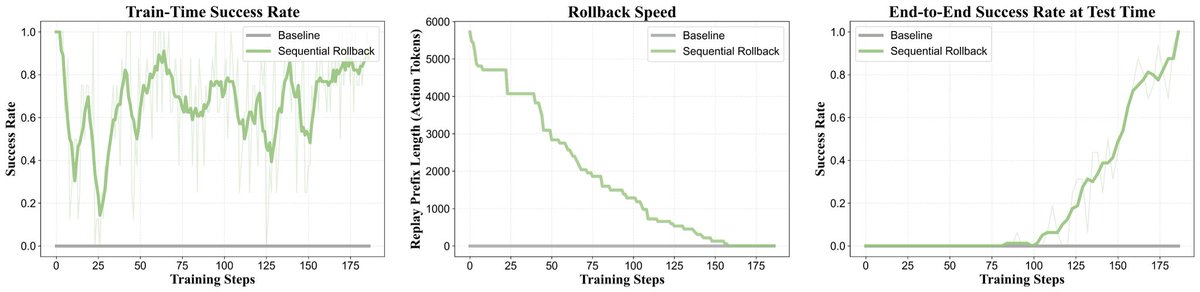
The experimental results show that Rollback strategy enables RL training on extremely hard agentic tasks where the agent initially never completes the task end to end.
Are you also struggling with RL on long-horizon, high-difficulty agentic tasks, especially when positive rewards are sparse? Check out the latest blog from the ROLL team: warm-pajama-44a.notion.site/Save-Load-and-…