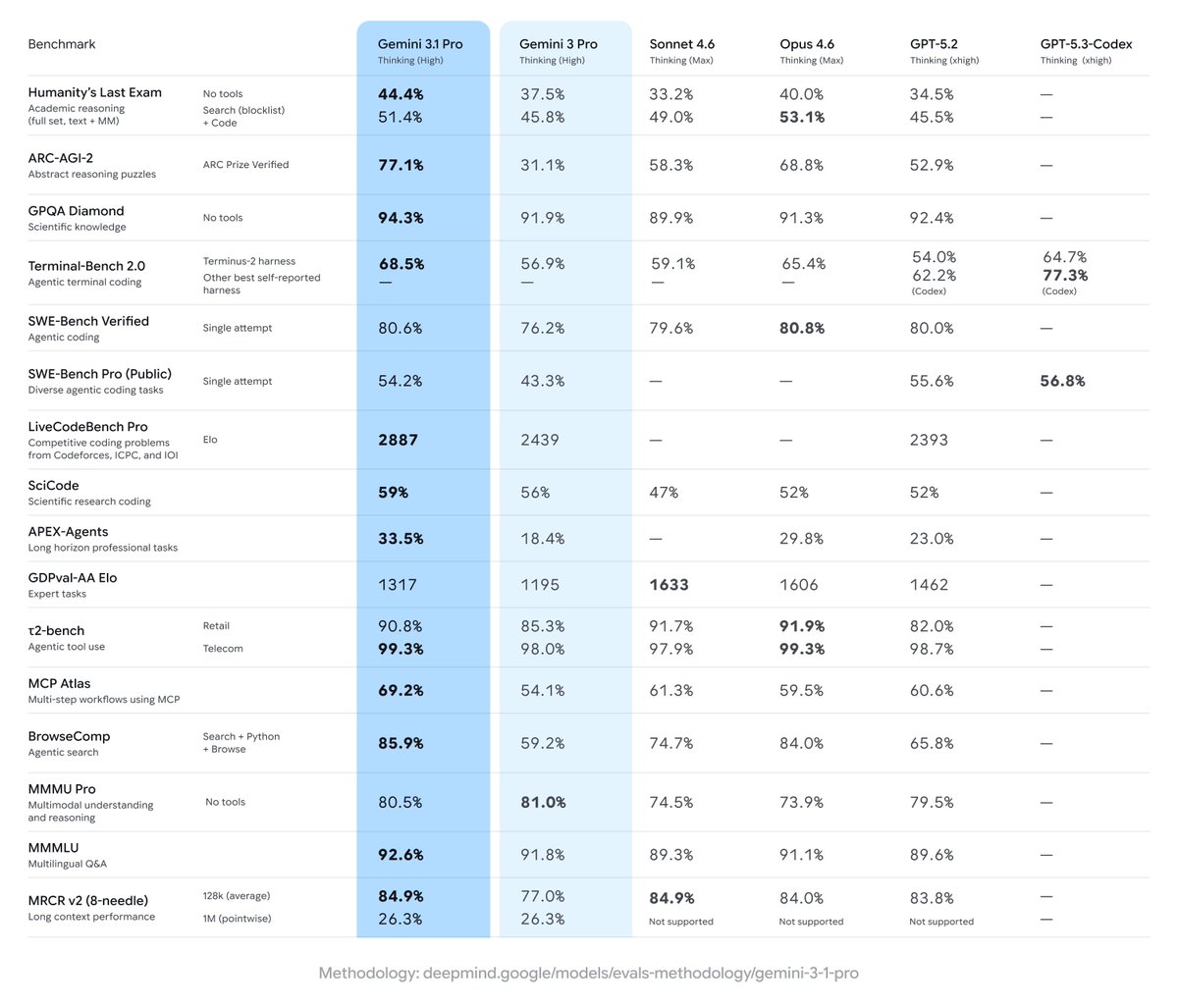
I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks, including 10 of 12 popular text and reasoning benchmarks, 9 of 9 image understanding benchmarks, 6 of 6 video understanding benchmarks, and 5 of 5 speech recognition and speech translation benchmarks. Gemini Ultra is the first model to achieve human-expert performance on MMLU across 57 subjects with a score above 90%. It also achieves a new state-of-the-art score of 62.4% on the new MMMU multimodal reasoning benchmark, outperforming the previous best model by more than 5 percentage points. Gemini was built by an awesome team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google, and is one of the largest science and engineering efforts we’ve ever undertaken. As one of the two overall technical leads of the Gemini effort, along with my colleague @OriolVinyalsML, I am incredibly proud of the whole team, and we’re so excited to be sharing our work with you today! There’s quite a lot of different material about Gemini available, starting with: Main blog post: blog.google/technology/ai/… 60-page technical report authored by th Gemini Team: deepmind.google/gemini/gemini_… In this thread, I’ll walk you through some of the highlights.