Sabitlenmiş Tweet

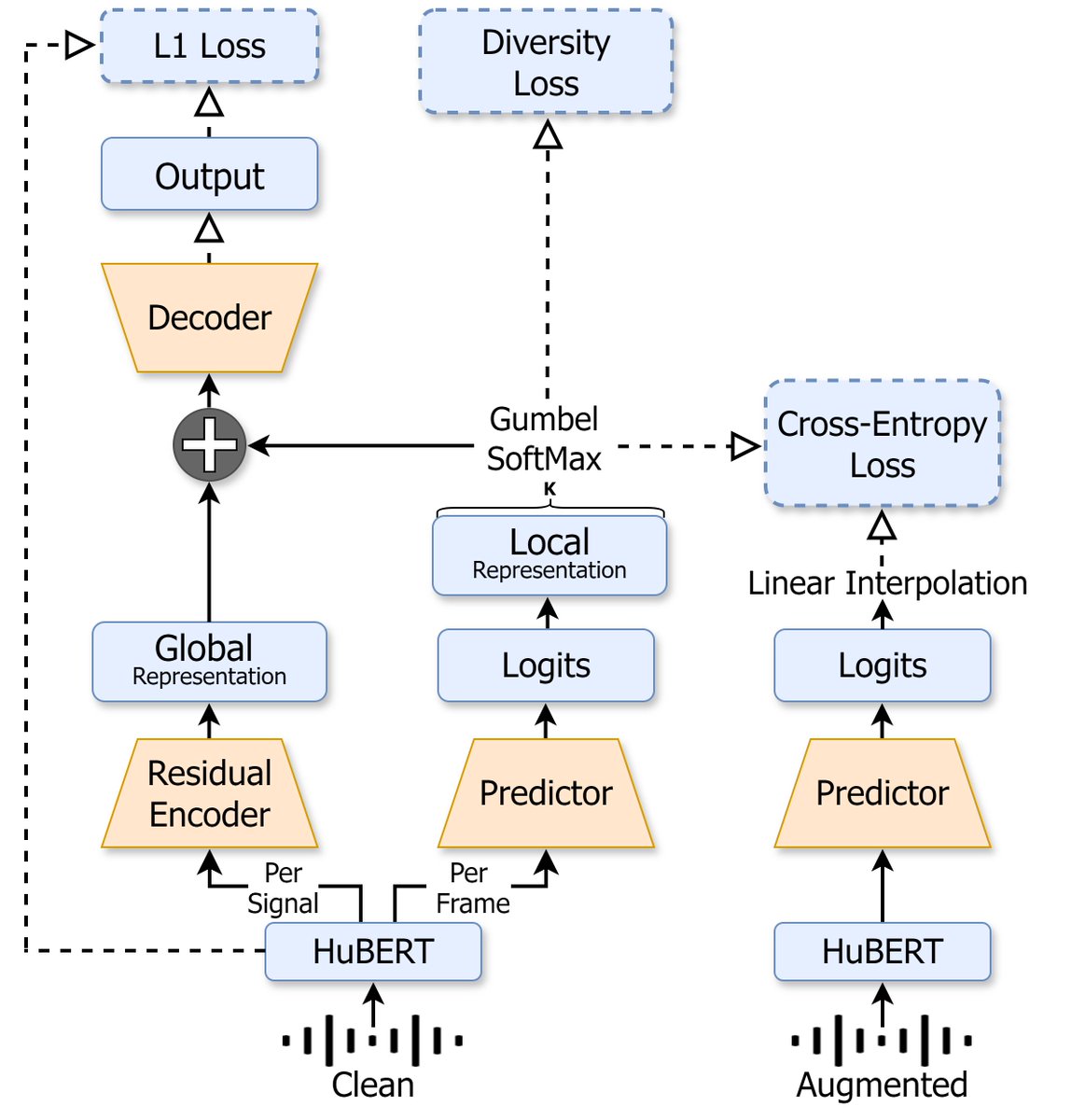
🚨I’m excited to share our #INTERSPEECH2024 paper "NAST: Noise Aware Speech Tokenization for Speech Language Models” 🥳 W/ @adiyossLC
Paper-arxiv.org/abs/2406.11037
Code-github.com/ShovalMessica/…
English
Shoval Messica
15 posts
@ShovalMessica
Audio & Speech MSc student at HUJI @cseHUJI

It's time to look past dictionary learning for decomposing LM activations. What happens when we instead leverage local geometry? We find a natural region-based decomposition that yields better steering and localization 🧵 1/






🚨I’m excited to share our #INTERSPEECH2024 paper "NAST: Noise Aware Speech Tokenization for Speech Language Models” 🥳 W/ @adiyossLC Paper-arxiv.org/abs/2406.11037 Code-github.com/ShovalMessica/…




