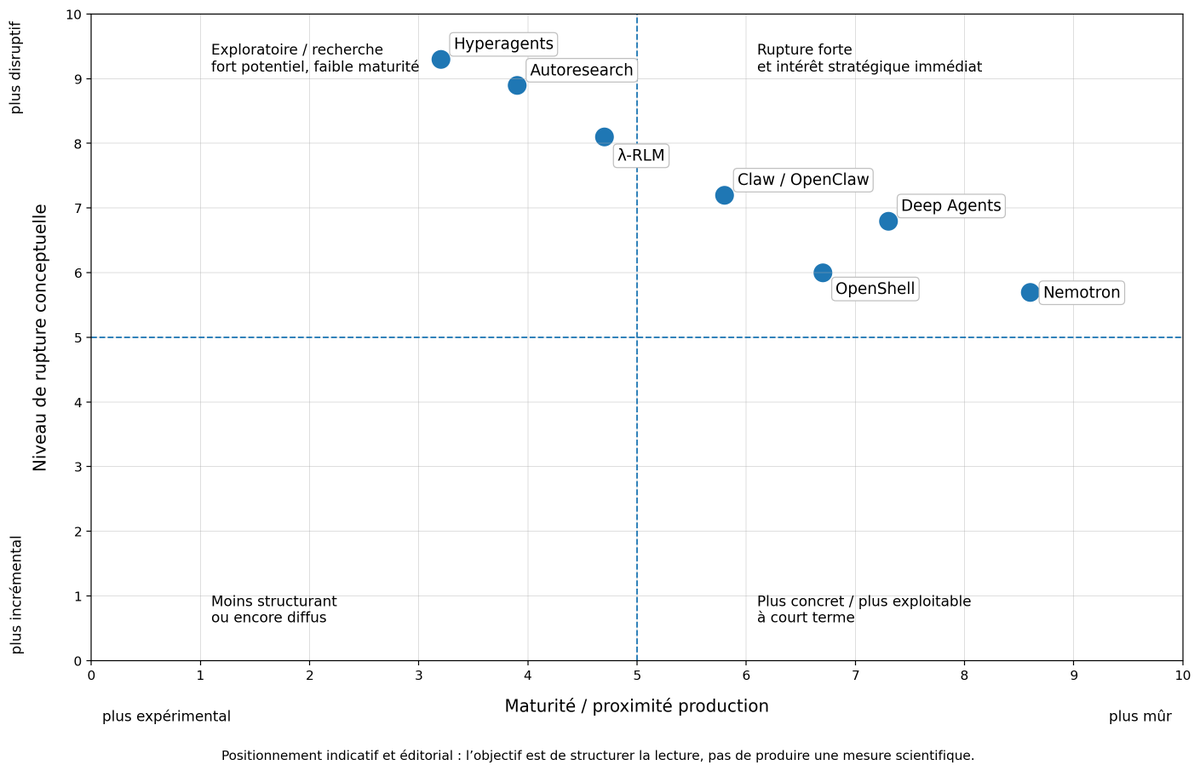
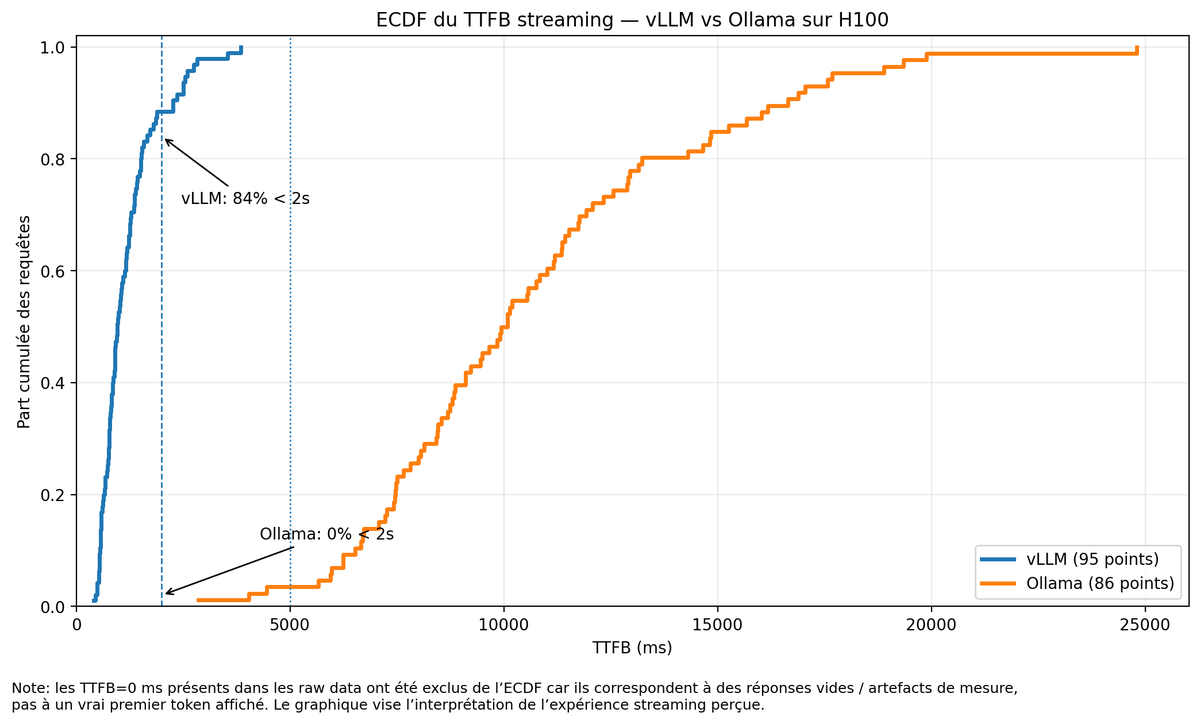
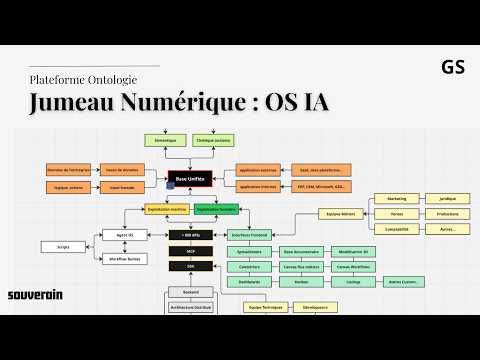
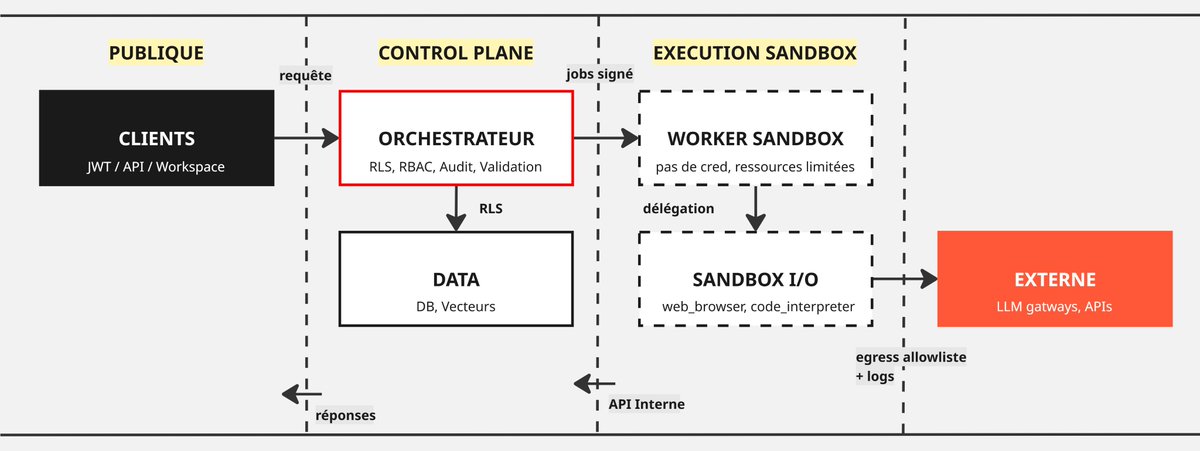
Sabitlenmiş Tweet

Comment conjuguer : données, applications, logique métier, et agents IA.
Tu arrives à créer des agents IA en 2 min avec n8n ? Mais ils ne sont pas branchés aux données de ton entreprise ni à la réalité opérationnelle (process et flux).
Pour récapituler notre logiciel :
1- Interfaces pour modéliser la logique métier.
2- Librairie d’agents nativement connectés à vos données.
3- 500 connecteurs logiciels pour unifier vos sources.
4- Workflow builder no-code / low-code pour automatiser les process.
5- 500 APIs pour consommer les données et services.
6- Interface de pilotage et de monitoring de l’ensemble.
bonus : hébergement souverain, inférence de l’IA en France, et développement d’intégrations sur mesure.
Pourquoi est ce qu’on à développé cette plateforme ?
Voici quelques problèmes qu’on à rencontrés lorsqu’on intègre l’IA :
- Données éparpillées entre logiciels et bases de données.
- Aucune modélisation fiable et vivante des flux métier.
- Très difficile de connecter l’IA à la réalité opérationnelle (et donc IA inutile).
exemple : si je veux avoir un agent branché sur mes données (type : base de données, flux métiers, documentation), il faut que j’arrive à récupérer ces données à travers différents logiciels et ensuite que je développe des pipelines pour récupérer et formater les données pour l’IA (gros travail)
L’ontologie permet justement de faciliter l’ensemble de ce processus.
En quoi c’est différent d’un n8n / make ?
n8n permet d’automatiser avec une richesse dans les abstractions (type agents), mais ne permet pas en amont de décrire les flux et donc d’avoir des workflows qui s’integrent à la réalité.
Dans la démo vidéo :
1. Je crée le flux d’une pipeline de vente (de l’apparition d’un prospect, à l’envoie de la proposition).
2. Je teste un agent IA, et il a automatiquement accès au contexte de la pipeline (oui pas besoin de développer de rag, des outils dédiés, de tout mettre tous les éléments dans le prompt, etc).
3. Puis je connecte un google sheet qui liste mes prospects.
4. J’utilise ce google sheet comme base de données, pour calculer quelles sont les entreprises les plus intéressantes à cibler, via un workflow d’automatisation (qui utilise notamment un agent IA).
5. Ensuite je peux piloter et monitorer l'ensemble.
si tu es intéressé par notre logiciel et notre accompagnement, tu peux prendre un rdv avec moi (sur mon site dans ma bio).
youtu.be/3p4JivtmiIA

YouTube
Français