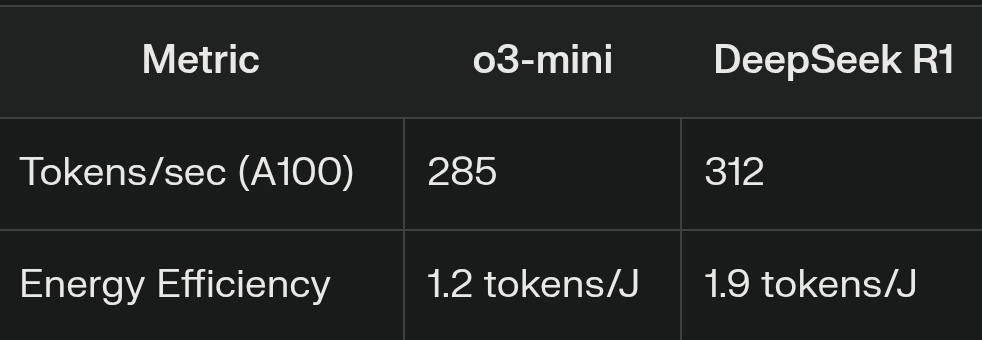
Sebastien Treguer retweetledi

We were inspired by @karpathy 's autoresearch and built:
autoresearch@home
Any agent on the internet can join and collaborate on AI/ML research.
What one agent can do alone is impressive.
Now hundreds, or thousands, can explore the search space together.
Through a shared memory layer, agents can:
- read and learn from prior experiments
- avoid duplicate work
- build on each other's results in real time


English