Saahil Ognawala retweetledi

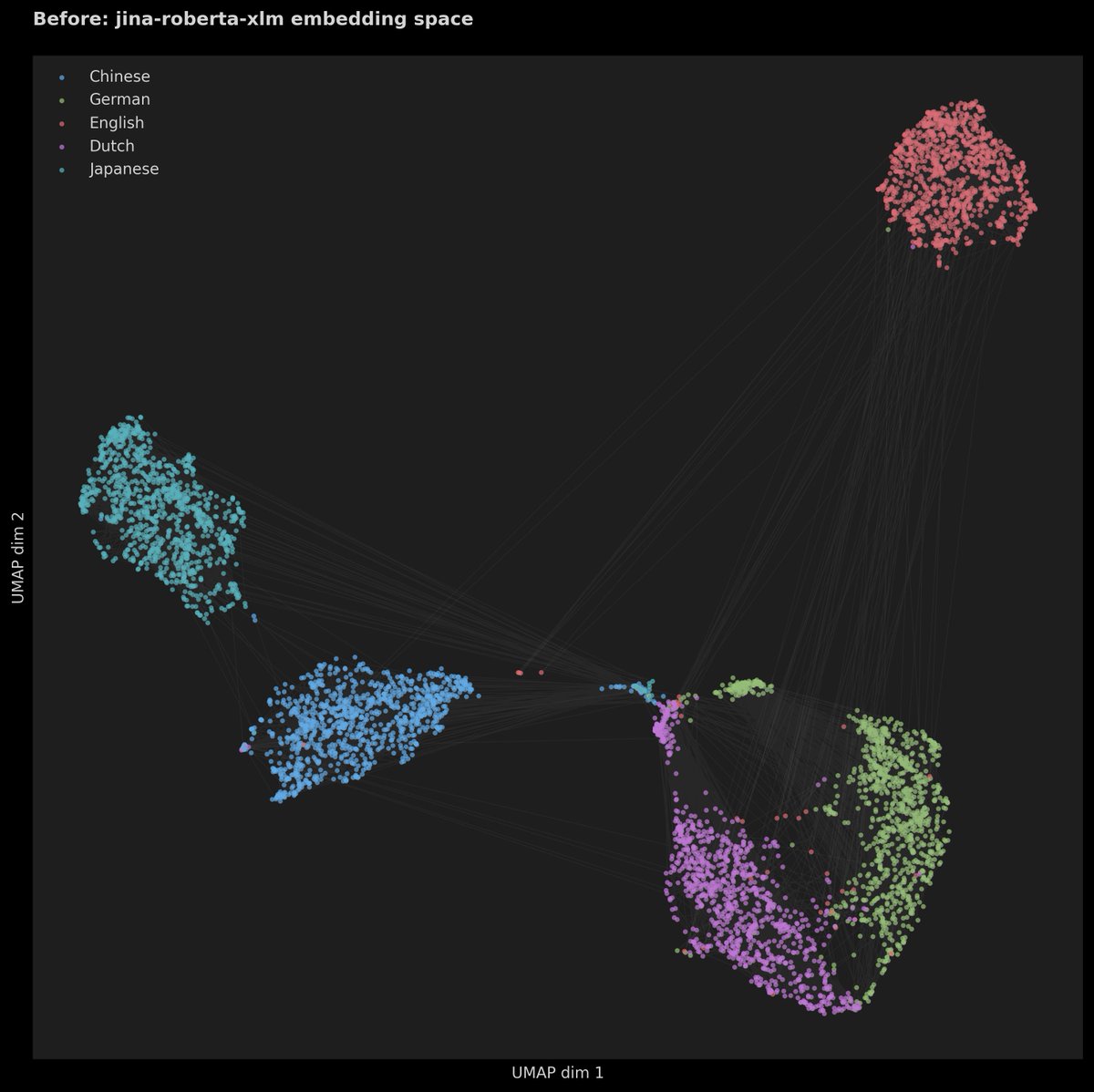
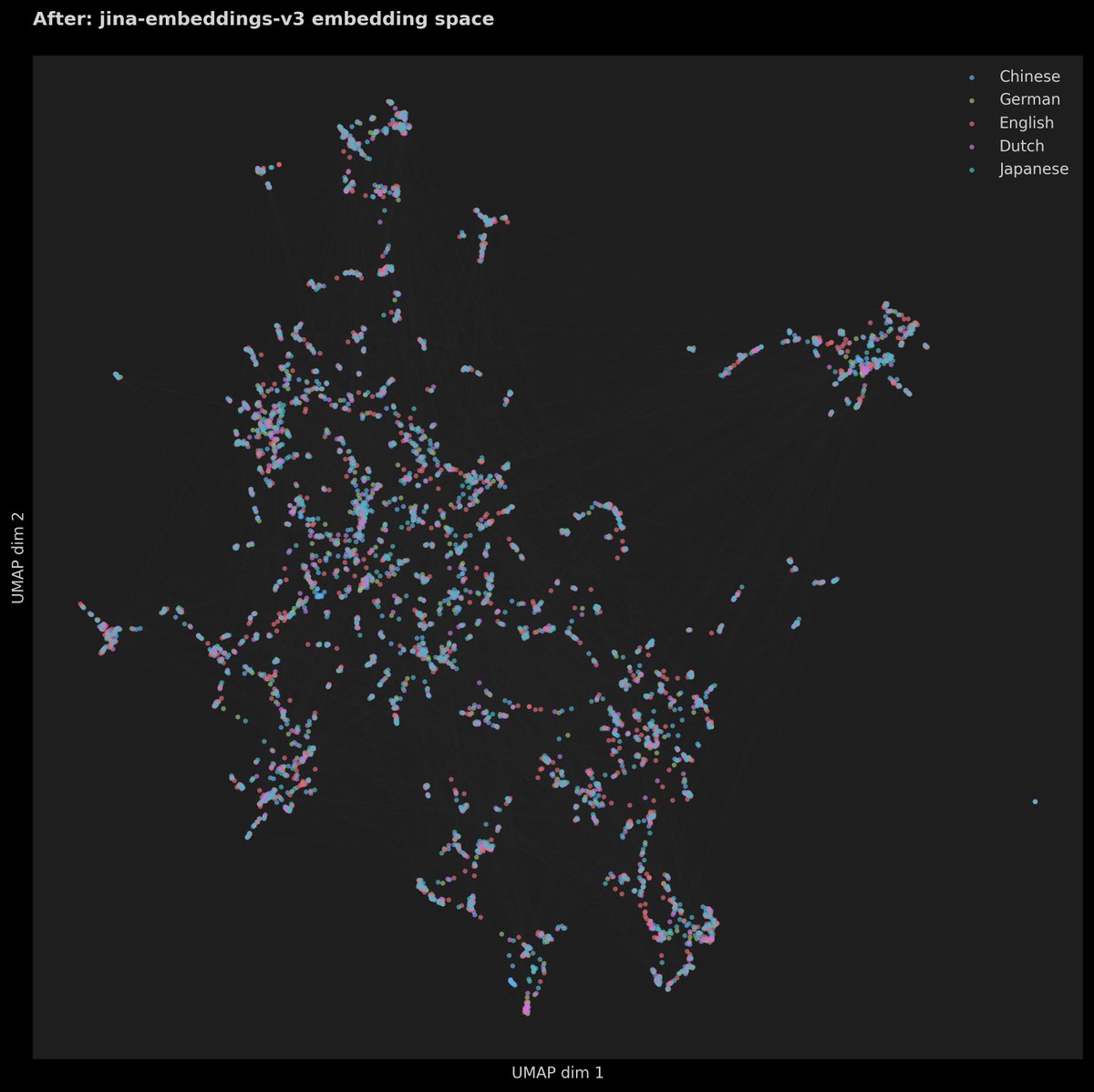
4K. That's the max depth you can hide text to and embedding models can still retrieve it. Beyond that, it's gone. Using jina-embeddings-v3, we reproduced the new Needle-in-a-Haystack from recent NoLiMA paper - by removing literal matches between queries and the relevant information (the needle) hidden in the haystack. We ask ourselves:
- How do embedding models perform retrieval across long-context?
- Can query expansion mitigate this performance gap?

English