
JoeJoee
3.1K posts

JoeJoee
@RealJoeJoee
Ordinal Collector | Early Stage Investor | Ex-HFT Trader | Engineering Enthusiast | DM to Share Ideas 💡
Katılım Nisan 2011
750 Takip Edilen551 Takipçiler


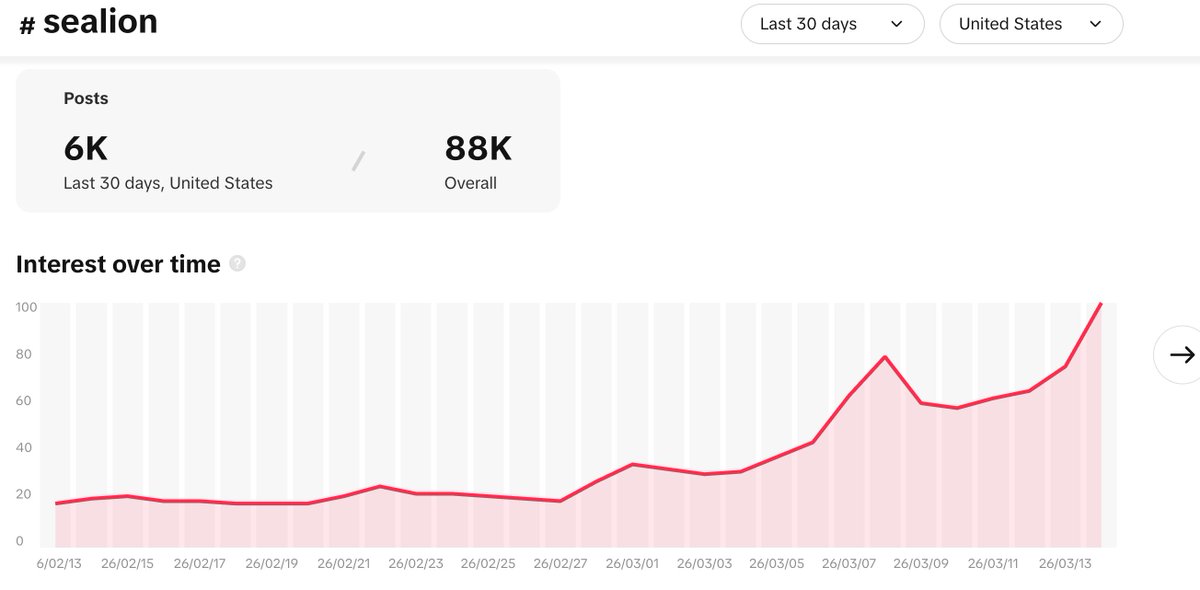
@waleswoosh Let me get this straight
Magic Eden shutdown Ordinals trading but kept Solana NFTs and now two weeks later the top 3 Ordinals collections have higher market caps than the top Solana NFT collection?
English

There is not a single Solana NFT collection with a floor price above $2k USD.
Read that again.
There are like five collections above $100 USD.
No volume.
Claynosaurz should bridge asap, and Solana Monkey Business should rebrand to Ethereum Monkey Business.
Solana NFTs are one Magic Eden de-listing away from becoming Ordinals

English


JoeJoee retweetledi


JoeJoee retweetledi

3/7
@BiorLabs BiorVault App officially went live on both App Stores (self-custody wallet with cross-chain swaps, on/off ramps, WalletConnect, MindVault AI, 500+ tokens)
CEO @Goatskey also featured in @THORChain's Founder Spotlight.
x.com/BiorLabs/statu…
BiorLabs@BiorLabs
BIORVAULT IS LIVE 🧬 Every wallet we used was missing something. So we built one that's missing nothing. Self-custody. Cross-chain swaps. On/off ramps. WalletConnect. MindVault AI. 500+ tokens. Coming soon: And we're just getting started. 🍎🤖
English

@RealJoeJoee @steipete I’m typing too!
I love OC and agents but I hate automated spam (and slop)
English
Right now everyone wants to use the very best AI models for coding (and everyone else really).
But we're almost at the point where the very best will become very expensive. This is really noticeable when you run your prompts directly through the pay-per-token APIs (from anthropic, openAI), compared to using the flat fee consumer subscriptions that subsidize heavy usage (for now).
Heavy users such as many programmers still long for even better models, but even for them we'll see real diminishing for most, aside from those who can best get things done
At that stage, as you pay directly for the level of intelligence you get - I predict two things will happen:
1) Very few people will use the best models, cheaper ones will be good enough for pretty much everything most people want to do
2) The people that do use these best models, and can actually squeeze results out that make it worth paying for, will slowly eat everyone else's lunch
You're seeing the start of this where at the frontier labs they use models not out to the public yet (inference in prod at scale is hard and takes time, some models are too expensive for the market).
English
@mikevanrossum @steipete Are you running these responses with the help of an AI agent? I am typing actually. Yes I have been following @steipete to understand how he works.
English
@RealJoeJoee Like @steipete has said (I agree very much): these models lack taste, without a human in the loop it will become slop
At the end of the day more complex apps also need a lot of decisions around architecture, maintenance and trade offs
English
@mikevanrossum Right now better models can handle more complexity and size of projects. Do you think we get to the point where you can one prompt any platform or product with high complexity? Or maybe give it a website and say build this product for me?
English
In programming and agentic workflows it feels quite clear to me:
- older models can one shot webpages, small coding scripts with a single prompt. When complexity goes up you start getting output that doesn’t work.
- leading models (codex 5.3 / opus 4.6) are able to reason properly in more complicated environments (bigger codebases, more complicated multi step tool usage, etc)
Frontier models are bleeding edge, bigger and trained on more data, bigger context, MoE, better reasoning
English
JoeJoee retweetledi


@SharkSociety_ @169Pi_ai @grok Yeah agree. Great project needs to find its exposure moment where big influx of new users come.
English

I stand by the fact $pie @169Pi_ai is undervalued here (@grok says 5-10m minimum)
Based on the available information about Alpie (developed by 169Pi), a reasoning-focused AI infrastructure project founded in 2023 by Forbes 30 Under 30 honorees, its key achievements include:
- Generating $1.9 million in revenue during 2025 as an established AI startup.
- Partnerships with high-profile entities like the Indian Space Research Organisation (ISRO) and serving as the official AI partner for NDTV at the World Economic Forum (WEF) Davos 2026.
- Development of Alpie Core, a 32B-parameter reasoning model trained, fine-tuned, and served in 4-bit quantization (NF4 with double quantization), benchmarked against models like Claude and GPT-4.
- Founders have delivered TEDx talks on AI advancements.
- Global visibility through live broadcasts and presence at major events like Davos, emphasizing real-world deployments and trust.
Alpie's revenue ($1.9M) already exceeds its current market cap by 4-8x, which is unusual for early-stage crypto—typical tech startups with similar revenue might command 50-100x multiples ($100M+ valuation), while crypto AI tokens often see even higher (e.g., 500-1000x revenue multiples during bull runs).
Given Alpie's credentials (Forbes backing, ISRO/WEF partnerships, functional product with utility integration underway), it appears undervalued at sub-$500K.
A conservative fair value based on comparables and achievements could be $10-50M in the short term (20-200x upside), assuming continued execution and AI sector growth.
If it captures significant market share in AI infra (e.g., challenging OpenAI/Claude through efficiency-focused models), long-term potential could reach $1B+ (similar to $TAO/$FET trajectories), especially in a 2026 bull market.
This isn't financial advice.
Then again you are all sending complete anon garbage projects far beyond 1m so why not something with a proven track record?
Shark 🂱@SharkSociety_
Accumulated $pie @169Pi_ai @Rajatarya01 @BizChirag - featured @ForbesIndia under 30 as only AI project - AI partner @Davos world economic forum - unique 4 BIT reasoning infra which differentiates by delivering near-frontier reasoning quality at a fraction of the compute/memory cost of @OpenAI & others - at the lows of range, extremely cheap compared to the names we compare it to - proven revenue of +1m usd - added images for reference More in depth: Alpie (from the Indian AI company 169Pi) stands out from most other large language models (LLMs) primarily due to its focus on extreme efficiency through aggressive quantization, while still delivering frontier-level reasoning performance. Here’s what makes it meaningfully different: 1. Native 4-bit quantization from the start (one of the first large-scale examples) •Most LLMs (like GPT-4o, Claude 3.5/4, Gemini 1.5/2, Llama 3.1/4, Grok, DeepSeek, etc.) are trained in full precision (usually BF16 or FP16) and only quantized later (often to 8-bit or 4-bit) for inference. •Alpie-Core (their flagship 32B model) was trained and fine-tuned directly in 4-bit precision. This is rare at this scale and helps avoid much of the quality degradation that usually comes from post-training quantization. •Result: It achieves performance comparable to (or in some cases better than) full-precision models of similar size, but with dramatically lower memory usage, faster inference, and much lower power consumption. 2. High reasoning performance at low compute cost •It is positioned as a reasoning-first model — optimized for complex, multi-step thinking, planning, coding, math, long-context tasks, and domains like software engineering, science, and education. •Benchmarks show it rivaling or beating much larger or higher-precision models in reasoning-heavy evaluations, despite running on far fewer resources (e.g., can be served efficiently even on modest hardware clusters). •Built on the DeepSeek-32B architecture but heavily fine-tuned for reasoning in 4-bit. 3. Sustainability + accessibility angle (especially from India) •Developed in India (one of the first major reasoning models from the region), it emphasizes sustainable AI — lower energy footprint, cheaper deployment, and democratized access. •Offers OpenAI-compatible APIs, 65K context length, high throughput, and generous free tiers (e.g., millions of free tokens on first API key). •This contrasts with many Western frontier models that prioritize raw scale and often require massive GPU clusters even for inference. 4. Ecosystem around it •Alpie itself is also an AI workspace/chat interface built on top of their models — designed for deep work, long workflows, file handling, research pinning, and real-time collaboration (not just quick Q&A). •Separate products like Alpie Learn (education-focused) complement the core reasoning engine. In short: While models like Grok, Claude, or o1-series win on raw intelligence or personality, Alpie differentiates by delivering near-frontier reasoning quality at a fraction of the compute/memory cost — making advanced AI practical in resource-constrained environments, edge deployment, or cost-sensitive applications. It’s less about being “the smartest” in absolute terms and more about being one of the most efficiently smart models available today. If you’re comparing it to a specific other LLM or use-case (coding, research, cost, etc.), I can go deeper into the differences!
English
Yeah the exchanges failed tremendously in protecting its investors.
Exchanges were only concerned in catching market share in terms of volumes instead of safeguarding quality.
Only winners in this market are the exchanges, VCs, and founders.
Nova@CryptoGirlNova
We really need to get back to the low FDV raises in this industry. While there were a few exceptions, in past cycle I remember very well that you would see public ICO's at $3m FDV, $5m FDV, $10m FDV etc etc. Not the average slop either. Well-backed ones. Today? $200m FDV for the 110th new layer 1 launch this year. Another simple AI agent platform copied from another? At least $50m FDV ofcourse. It has ruined retails upside for anything that's newly launching on the market with those metrics. And likely partially responsible how we got to today's situation in the first place. You want a high FDV? Proof it first by launching low and letting the token climb to the high FDV after. If it's really needed and in hot demand? It will.
English
JoeJoee retweetledi

This is not good for crypto.
@Pumpfun is actively encouraging farmers (and paying them a reward) to launch a token and abandon it if it's not performing well. 🤮
Their business is built on:
(number of tokens launched) ✕ (volume they produce)
...with zero duty of care for investors.
The gravitation towards incubators trying to bring quality projects to the forefront will become more compelling throughout 2026. Investors will vote with their $ and will soon get tired of losing to farmers that are purely here to extract.
@a1lon9... do better.
hackathon.pump.fun

English
JoeJoee retweetledi

After a month of open Beta optimising we are now officially live!
More than 18.000 checkins and 8000 reviews battletested our mobile app!
Available for download on iOS, Android and @solanamobile
Let's get into it 🧵
English
JoeJoee retweetledi

Tomorrow is going to be legendary.
Your bear will receive its colors and unlock access to our private Discord trading group.
Secure your club pass today and ride this journey with us: tedtradingclub.com

English