Sabitlenmiş Tweet

ReadyAI
232 posts

@ReadyAI_
Making the world's data accessible to AI. Home of AcquiOS for CRE & M&A acquisitions Bittensor Subnet 3️⃣3️⃣ 🌐


If Martin is right, he also just wrote the product spec for open source + distributed compute where broad swaths of groups, individuals and organizations contribute their compute resources to training runs for large param open source models. There are lots of issues in figuring this out: homogeneity vs heterogeneity of the training clusters, orchestration, financial incentives etc etc etc but some early projects are good signal as to where this can go and that these limitations can be overcome (folding@home, Venice, Tao). An attempted oligopoly on intelligence is the perfect boundary condition for a bottoms up uprising of fully open, fully distributed AI.

Yes emissions are used to bootstrap innovation, same as Uber, Amazon and countless of other big companies You can chose between these 2: -give those emissions to VC’s -give those emissions to builders who devote their whole time to build out the network Vc’s hate it because they can’t apply the VC playbook/had discounted access compared to the masses

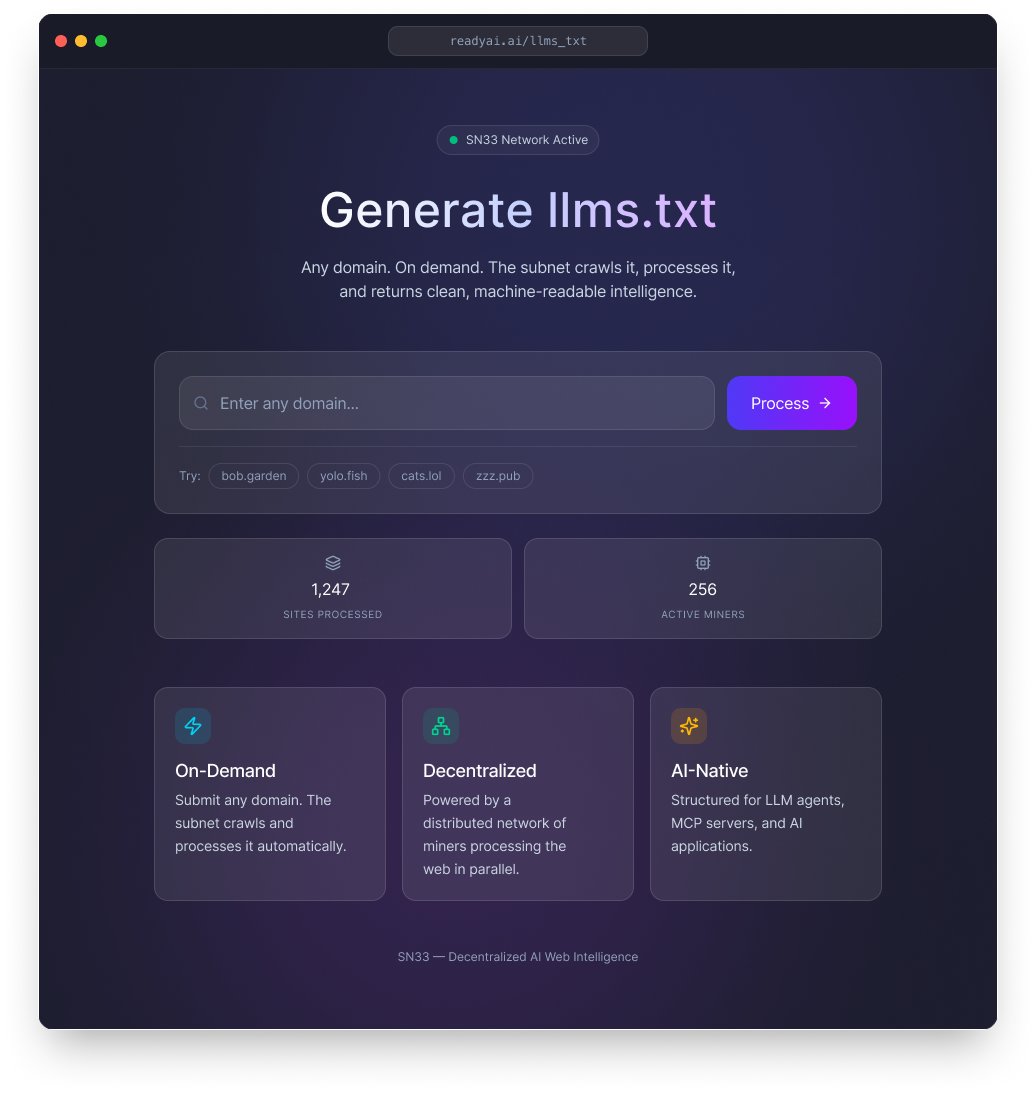
We just launched a new readyai.ai Type any domain into the search. If it's in our dataset, you get clean, structured intelligence instantly. No scraping. No parsing HTML. Just machine-readable data, ready for any AI agent. 10,000+ websites crawled, cleaned, and structured by Subnet 33 so far. Growing to 100K by Q2, 1M by year end. This is the beginning of something bigger: a marketplace for agentic data. Right now, every AI agent that needs info about a company or domain scrapes, parses, and hopes. Billions of redundant crawls. Trillions of wasted tokens. We're building the infrastructure layer that fixes this — an indexed, machine-readable web powered by decentralized compute.
Nothing to see here… Just Jensen Huang (CEO of the world’s most valuable company Nvidia) and Chamath discussing Bittensor $TAO 🤯