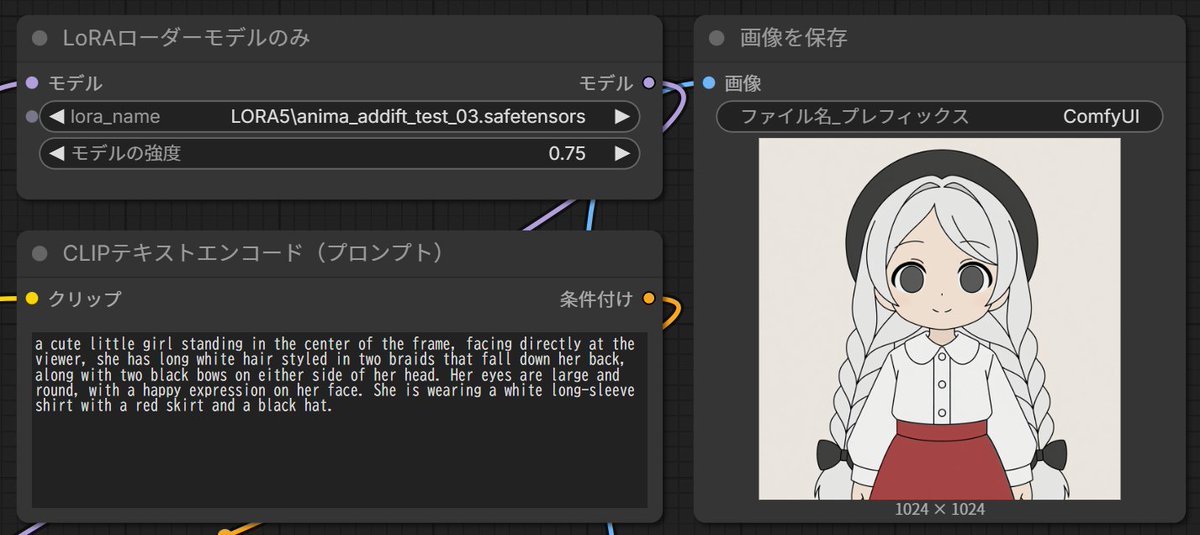
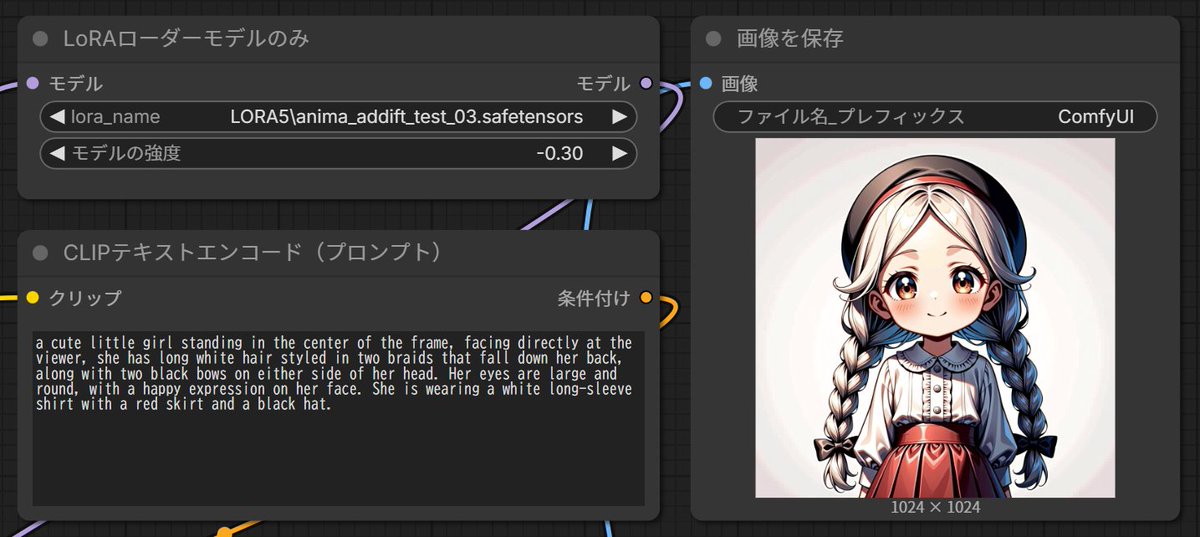
Sayang pas nyoba di pc gw, malah offset semua hasilnya. Kyknya Q4 terlalu bego buat ginian 😔
ModelScope@ModelScope2022
Big leap in Object Detection with Qwen3.6-35B-A3B! 🚀We are excited to showcase the new "Instruction-Oriented Object Detection" capability on ModelScope. Demo 👉modelscope.ai/studios/Qwen/O… 📈 Performance: ODinW score jumped from 42.6 (Qwen3.5) to 50.8! 🧠 Beyond standard detection, Qwen3.6 leverages LLM reasoning to: 1️⃣ Identify fine-grained objects, such as PCB components and reference designators. 2️⃣ Detect small and occluded cars in aerial-view parking lots. 3️⃣ Handle dense scenes multi-scale objects. 🤖 Download model: modelscope.ai/models/Qwen/Qw… #Qwen36 #ObjectDetection #ComputerVision #OpenSource
Indonesia

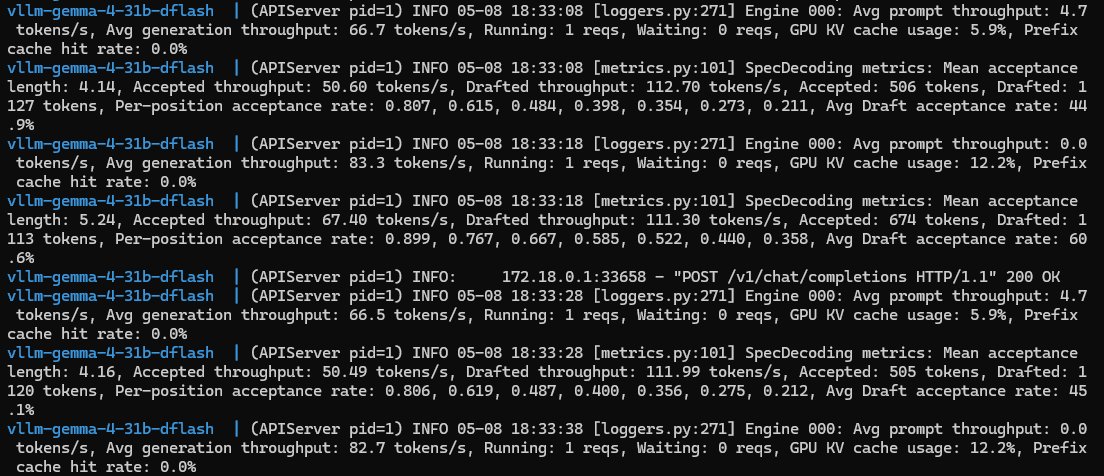
Spent today getting DFlash running on dual 3090 + Gemma 4 31B
From the very beginning I took a wrong turn
- AWQ 8bit + DFlash = 0.4% acceptance, drafter was trained on a different quant
- pip install PR branch → trashed my venv
What worked:
@malikwas1f club 3090 recipe, pre patched docker container. Just docker compose up
Results:
- 86 tok/s, accept rate 61.6%
+33% over my MTP result (52 tok/s)
Couldn't hit those 168 tok/s (hello PCIe x4 on the second card)
Gonna try to get better numbers tomorrow
English
@ajaeger74 @sudoingX Dunno why arch linux jumps to 16. Cachyos only provide 14, but i think that's enough
English

@sudoingX Cloning and compiling the most popular llama forks as well as upstream was never as easy and comfortable as now.
Just make sure to have gcc between version 12 and 15, nvcc doesn't like the latest version 16.
English

anyone interested in or getting started with local ai personal inference, pay attention. start with the right practice. compile llama.cpp from source.
i know lm studio and ollama exist. they're great onramps. but they're mostly wrappers around llama.cpp with abstraction layers that hide the flags you actually need to tune.
what compiling once gets you:
> the best inference engine for personal use, full stop
> latest features the day they merge (vulkan flash attention dp4a, kv cache quant, fa toggles)
> exact gpu arch optimization (sm_120 for 5090, sm_89 for 4090, sm_86 for 3090)
> direct flag control
> openai-compatible llama-server api ready out of the box
the build (3-5 minutes on a modern cpu):
git clone github.com/ggerganov/llam…
cd llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=120
cmake --build build --config Release -j
(replace 120 with 86 for 3090, 89 for 4090, 80 for A100. for AMD GPUs swap GGML_CUDA for GGML_VULKAN.)
when to NOT use llama.cpp:
> multi-gpu batch serving at scale = vllm
> production async high-throughput = vllm or sglang
> apple silicon = mlx is faster
for single-gpu personal inference + agentic workflows + benchmarking: llama.cpp from source. every time.
English
@sudoingX Did you run this with thinking enabled/preserved?
I don't trust Qwen3.6 thinking mode with low-bit model & KV quant. 35B can waste 100k tokens just thinking, so I'm worried 27B will waste more time thinking, since it's much slower.
English
carnice-v2 is up now on my rog 5090 mobile 24gb tier, llama-server holding 21gb at 262k context, hermes agent on the other pane, nvtop watching the line go up. hell yeah tonight is gonna be great.
if you are running with me on 24gb vram, here is the exact stack:
./llama-server -m carnice-v2-27b-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 --port 8080 --host 0.0.0.0
3090, 4090, 5090 mobile, w7900, anything 24gb, copy the flags and share what you got. if you have not run carnice on your card yet anon, what is stopping you?

Sudo su@sudoingX
a question keeps hitting my mind. does same base SFT for harness beat vanilla qwen 3.6-27b on hermes agent agentic loops? to find out i loaded carnice-v2 by kaios, qwen 3.6-27b tuned specifically on hermes agent traces. trinity 3-stage merged bf16 SFT. i have been benchmarking vanilla 3.6 on agentic tasks for weeks so i would catch any meaningful improvement on a head to head. been wanting to run this exact lineup. carnice on the same hardware, same context, same flags i run vanilla on. let's see how it performs against the base. hardware: rog scar 5090 mobile, 24gb vram tier. every flag i use reflects directly to your 3090 desktop 24gb territory, so if you are running a 3090 you can copy the same setup and follow along. results coming next anon.
English
@0xSero I have Nvidia, but small vram. can only run gguf on llama.cpp
English


anima-lllite-any-test-like-3 すごい便利……色つき画像でも参照できるし、ポーズ維持しながらもバリエーション出してくれる(node整理せんとな……)
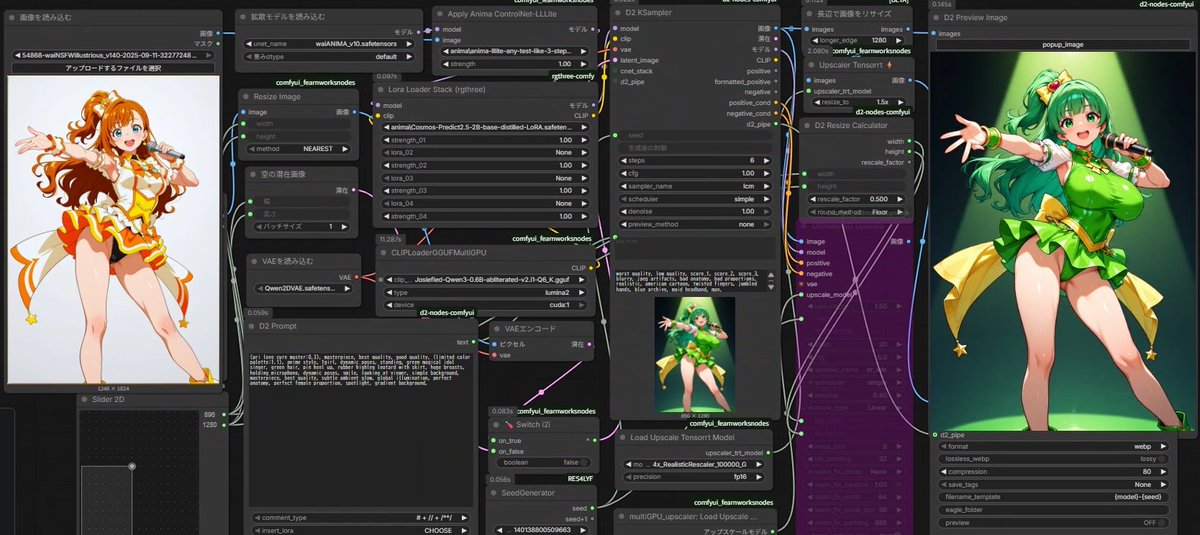
日本語
Kebacanya "kid" sama "people" wkwkwk
Benjamin Marie@bnjmn_marie
Kld and ppl are good for quick diagnostics and debugging. Not for evaluation.
Indonesia
@nd_haryo gw kemaren mau komen gitu juga tapi nggak enakan
Indonesia

I’ve played enough OpenTTD to finally understand this
Jakarta City Of Galian@LetitFlowBeib
@AndCav4 Tapi kecelakaan ini penyebabnya ya harusnya bukan dari taxi. Kalopun itu bukan taxi dan diganti pohon tumbang. Sinyal kereta tersebut ga akan berubah. Menurut Masini Bekasi sinyal hijau. Padahal seharusnya Bekasi Kuning karena ada kereta di stasiun bektim
English
I think Qwen3.6 35B A3B is the best local model that can fit in my 3090 and also fast.
But wait, let me check if Qwen3.6 35B A3B is the fastest.
Right, Qwen3.6 35B A3B is the fastest and fit in my 3090.
But wait, let me check if Qwen3.6 35B A3B fit in my GPU.
Yes, Qwen3.6 35B A3B
English

Wkwkwk, orang2 yg asal pindah ke linux pada protes rpcs3 ga ada di appstore mereka.
Mending balik aja ke Microslop kalo apa2 dari appstore doang :v
RPCS3@rpcs3
All official builds of RPCS3 are listed on our download page. If it's not there, it's not official. Do NOT download RPCS3 from Discover Store, Flatpak or Snap and then come to us when it doesn't work. We offer zero support with unofficial builds and third party frontends.
Indonesia
@bizlet7 It looks way better by a lot.
But for someone who scrolls through AI-generated images all day… I'm just tired of it, boss.
i love old DLSS where they tried to fully reconstruct 1/9 resolution image to match the full resolution one. not this smartphone beautify filter crap.
English

Why are people saying the right looks worse?
It objectively looks way better.
Grummz@Grummz
This is real. Nvidia DLSS 5 running on Resident Evil Requiem.
English



I really like what Hytale offers with it's progression.
In Minecraft: your progression is anywhere as long as you can dig and go down.
In Vintage story: your progress is based on luck but a slight amount of adventure.
Hytale separates your progress by distance. which encourages adventure. While exploring and moving there's better and more difficult mobs that drop more resources of what you need.
there's premade structures such as enemy bases, mineshafts, demon temples, sunken pirate ships, ocean monuments.
I GREATLY enjoy the adventure aspect and it's good to know Hytale is focussed heavily on moving forward.
and they give you teleporters so you can keep moving and head home to have a base of operations.
I like it. I'd probably install mods or wait for updates to flesh it out and polish it more but this is pretty great so far.

English