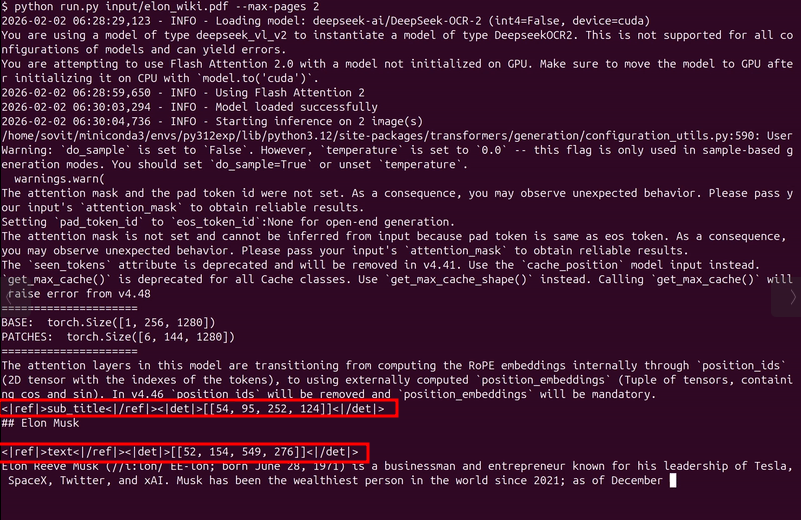
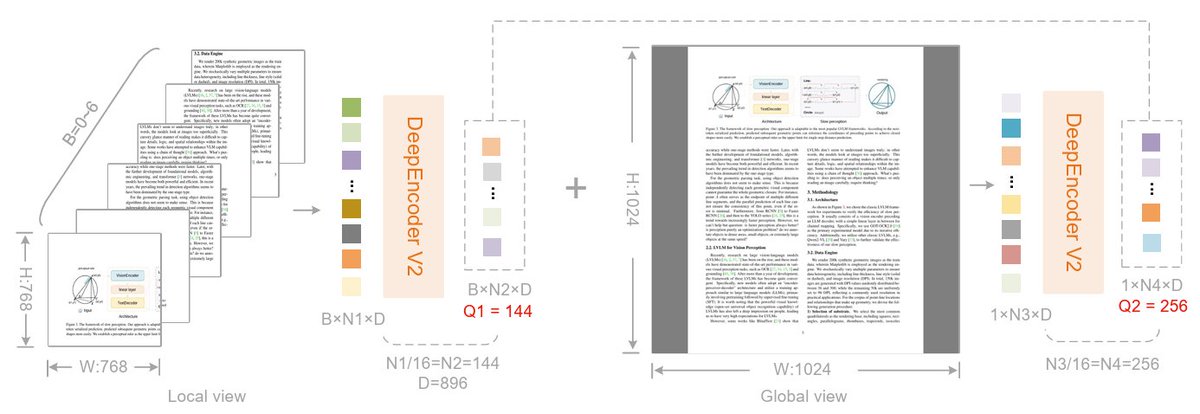
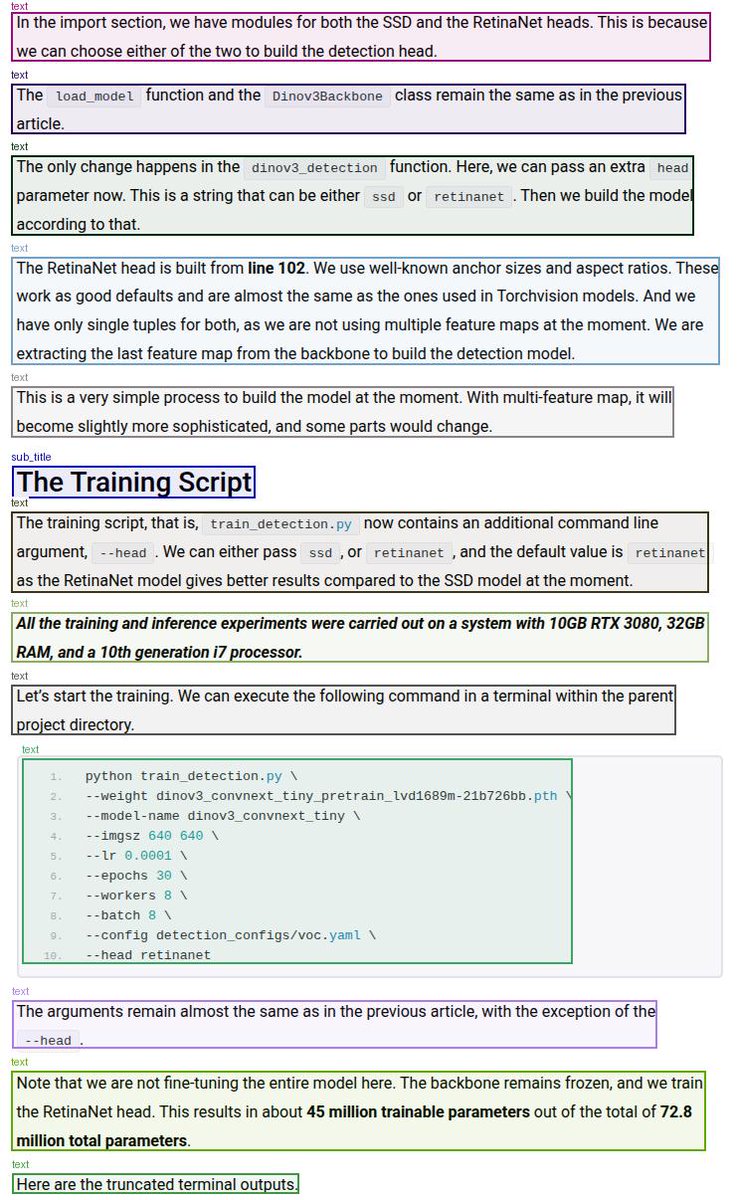
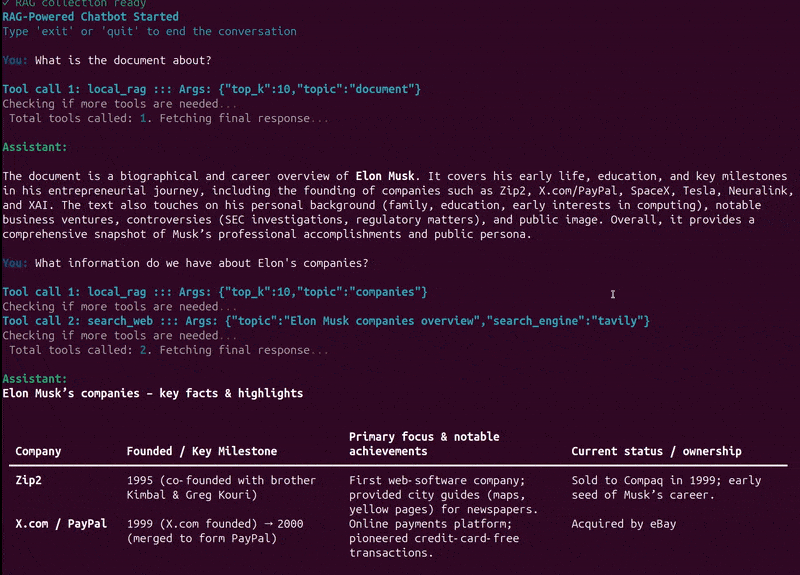
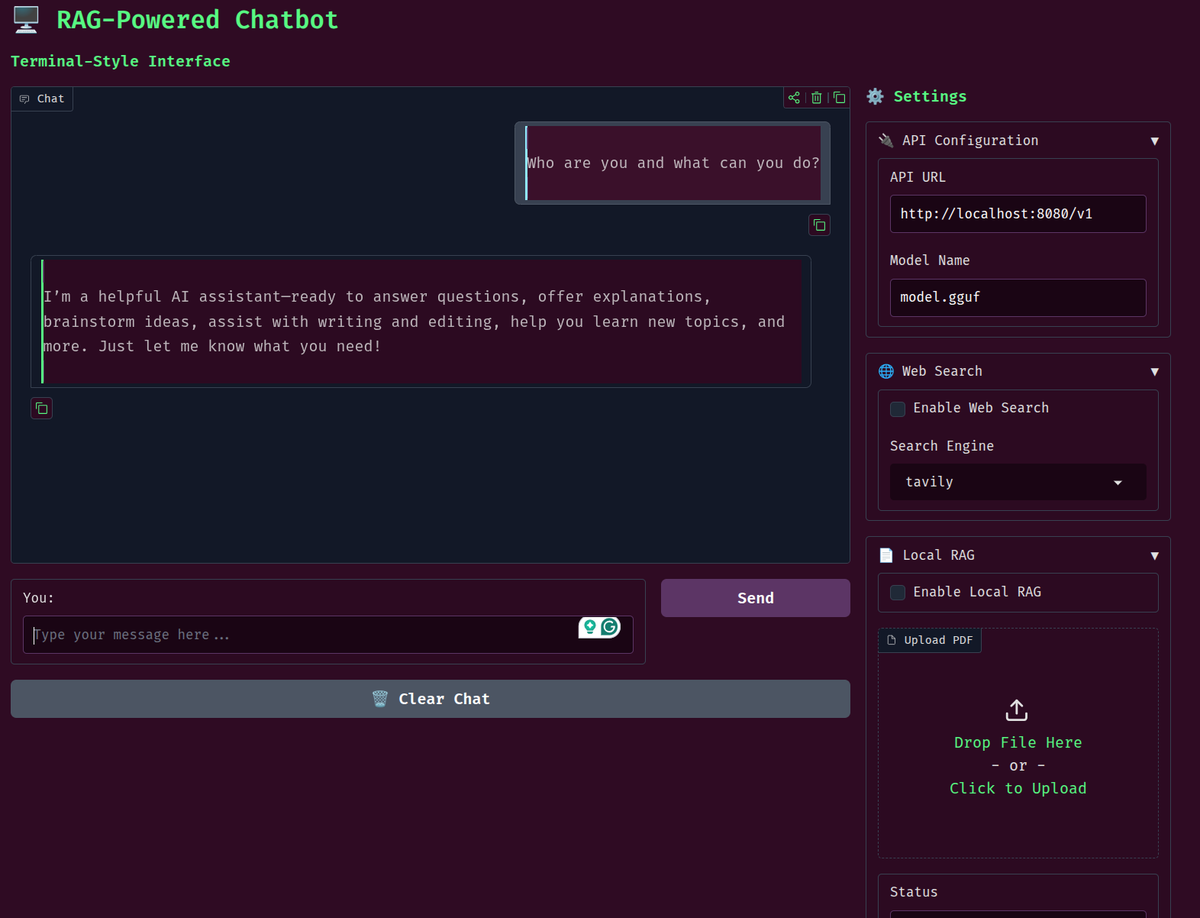
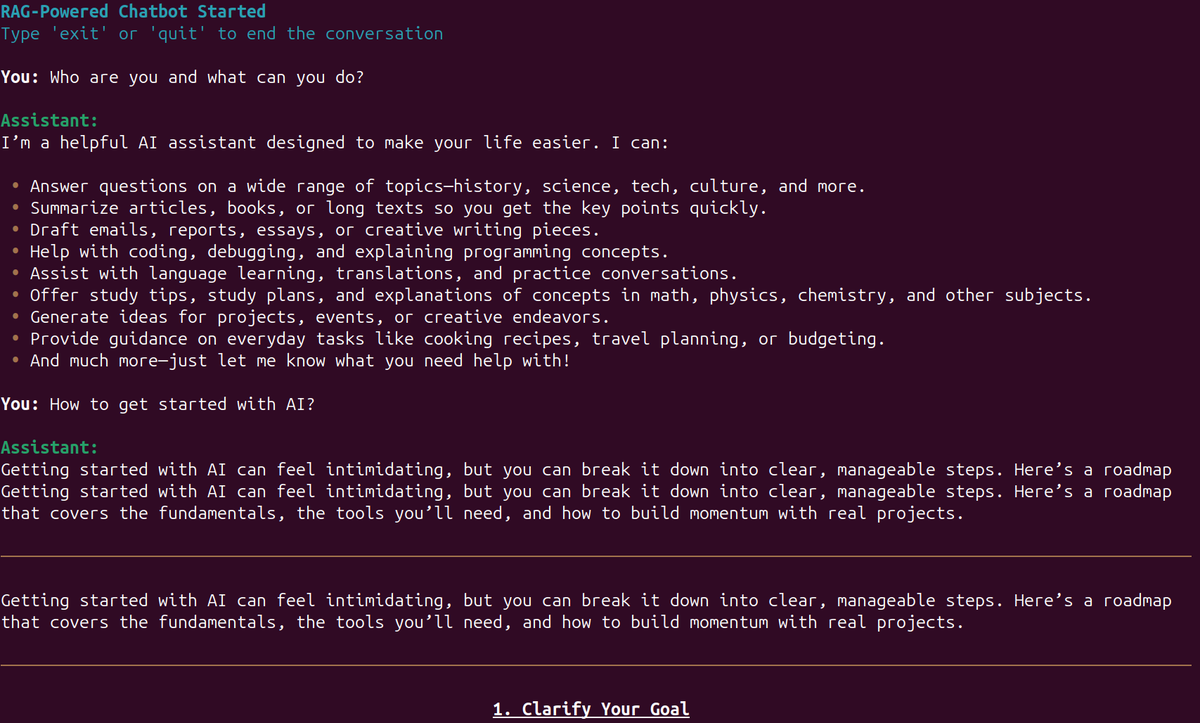
What are we going to cover while fine-tuning DeepSeek-OCR 2?
* Preparing the Hindi-language dataset and splitting it into training and test sets.
* Training the DeepSeek-OCR 2 model on the dataset using the Unsloth library.
* Analyzing performance via validation loss.
English