
Ray
415 posts


@saxena_puru In the new world of agentic AI, observability is essential for enterprises that run AI agents. Datadog is the leader in this category and will continue experiencing explosive growth as companies adopt AI agents.
English

"Software is dead" - really?
$DDOG beats estimates + raises FY revenue guidance
Stock +23% pre-market
Infrastructure software + cybersecurity stocks on the bargain table and few understand this alphatarget.com
English

Every Trading Strategy Explained in 6 Minutes
0:00 - Fibonacci Retracements
0:27 - Chart Patterns
1:01 - Elliot Wave
1:51 - FVG
3:06 - Support & Resistance
5:01 - Volume
5:22 - Supply and Demand
5:50 - Break of Structure
5:58 - Change of Character
English
This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent 2026 release represents about a 2x improvement over releases from 2025. Overall improvements in this area should continue to drive up the demand for AI work, tokens, and memory
English

Positive for hyperscalers as cost of inference goes down $AMZN $MSFT $GOOGL & capex buys more for same
Positive for logic $AVGO $AMD as memory bottlenecks eases. $NVDA mixed as groq may not be needed
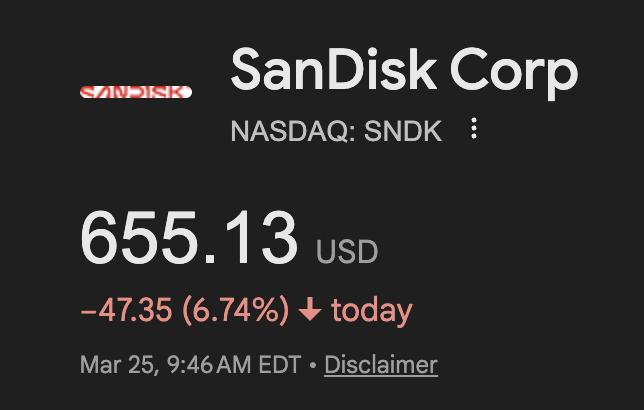
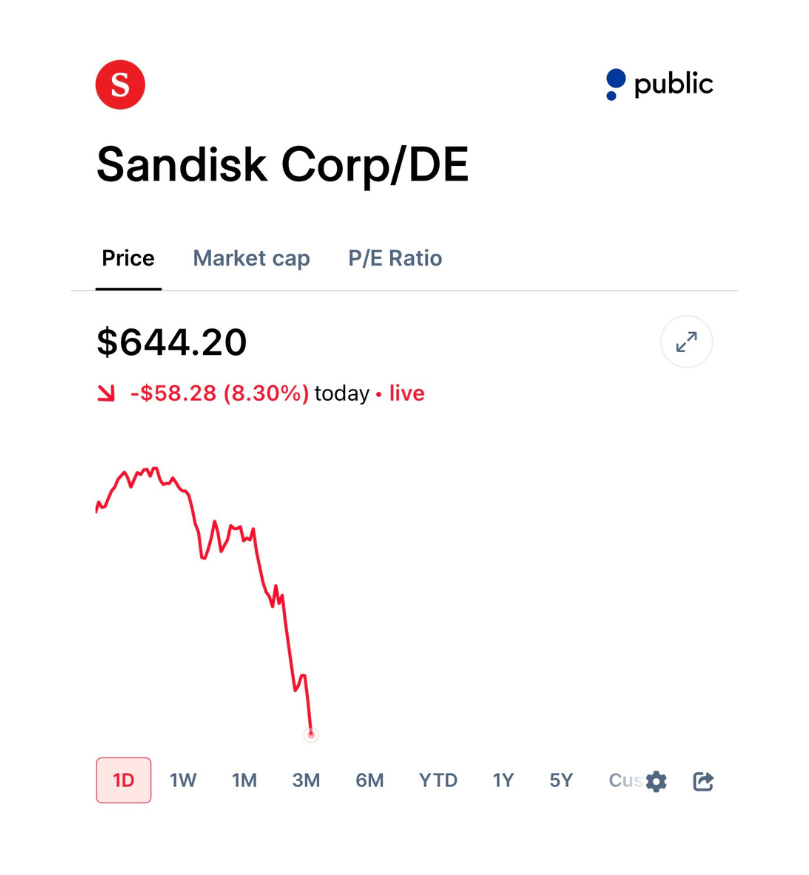
Negative for storage as NAND demand to store KV cache overflow eases $SNDK
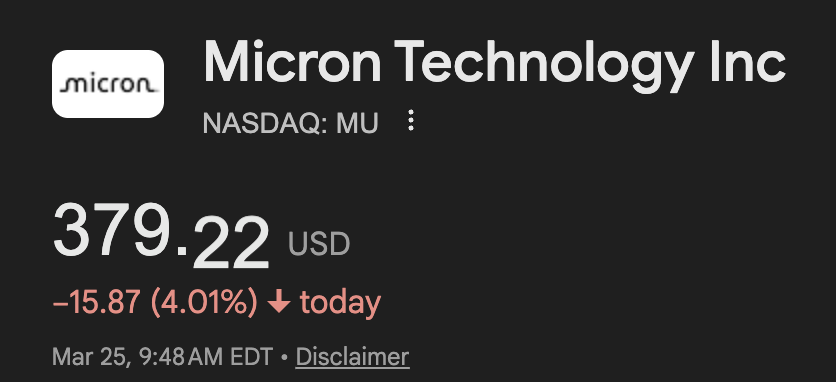
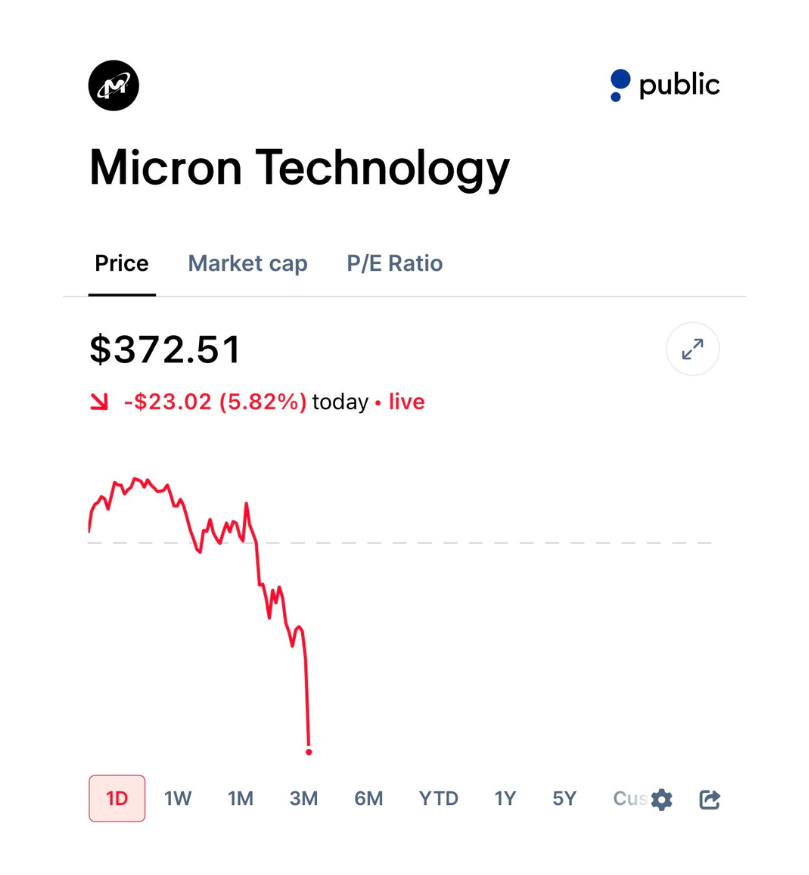
Big negative for memory $MU
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent release represents about a 2x improvement over releases from 2025. Overall these improvements should continue to drive up the demand for AI work, tokens, and memory
English

wow google might've popped the ai bubble, memory stocks down massively today:
their new algorithm shrinks an AI model's memory by 6X WITHOUT reducing it's intelligence making it 8x faster with the SAME # of GPUs:
if this works - we don't need as many GPUs to train AI
- kv-cache is basically a model's short term memory. it gets massive pretty quickly = larger, slower, expensive ai
- google's algo compresses it to just 3-bits with ZERO loss in accuracy (usually models are like 32-bit)
the combined market cap of micron and sandisk is $527 billion and im not even factoring in SK hynix and samsung
ai has driven up memory prices by 500%+ over the last few months - if google's algo scales then this might crash.
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent release represents about a 2x improvement over releases from 2025. Overall this and efforts like it should continue to drive up the demand for AI workloads, tokens, and memory
English

$GOOGL just released TurboQuant which is a new compression method that can cut LLM cache memory by at least 6x & deliver ~8x speedups without sacrificing quality
This could make local AI inference far more capable with larger context windows & less memory strain across devices
GIF
English
This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent release represents about a 2x improvement over releases from 2025. Overall this and efforts like it should continue to increase demand for AI tasks, tokens, and memory.
English

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
GIF
English
@aleabitoreddit This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent release represents about a 2x improvement over releases from 2025
English

Google's TurboQuant...
And it's effect on $SNDK, $MU, SK Hynix, and others:
What it does:
-> 6x reduction in KV cache memory footprint
-> 8x Speedup on H100 GPUs
It's a compression algorithm.
Now... Will it beat down memory?
-> Prob not.
Implications might be bullish for $ARM and others though where you can run AI locally, rather than DRAM heavy DCs.
However:
->This is basically DeepSeek round 3. You can make algorithms more efficient. But that doesn't replace either memory or GPUs.
-> It could structurally (and slightly) reduce DRAM demand.
-> think it's only been tested on small models so far like Gemma, Mistral, and Llama-3.1 (and paper's been out for a year)
Also, markets conflated DRAM with NAND... this algo compresses the KV cache (DRAM). Doesn't do anything to NAND storage?
Regardless:
Algorithms will always get more efficient. People keep saying Jevons Paradox, which is true since this just scales use cases.
Main thing to look out for is hyperscaper capex projections, not Google Algorithms that made things more efficient.
Feels more like a narrative headwind than anything material to earnings.

English
This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent release represents about a 2x improvement over releases from 2025. Overall these improvements should continue to drive up the demand for AI work, tokens, and memory.
English
$MU and $SNDK are getting hit hard at the open from the release of $GOOGL TurboQuant.
The market is reading it as a potential headwind for memory names because long-context AI inference may now need far less memory per workload.
Shay Boloor@StockSavvyShay
$GOOGL just released TurboQuant which is a new compression method that can cut LLM cache memory by at least 6x & deliver ~8x speedups without sacrificing quality This could make local AI inference far more capable with larger context windows & less memory strain across devices
English
@wallstengine This technique has been around since 2023 and have been worked on by Google, Meta, Microsoft, etc. So it’s not new. This most recent release represents about a 2x improvement over releases from 2025
English

$MU $SNDK
Google Research has introduced TurboQuant, a new KV cache compression method that it says reduces LLM cache memory by at least 6x and delivers up to 8x speedup with no accuracy loss, targeting memory bottlenecks in AI inference and vector search.

Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
@wallstengine This actually increases the demand for tasks, tokens, and memory.
Memory per task ↓, but tasks per system ↑↑. It’s actually bullish for memory companies.
English
@TripleDTrader All this does is increase the demand for tokens, tasks and memory.
Memory per task ↓, but tasks per system ↑↑. It’s actually bullish for memory companies.
English

Did Google just give us our first hardware disruption?
$MU -2.3%
$SNDK -6.4%
$STX -2.6%
$WDC -2.9%
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
@JasonL_Capital Copper is definitely not dead. It’s very much a necessary interconnect between the GPU and first layer of switches. This is because optical’s error rate is too high. At the end of the day, both copper and optical are necessary, just at different parts of the AI infrastructure
English

NVDA just told you the next AI trade.
They invested $4 billion into optical infrastructure today.
$2B into $LITE.
$2B into $COHR.
Why? Because copper is dead at AI scale. Data centers are moving to light-based interconnects. Optical is the new backbone.
$AAOI ran 22% on the news alone.
The full optical watchlist:
$LITE - Silicon photonics. Direct NVDA partnership.
$COHR - Optical modules and lasers. Direct NVDA partnership.
$AAOI - High-power lasers for data centers.
$CIEN - Optical networking at scale.
$AXTI - Substrates for laser manufacturing.
When NVDA puts $4B into a sector, it's probably smart to start paying attention
This is the next leg of the AI trade.

English
@insane_analyst Memory is no longer a cyclical business that depends on the upgrade cycles of personal computers and mobile phones. $MU, for example, now gets most of it revenue from data centers. It has a core growth engine that make it an AI infrastructure growth story.
English
Memory stocks should not be viewed on P/E basis.
Literally go to 2023 $MU earnings calls where Sanjay was publicly begging Samsung for mercy.
There will be oversupply and negative gross margins in future. Memory is most violent sub-sector of semis, a violently cyclical biz.
English
@JesseCohenInv You mean the guy that busted out of his hedge fund with losing bets on LULU and has now resorted to manipulating markets through a substack?
English

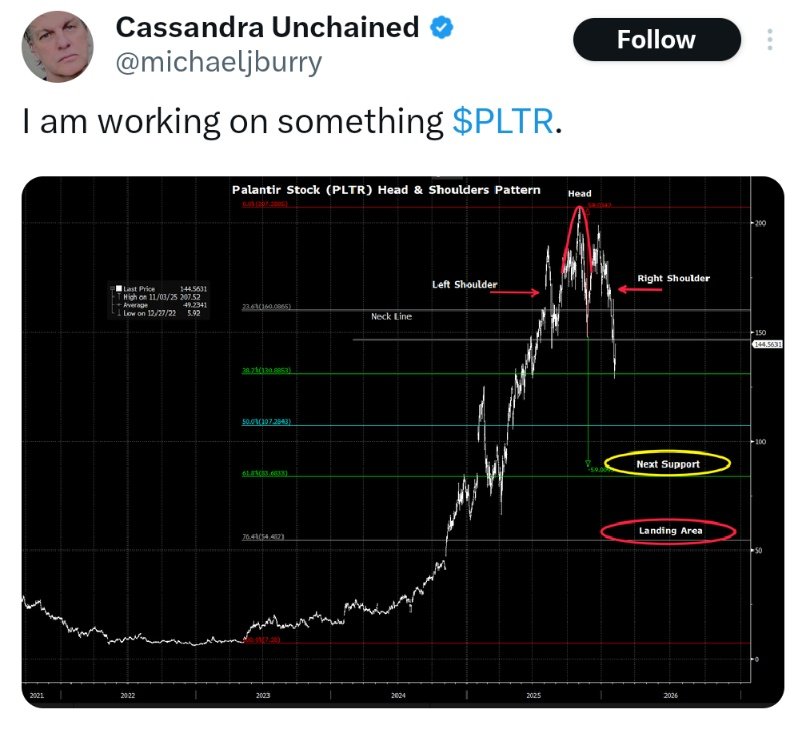
Big Short investor Michael Burry warns of Palantir $PLTR stock plunging to $50.
Another day another warning.

English

Bunch of bagholders on $WDC $SNDK $MU digging for reasons of weakness. Just look at the chart.
English
@theUMreal Insider selling is literally the worst market signal there is. There are many reasons people sell (buy a house, divorce, etc) but only one reason insiders buy.
English

China's CXMT and YMTC to massively expand memory output amid global crunch
- According to reporting by Nikkei Asia, China’s two major memory manufacturers view the global supply shortage as an opportunity for “emerging players” to catch up and are embarking on record-level aggressive capacity expansions. The increased production volume is highly likely to be used primarily to meet domestic demand within China.
- ChangXin Memory Technologies (CXMT), China’s largest DRAM maker, is currently expanding its Shanghai plant. Upon completion, its total production capacity is expected to be two to three times larger than that of its Hefei facility. The plant will produce DRAM for servers, PCs, and automobiles. Equipment move-in is reported to be around the second half of 2026, with mass production starting in 2027. Additionally, an expansion of HBM production lines is underway in Shanghai.
- Wuhan-based NAND manufacturer Yangtze Memory Technologies (YMTC) is constructing its third plant in Wuhan, targeting a production start in 2027. The company plans to allocate 50% of the new plant’s capacity to DRAM and is reportedly discussing cooperation with domestic packaging firms for HBM. Furthermore, according to official statements, they have found ways to produce using less advanced equipment, partially bypassing export controls, and there are even claims that they have finalized their own proprietary DRAM development.
- While YMTC previously had the possibility of supplying Apple, it faced setbacks after being added to the U.S. Entity List in 2022. Since then, it has regained growth momentum driven by China’s localization policies and favorable market conditions.
- According to Yole Group estimates, CXMT is the world’s fourth-largest DRAM maker following Samsung Electronics, SK Hynix, and Micron (with a market share of approximately 11.1% based on production capacity), which could expand to about 13.9% by 2027. The report also mentions that CXMT has secured major tech customers such as Alibaba Cloud and references documents from China International Capital Corporation (CICC).
- CXMT is pushing for a transition to DDR5-grade technology beyond DDR4/LPDDR4 and aims to support domestic HBM demand in China. The company is reported to be targeting a 29.5 billion yuan (approx. $4.25 billion) raise through an IPO on the Shanghai Stock Exchange.
- Estimates also suggest that YMTC’s NAND market share could expand from about 12% in 2025 to 15% by 2028. Gary Huang assessed that “the supply shortage favored emerging players, and the combination of financial conditions, localization, and government support is promoting the adoption of alternative supply sources.”
Jukan@jukan05
Here it comes.
English
@tomshardware These 2 chinese players are 3-6+ years behind the incumbent memory makers. So if Micron/Samsung/Sk-Hynix did nothing for 3-6+ years then maybe they’d catch up.
English

China’s CXMT and YMTC to memory output — two new fabs could close the gap with the ‘big three’ tomshardware.com/pc-components/…
English

$MU 36+ pts swing so far in overnight session hitting 391, which is ~ 66 pts lower than its Friday morning premarket peak 457….
Are we going to see lower low on weekly chart? That’d put it at 384 or below - which should be close to its rising 5ma on weekly chart….
A crash like this does not scare me…. It EMPOWERS me - seeing how confident I am in holding onto my shares regardless of price variations, and also enabling me to add more shares at discount when the retail weak hands panic-sell.….
The journey to $600+ is never supposed to be easy and one-direction…. But it’s challenging time like this that can truly test our resilience…. And remember, even Nvidia had a quite few 20-40% dips along the journey…..
MentoviaX@MentoviaX
$MU technical patterns never worked 100% in this name..... in the past five instances of a bearish engulfing candle on daily chart, 3 out of 5 times instead of going lower low as what names would typically do in this technical setup, it had a gap-up higher high run the next trading session.... Are we going to see another ascending triangle or COIL formation here with gap-up run on Monday? Volume seems to suggest that this is NOT the short-term top.... the bull thesis to 472 is still on the playbook.....
English