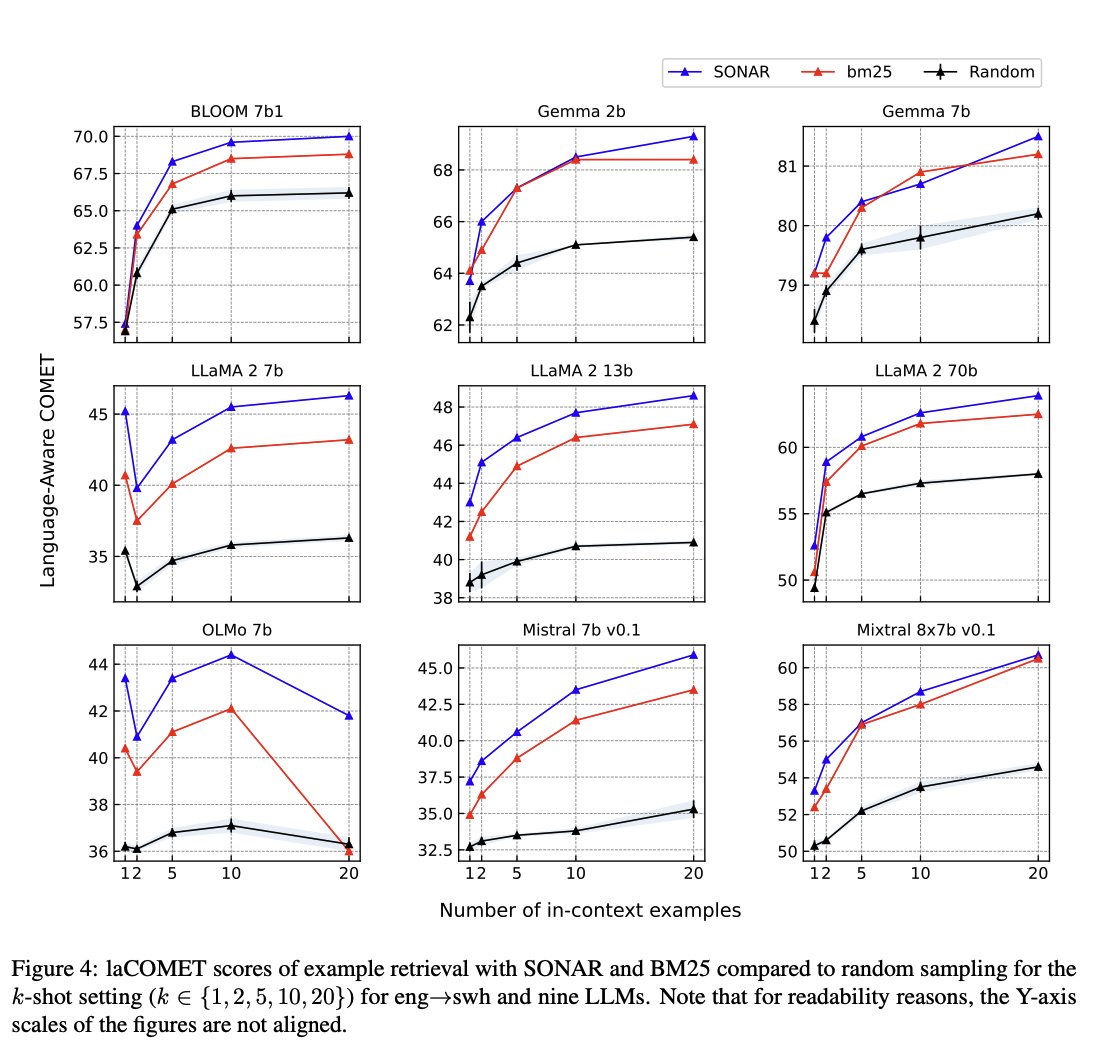
Sabitlenmiş Tweet

🎉 Grateful and happy to share that two of our papers were accepted to #EMNLP2025 Findings! 🚀
[1] Compositional Translation: A Novel LLM-based Approach for Low-resource Machine Translation
[2] TopXGen: Topic-Diverse Parallel Data Generation for Low-Resource Machine Translation
A big thank you to my amazing co-authors! 🙌
@bensagot @RABawden @InriaParisNLP
English