Sabitlenmiş Tweet
Sama🌪
4.7K posts


Sama🌪
@SamaHadhod
NLP MSc student @MBZUAI Bla blabla BLA
Katılım Mayıs 2015
750 Takip Edilen644 Takipçiler
Sama🌪 retweetledi

very excited to announce token order prediction has been accepted into ICML 2026!!
see you in Seoul!
very happy with how the paper turned out. we have an updated version of the paper on arxiv, and we’ll have a camera-ready version soon as well: arxiv.org/abs/2508.19228
zed@zmkzmkz
PREPRINT: Predicting the Order of Upcoming Tokens Improves Language Modeling Instead of just predicting the next token, what if an LM also learns to rank the proximity of all future tokens? 🔝 Introducing Token Order Prediction (TOP), an LM auxiliary loss to improve upon MTP
English
Sama🌪 retweetledi

Happy to have this work accepted in ICML 2026 🥳
An arguably simple extra loss that learns the order of upcoming tokens as an alternative of MTP.
See our updated paper for more results and discussion: arxiv.org/pdf/2508.19228
See you in ICML
zed@zmkzmkz
PREPRINT: Predicting the Order of Upcoming Tokens Improves Language Modeling Instead of just predicting the next token, what if an LM also learns to rank the proximity of all future tokens? 🔝 Introducing Token Order Prediction (TOP), an LM auxiliary loss to improve upon MTP
English
Sama🌪 retweetledi
Should we treat LLM benchmarking like an annual Olympiad event?🏆
With current benchmarks, it is too easy to overfit tasks or manipulate settings. In some cases, people just cheat / being narrow-tuned to a specific benchmark (*cough* LLaMa-4)
What if we organized an annual, Olympiad-like event? The tasks must be sealed and unknown. Models cannot study for the test. They must be prepared for anything. We explain this in our new position paper.
I am an IOI alum long time ago. I practiced for years to master many algorithms. I wanted to be ready for whatever appeared on the contest day. I believe general LLMs should face the same standard. If they are truly general, they should be ready for whatever use cases.
We propose a flow similar to how we typically organize an Olympiad:
- Call for Task: We propose an open solicitation for challenging, high-quality tasks from the global research community.
- Organizing Committee: A dedicated team curates and improves these submissions. They verify task quality and diversity.
- Model Developers: Developers submit their systems blindly before the tasks are revealed. This prevents teams from iterative gaming or manual tuning once the exam starts.
- The Actual Olympiad: Evaluation happens in a synchronized, short window. The sealed tasks are released, and all models are tested simultaneously to maintain total integrity under the same setting.
Once it is done, everything will be released for reproducibility.
Read the full position paper here: arxiv.org/abs/2603.23292
We worked on this together with my student @jcblaisecruz
Let me know your thoughts!


English
Sama🌪 retweetledi

New position paper!
📄 "LLM Olympiad: Why Model Evaluation Needs a Sealed Exam"
We argue that NLP needs an Olympiad-style event: seal the problems, freeze submissions, run one harness, release everything for audit.
w/ @AlhamFikri
Paper: arxiv.org/abs/2603.23292
English
Sama🌪 retweetledi
In competitive programming, the post-contest discussion is mainly about the algorithm, not the code
It’s (mainly) a problem-solving contest, yet LLMs are often benchmarked only as coders
We revisited this by evaluating the editorial and reasoning vs end-to-end code generation
Sama🌪@SamaHadhod
(1/9) Excited to share our new paper🥳, Idea First, Code Later: Disentangling Problem Solving from Code Generation in Evaluating LLMs for Competitive Programming.
English
Sama🌪 retweetledi

@SamaHadhod's paper exposes how LLMs struggle with code even after nailing the plan in competitive programming tasks. New editorial-centric benchmark + released ICPC-style problems. Very very cool ngl
Sama🌪@SamaHadhod
(1/9) Excited to share our new paper🥳, Idea First, Code Later: Disentangling Problem Solving from Code Generation in Evaluating LLMs for Competitive Programming.
English
(9/9) Many thanks to my co-authors: Alaa Elsetohy, @fredyhudi, @jcblaisecruz, @Steven7Halim, and @AlhamFikri.
Happy to chat if you’re thinking about reasoning evals for code or CP-style tasks.
English
(8/9)
We release 83 ICPC-style problems with expert-written gold editorials and full official test suites.
Project page: samahadhoud.github.io/idea-first-cod…
arXiv: arxiv.org/abs/2601.11332
Dataset: huggingface.co/datasets/samah…
English

Sama🌪 retweetledi
1/11 Proud to share our new paper: SENSIA (SENse-based Symmetric Interlingual Alignment) — a sense-based approach to multilingual adaptation.
Goal: explicit representation-level alignment of meaning.
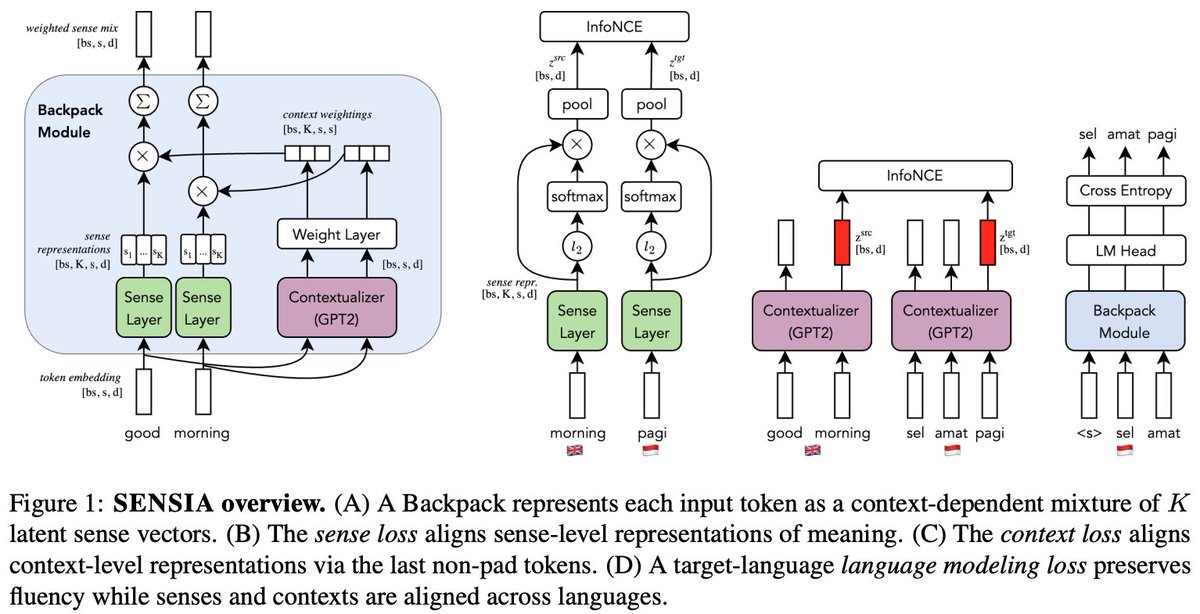
English
Sama🌪 retweetledi

Sama🌪 retweetledi
🎉Silver for @mbzuai at ACPC!!🥈
We also topped the Gulf rankings
Amazing performance by our 1st year UG students in our very first participation
Next: ICPC World Finals 2026🤞

English
Sama🌪 retweetledi


Sama🌪 retweetledi

