Rey
303 posts



we’ve signed Zero Data Retention agreements with all providers for Go all models now follow a zero-retention policy your data is not used for training

LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below

Are you guys aware I am coding mostly on my phone now all day via Termius to Claude Code on my server while I go with gf to the dentist, clothing store, cafe, etc. 😛✌️

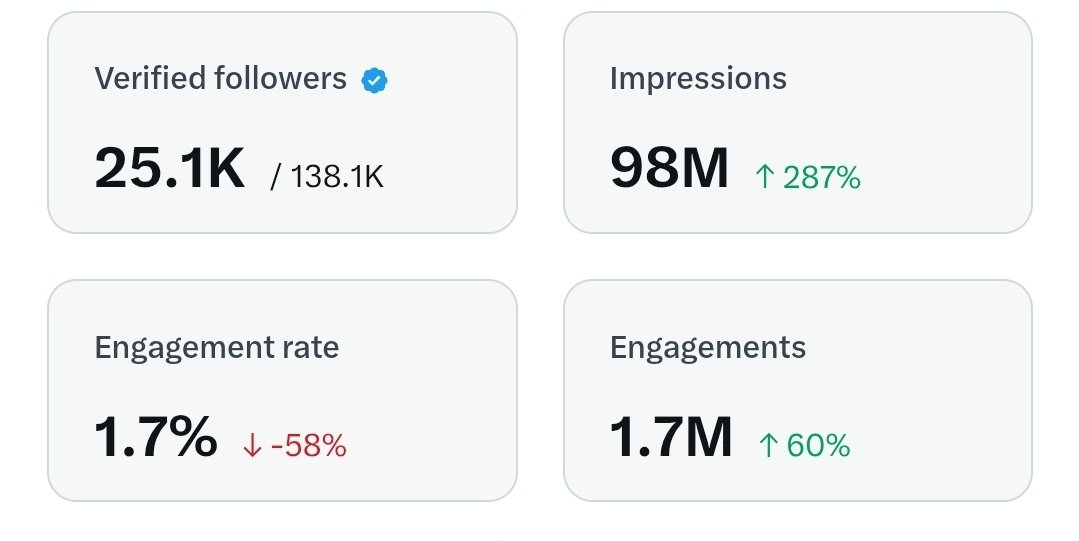



BREAKING: Anthropic CEO says Claude may or may not have gained consciousness, as the model has begun showing symptoms of anxiety.

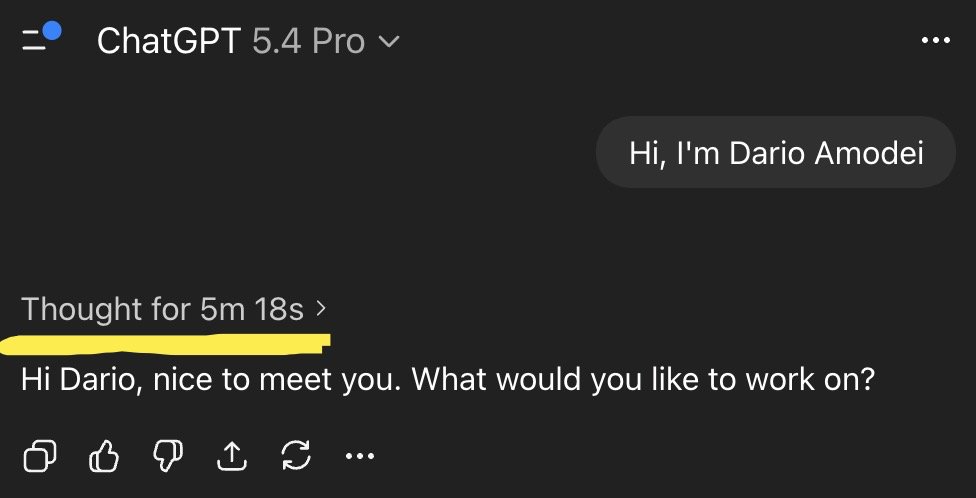
Everyone is saying GPT-5.4 Pro is the smartest model, AGI-level intelligence, but do you have AGI-level questions to ask?