Ruoca
2.3K posts












Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026 Key takeaways for the reasoning variant: ➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt +9.7 p.p (3.7% to 13.4%), HLE +9.2 p.p (28.9% to 38.1%), TerminalBench Hard +6.9 p.p (43.9% to 50.8%) and GDPval-AA +42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview ➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the +4.8 point gain on the Intelligence Index ➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M) Key model details: ➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview) ➤ Multimodality: Text input and output only ➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API) ➤ Licensing: Proprietary, closed weights

You can now use your @grok or X Premium subscription in @opencode. Use the model powering Grok Build for high speed and codebase intelligence. x.ai/news/grok-open…















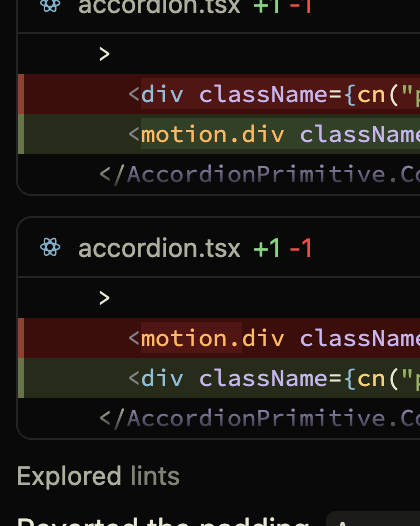
@cursor_ai has been using motion.div even in projects which do not have framer motion as dependency and then self correcting immediately. Has been happening for the last few days. Anyone else notice the same?

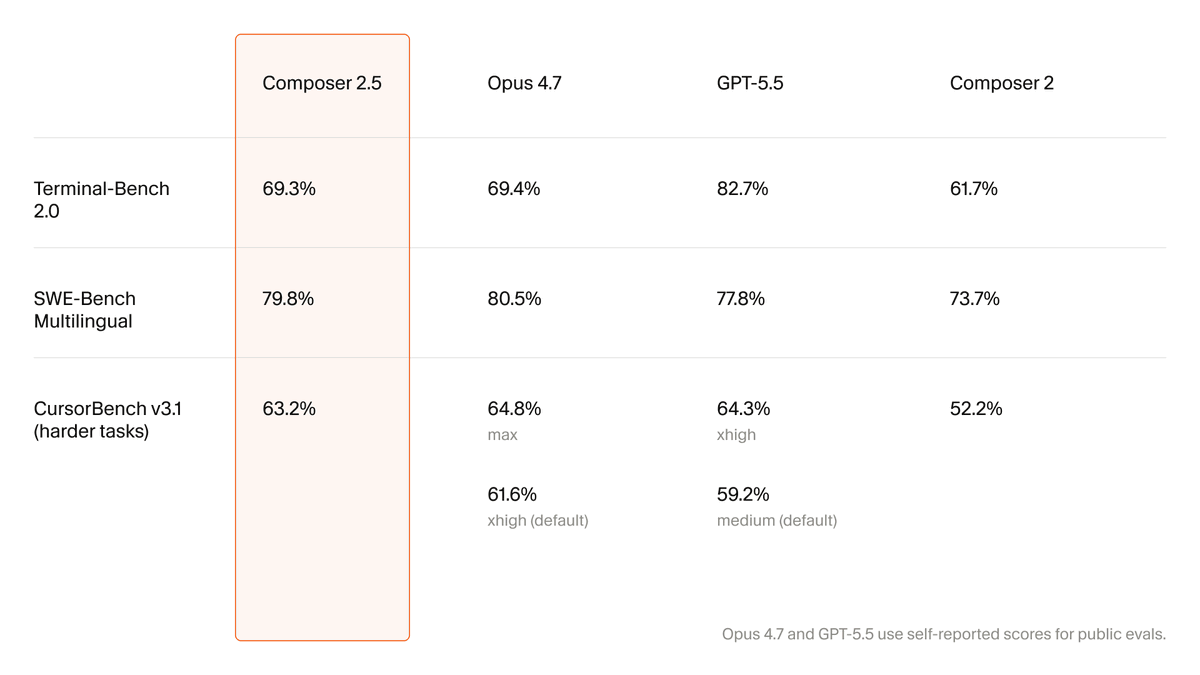


Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model.



PowerToys 0.99 is here 🎉🛠️ 🖥️ Control your monitors with Power Display 🪟 Move windows from anywhere with Grab And Move ⚡ Command Palette & Dock upgrades ✨ Plus tons of fixes and polish Check out the blog post to learn more: aka.ms/powertoys-rele…

