
Dr. Shuhan He 🫀🫁
2.7K posts

Dr. Shuhan He 🫀🫁
@shuhanhemd
MGH/Harvard. Clinical informatics. Emergency Med. Lab of Computer Science. @Conductscience @mghihp Director Health Data analytics.
Cambridge, MA Katılım Ekim 2012
3.2K Takip Edilen2.1K Takipçiler

AutoResearch only works when you can measure the result with a number
but what about writing, arguments, marketing copy? theres no score for "is this convincing"
SHL0MS built AutoReason to solve this
instead of a metric, it uses a loop of agents arguing with each other:
> one writes a draft
> another critiques it (no fixes, just problems)
> a third rewrites it based on the critique
> a fourth merges the best parts of both
> a blind judge panel picks the winner
> loop until nothing beats the current version
every agent gets fresh context so no confirmation bias builds up
in testing, autoreason scored 35/35 on a blind panel. the next best method scored 21
same idea as autoresearch but instead of optimizing a number, its optimizing through debate

𒐪@SHL0MS
i've been working on a method called autoreason that is effectively autoresearch extended to subjective domains. autoresearch works because val_bpb gives you an objective fitness function. autoreason constructs a subjective one through independent blind evaluation, the same way science uses peer review where math can use proofs. as you’ve noted, the fundamental problem with using LLMs for iterative refinement on subjective work: the model is always sycophantic when you ask it to improve something, overly critical when you ask it to find flaws, and overly compromising when you ask it to merge two perspectives. the output ends up shaped more by how you prompt than by what's actually better. autoreason fixes this by separating every role into isolated agents with no shared context. you start by generating version A. a fresh agent attacks it as a strawman. a separate author who only sees the original task, version A, and the strawman critique produces version B. a third agent who has no history with either drafting process sees both versions as equal inputs and synthesizes them into version AB. a blind judge panel with fresh context and randomized labels picks the strongest of A, B, or AB. the winner becomes the new A and the loop repeats until the judges consistently pick the incumbent which indicates that no further changes are needed.
English
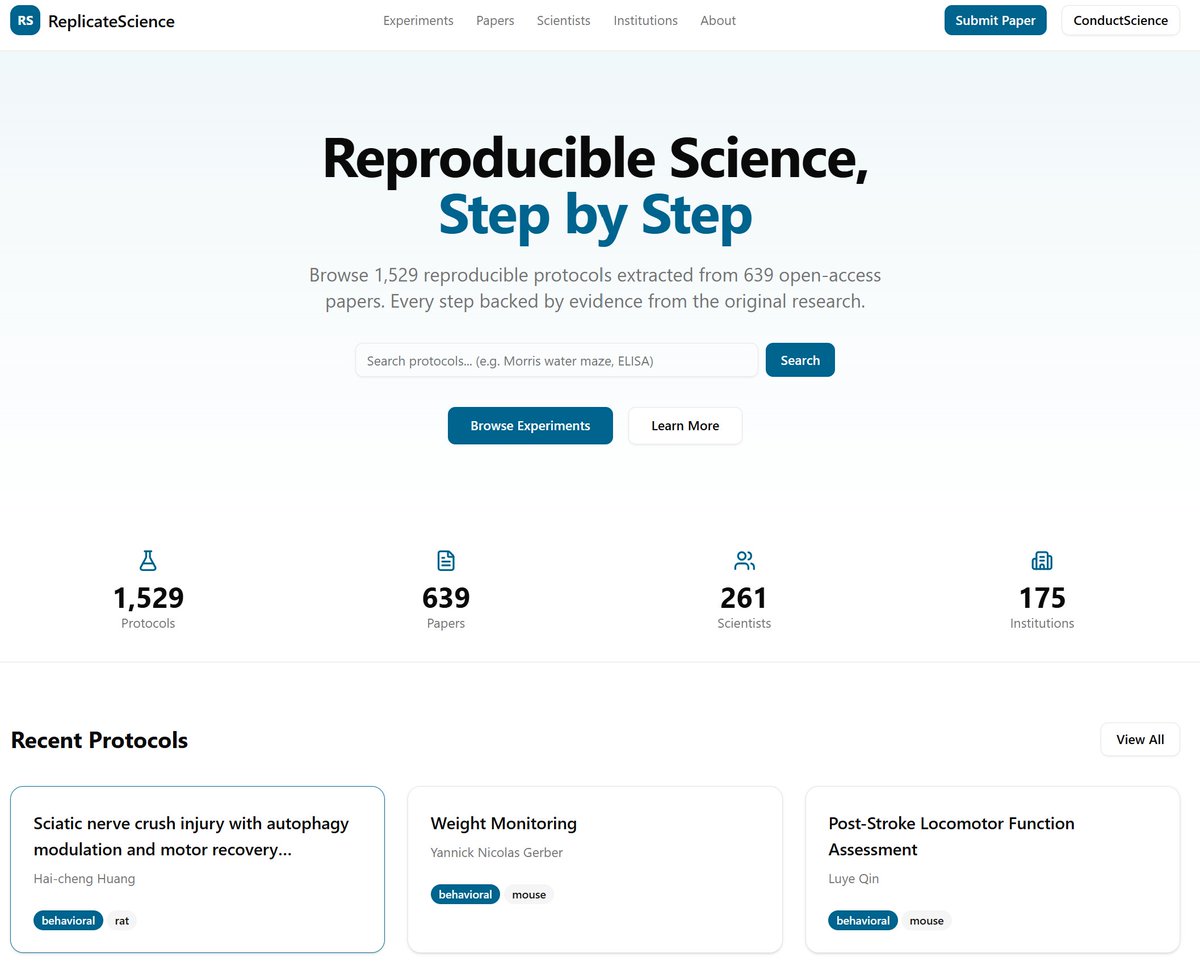
I am a physician and a researcher. I also build software. And the longer I spent in all three of those worlds, the more one thing became impossible to ignore: science methodology is the most important part of research, and it is the least developed as infrastructure.
In software, we solved this problem 20 years ago. Code is versioned. Pipelines are automated. Tools compose. You can call a function from a terminal, chain it into a workflow, test it, diff it, deploy it. The entire discipline is built on the principle that process should be reproducible by design, not by memory.
Science has never had that. A protocol is a document. It lives in a methods section written in passive voice prose, in a PDF nobody can query, in a Word file on someone's desktop. More than 70% of researchers have tried and failed to reproduce another lab's experiment. That failure is not because scientists are careless. It is because the tools we use to describe methodology were never designed to be instructions. They were designed to satisfy journal reviewers.
ReplicateScience started as an answer to a simpler problem: take open-access papers, pull the methods, and turn them into something a person can actually follow. Structured steps, evidence quotes from the original text, equipment mapped to real suppliers. That part exists today, across 1,529 protocols from 639 papers.
But the reason I keep building it is the bigger problem. I want science methodology to become programmable infrastructure. Not a UI you browse, but a protocol layer you can query from a terminal, integrate with ML pipelines, version like code, and trigger from automated systems. The kind of thing where a behavioral rig can advance a protocol step based on sensor output, or where a lab can diff their actual procedure against the canonical one and log the deviation automatically.
That is what software engineering already is. Science deserves the same primitives.
English
SO proud of @AlisterFMartin. He will do INCREDIBLE things in NYC
Maya Kaufman@mayakauf
NEWS: @NYCMayor @ZohranKMamdani names @AlisterFMartin as the next commissioner of the Department of Health and Mental Hygiene. Martin is an ER physician known for spearheading a national campaign, "Vot-ER," to register patients to vote. subscriber.politicopro.com/article/2026/0…
English
Dr. Shuhan He 🫀🫁 retweetledi

Minnesota has been the best source for comedy in the nation this past year.
The Somali Waltz
English

My new Biosketch Personal Statement. Constructive feedback welcomed !

English
@silvirouskin You'll need take a nap after a full drink it's so rich and chocolatey 🍫🍫🍫
English
Updating to the new scienceCV , wishing we had a chocolate dispenser in lab🥺
English
@silvirouskin @anshulkundaje @silvirouskin's interpretation is mine as well, I asked GPT all the ways to get around it and SciENcv makes it clear it should only have 5
English
@anshulkundaje Nope, not according to the instructions I see , you can only refer to the 5 others..

English
Guys this is bad. The new SciENcv biosketch caps us at just 10 total citations—5 tied to the project and 5 for Contributions to Science—which severely devalues collaborative work where impact is spread across many middle/co‑first author papers. This new SciENcv format actively discourages collaboration. It forces us to remove most middle and co‑first author papers, so instead of spending time building team science, we will be pushed to chase last‑author slots just to stay visible on paper. When reviewers compare CVs side‑by‑side, the person whose five allowed citations are all last‑author papers will always look “stronger” than the equally productive collaborator whose impact is spread across many middle‑author publications, and that is exactly how you end up skewing funding away from collaborative science… I personally think this is a big mistake especially now when no single lab has all the expertise.
English
@NikoMcCarty How about an article on the history of mouse mazes ?
English

It is by studying non-model organisms that biotechnologists have, historically, found the most useful tools.
Taq polymerase and CRISPR were both discovered in weird extremophiles. GFP was first isolated from jellyfish caught off the coast of Friday Harbor, Washington. Luciferase came from the North American firefly. Rapamycin, an immunosuppressant used in organ transplants, came from Easter Island soil microbes.
Many more useful discoveries are surely awaiting, if only we could grow the many lifeforms that nobody has yet studied in any meaningful way.
For my latest @AsimovPress column, I explain how @CultivariumFRX developed a robot that can transform (or get DNA into) all kinds of new, non-model microbes, thus expanding the slice of nature we can study in the laboratory. I think it could be a really big deal for biology.


English
Dr. Shuhan He 🫀🫁 retweetledi

I’m very happy to share the final version of this, now published in @Nature
rdcu.be/eY5nh
Hippocampal neurons that initially encode reward shift their tuning over the course of days to precede or predict reward.
Mark Brandon, PhD.@markbrandonlab
I am excited to share our latest research led by PhD student Mohammad Yaghoubi (@yaghoubi_mh) entitled: “Predictive Coding of Reward in the Hippocampus” Link: biorxiv.org/cgi/content/sh… Highlights: 🧵👇
English
@AsimovPress turn methods into referrals for vendors and remove OA/publishing fees entirely.
English

New Essay: Inventing the Methods Section
Many science methods are difficult to understand or replicate. The U.S. alone invests ~$28 billion annually in irreproducible biomedical research.
How have methods evolved over four millennia, and how can we make them better? By @Andrew_C_Hunt.
Read: press.asimov.com/articles/metho…

English
Dr. Shuhan He 🫀🫁 retweetledi

The Maria Orsic Story🧐🤔🛸🛸🛸🛸🛸
Maria Orsic's story is a fascinating blend of mysticism, occultism, and conspiracy theories. Born on October 31, 1895, in Zagreb, Croatia, Maria was a medium who claimed to have received telepathic messages from extraterrestrial beings from Aldebaran, a star system 68 light-years away in the constellation Taurus.
Maria moved to Berlin, Germany, where she became involved in spiritualism and occultism.
Founded the Vril Society with other female mediums, focusing on contacting extraterrestrial beings and acquiring advanced technology.
Claimed to have received messages from Aldebaran, providing technical data for constructing flying machines.
Allegedly worked with Nazi scientists on advanced projects, including flying saucers.
Vanished in 1945, with theories she escaped to Aldebaran or South America.
Some believe Maria was a medium for benevolent "Space Brothers" guiding humanity.
Others see her as a pawn in Nazi occultism and advanced technology conspiracies.
The Vril Society's work has been linked to Nazi Germany's interest in flying saucers
English
@DrJBhattacharya Agree on disclosure. I also think that "science=paper = text” is an outdated constraint. It can also be code, protocols, datasets, interactive figures, registries, and methods. Text can be the narrative that explains the evidence, not the evidence itself.
English

Right now, there is no technology to always accurately distinguish scientific papers written using AI from purely human papers. But this may change in the future. Be honest about AI use in your papers now. It's the safest path to avoiding future accusations of AI plagiarism.
English
@bhalligan @robgo I see no reason to not lean into more biotech as it becomes more compute and bio/clinical informatics heavy. Eventually it just becomes AI anyways.
English

@robgo I'm not sure Suno started as a consumer company. They pivoted to it. I forget where they started.
English
I’m starting to worry about Massachusetts
1. Biotech is way off from a few years ago
2. Only 1 of the top 50 ai companies are in MA
3. The Fed research funding cuts hitting MIT, Harvard, Whoi are brutal.
4. The millionaires tax is working in the short run, but I know a lot of wealthy folks preparing for a FL move.
5. A glut of empty condos
6. It’s not “cool” for young folks
7. It’s expensive as sh-t.
I honestly don’t think the MA/Boston govt can do that much about it as they are kind of macro issues. I give them big credit for working on building more housing and fixing the T, which will help.
I’m trying to help w HubSpot, partnering w WHOI, teaching at MIT. I’d like to help more. Specifically I’d like to encourage and help more ai and climate companies in the state. I think ai and climate should be our dual growth engines.
English
Emergency medicine is uncertainty management.
In a new Nature Scientific Reports paper, we used Shannon entropy to measure how much individual symptoms, exam findings, and tests actually narrow the differential.
Across 405 clinical features, most changed uncertainty very little. A smaller subset meaningfully shifted diagnostic thinking, sometimes in ways not captured by sensitivity or specificity.
We introduce entropy removal as a complementary metric for diagnostic value at the bedside.
@david126 @CoryRohlfsen @AdrianaColeska
English