Sabitlenmiş Tweet

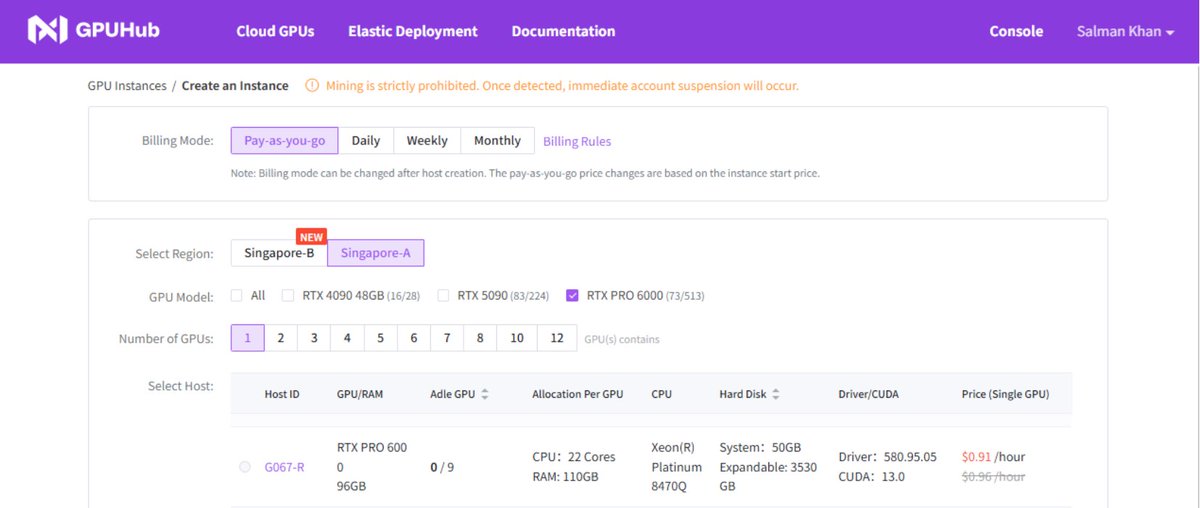
After a few months of bouncing between Vast.ai, AWS, and GPUHub for ML experiments, I stopped asking “which one is cheapest?” and started asking:
👉 “Which one wastes the least mental bandwidth per experiment?”
English
Shaddowles | AI & GPU
190 posts

@Shaddowles
Building AI systems ⚡ GPU • Infra • ML Speed is the advantage