Sabitlenmiş Tweet

A crucial read for ANYONE that uses social media. Send to a friend or loved one as well.
wired.com/2017/02/dont-b…
English
RIP yaksbeard
20.7K posts

@RIPYaksbeard
Just a nasty, nasty canadian.







7 years ago today, we unveiled Model Y It became the world’s best-selling car of any kind just 3 years later





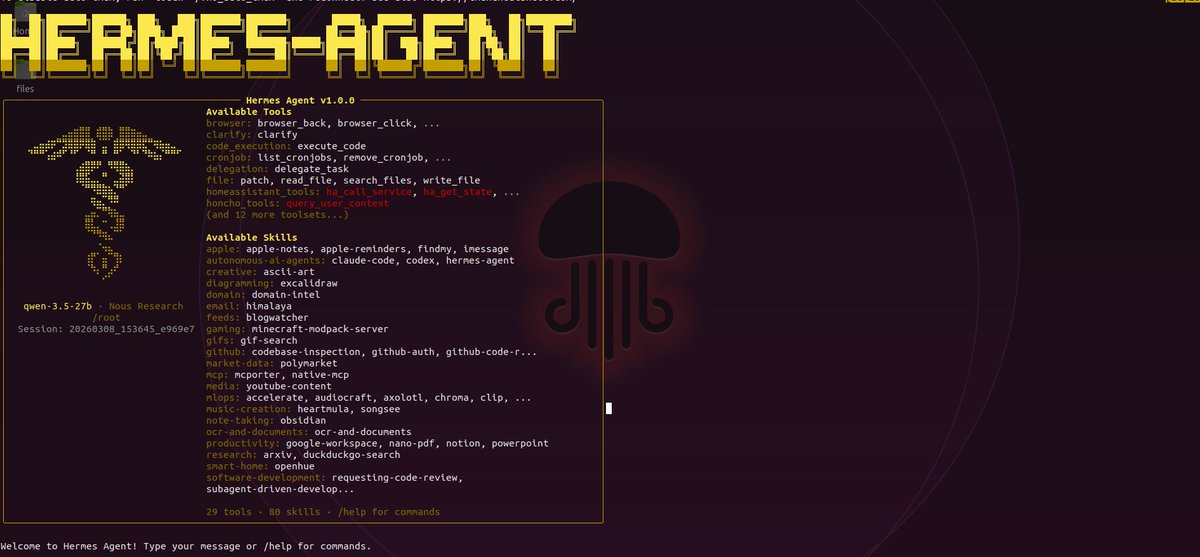

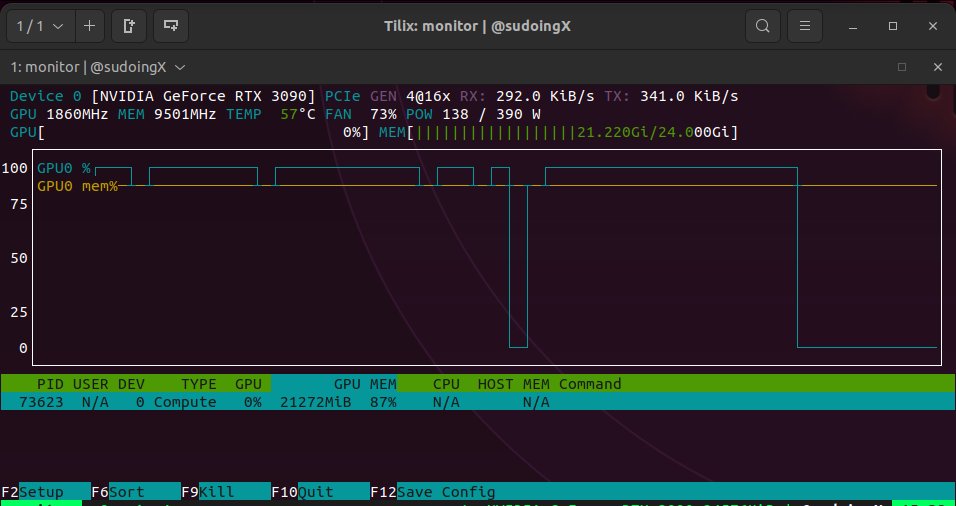
hermes agent on my 3090 with qwopus. will test it myself and report back. that's how we do it here.

We’re acquiring Promptfoo. Their technology will strengthen agentic security testing and evaluation capabilities in OpenAI Frontier. Promptfoo will remain open source under the current license, and we will continue to service and support current customers. openai.com/index/openai-t…
@JoelDeTeves @Teknium never used anything that starts with "open" or "claw" and never will. i run local models on my hardware i control.



Jim Carrey goes viral over his ‘unrecognizable’ appearance with fans saying he ‘doesn’t look or sound the same.’



