@natolambert Agree. I once heard @srush_nlp described cursor as a RL company then I knew they were aiming for big things.
English
Shuaichen Chang
566 posts
@ShuaichenChang
Researcher at AWS AI (@AmazonScience) Ex: PhD @OhioState Opinions are my own #NLProc #LLMs #AI


ByteDance also implemented attention over depth. They literally combined it with sequence attention.

🎾Introducing LATENT: Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data Dynamic movements, agile whole-body coordination, and rapid reactions. A step toward athletic humanoid sports skills. Project: zzk273.github.io/LATENT/ Code: github.com/GalaxyGeneralR…



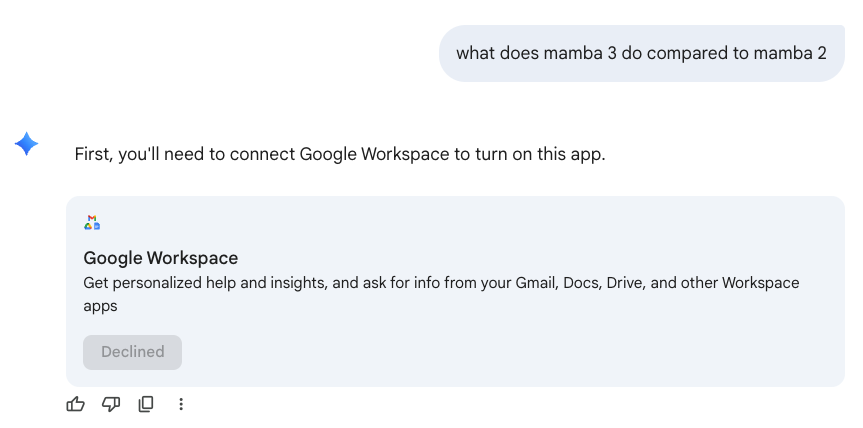
Codex is randomly hitting me with some ancient wisdom... for some reason.


Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.





Introducing Olmo Hybrid, a 7B fully open model combining transformer and linear RNN layers. It decisively outperforms Olmo 3 7B across evals, w/ new theory & scaling experiments explaining why. 🧵