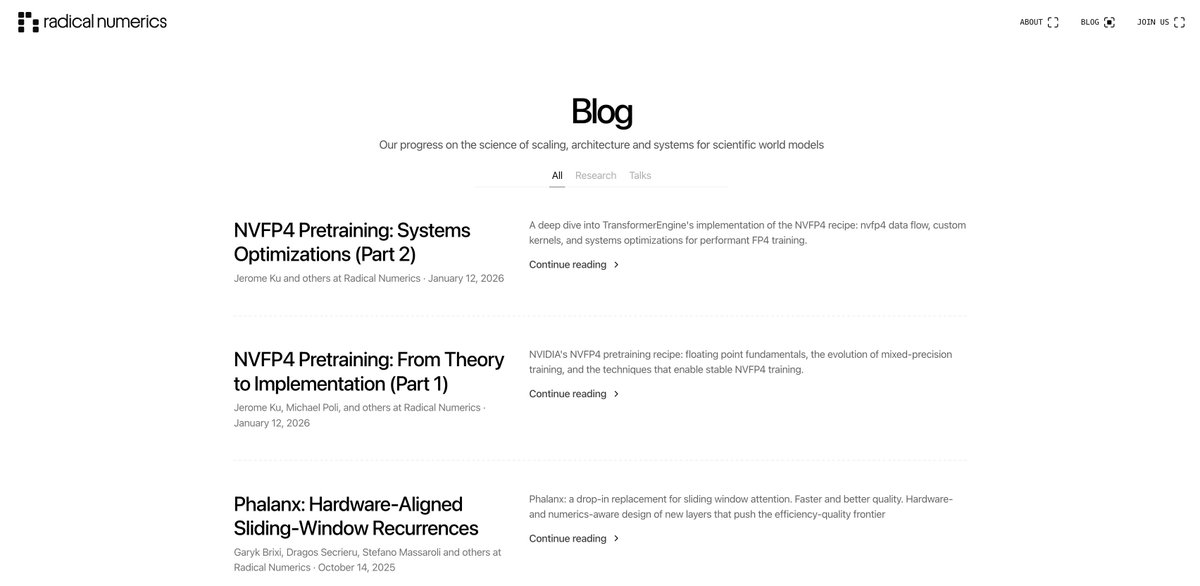
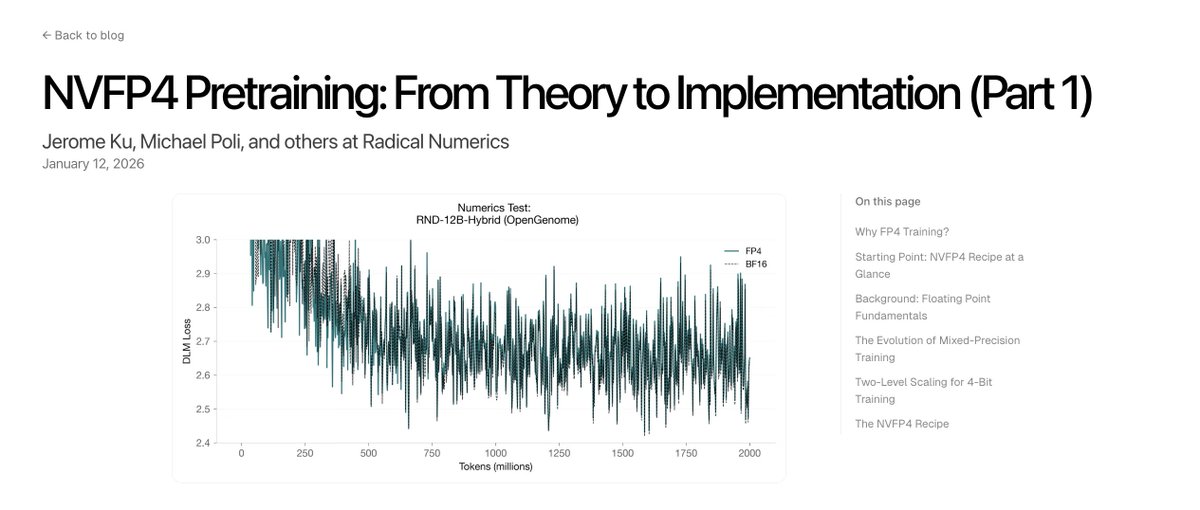
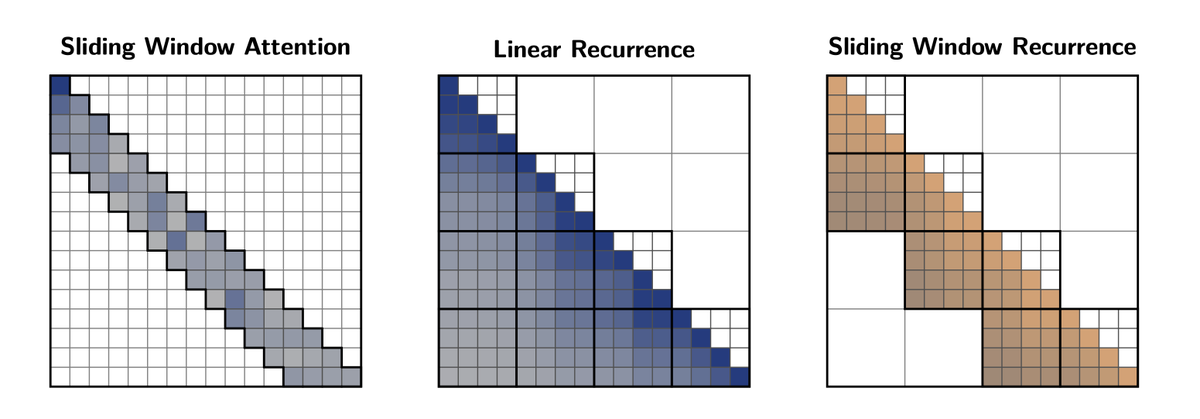
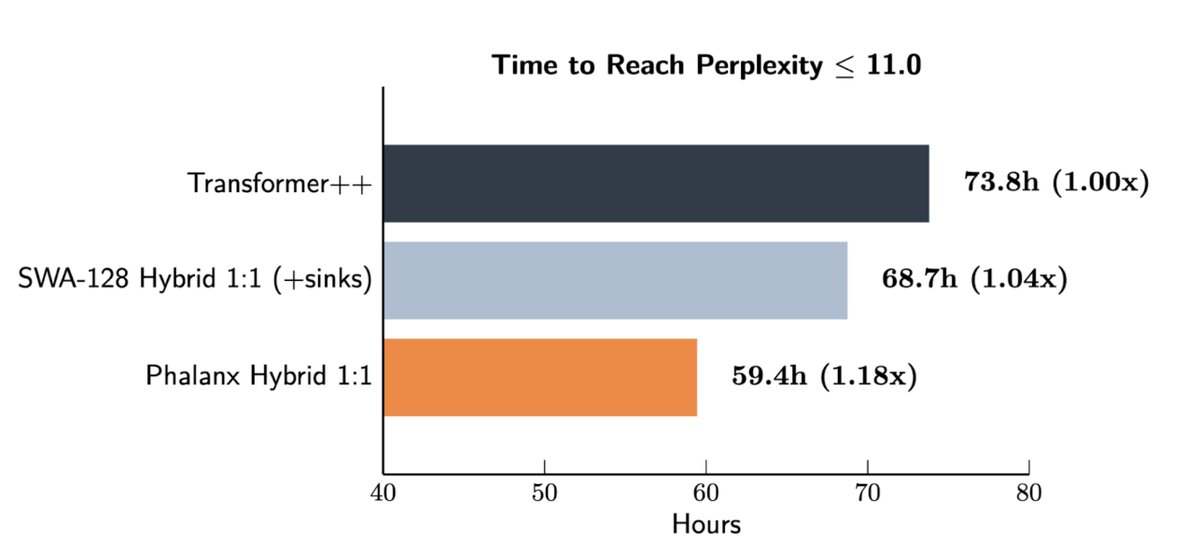
12/ If models become function-aware, our defenses must too. To scale biodefense, we're scaling our team + partnerships.
🌉🌎🗼Join our mission in SF/Tokyo: radicalnumerics.ai/join-us
📝Sign up for early access: radicalnumerics.ai/waitlist?track…

English