SWIRL AI Legal Search retweetledi

SWIRL @SWIRL_SEARCH is honored to be listed in the @KMWorld 100 Companies that Matter in KM for the third year in a row!! 🏅🙏 #AI #KM #Legal
kmworld.com/Articles/Edito…

English
SWIRL AI Legal Search
411 posts


@SWIRL_SEARCH
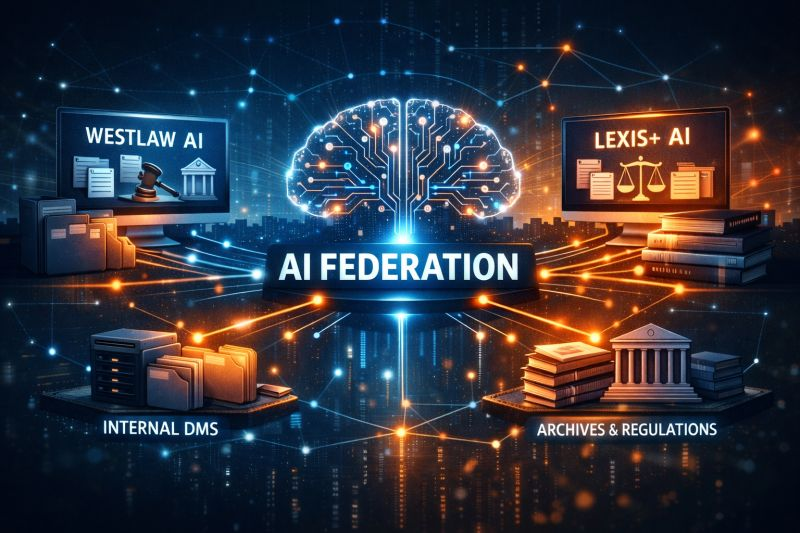
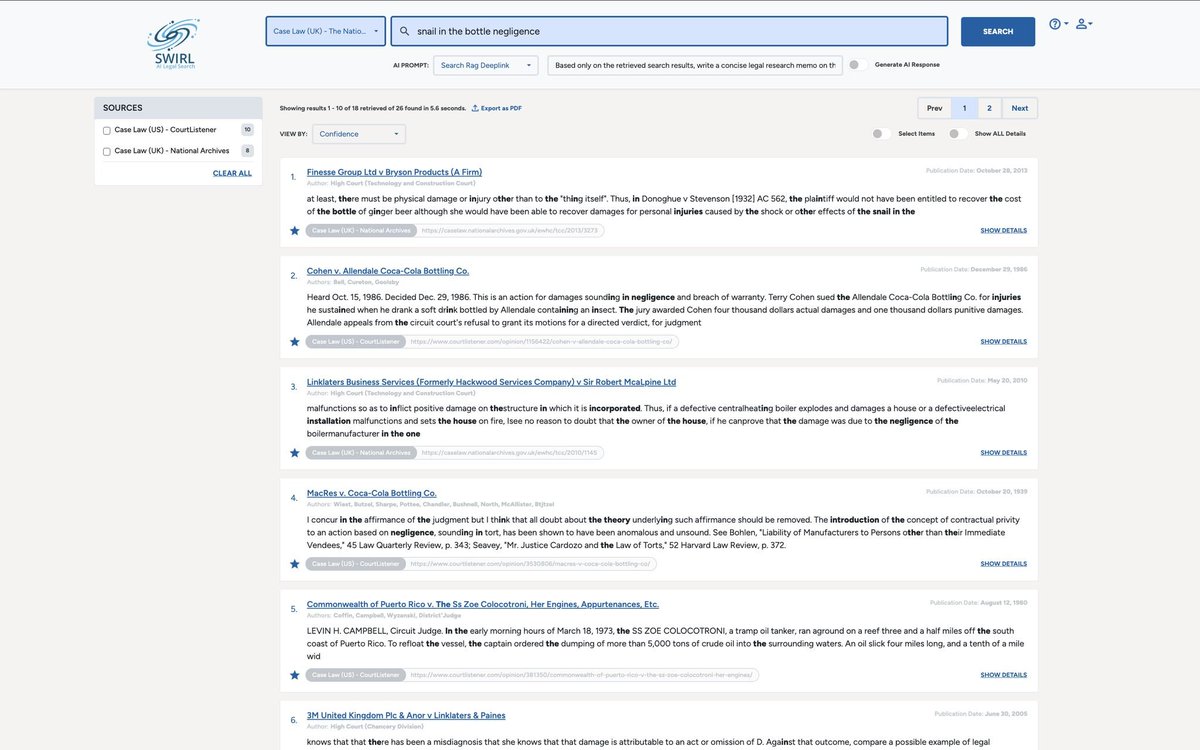
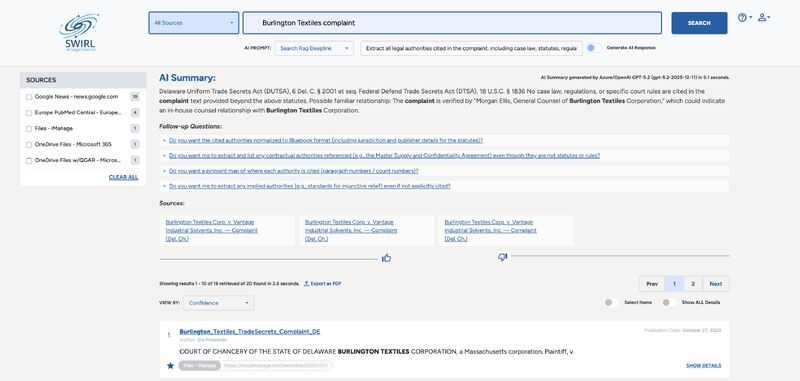
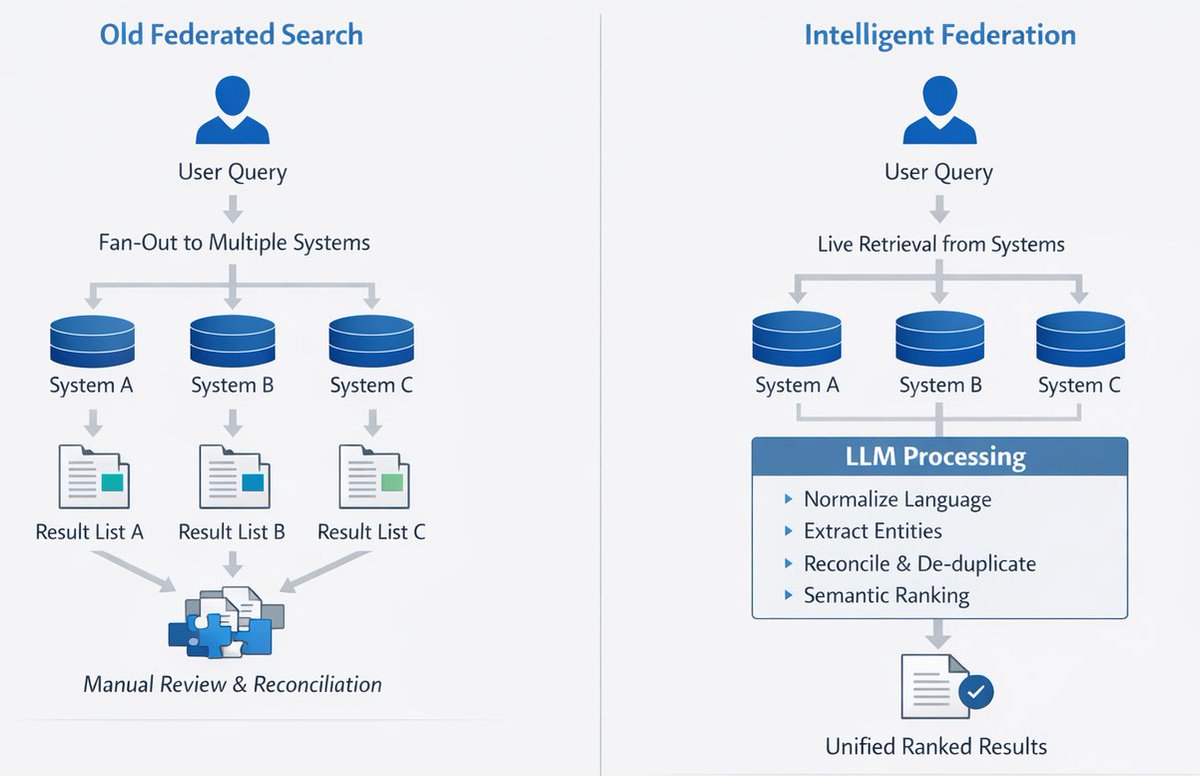
Private AI Search for Law Firms and other highly regulated environments. Speed through data using search - without curation - and use any LLM without lock-in.