Sabitlenmiş Tweet

Arthur Sarazin
1.9K posts
@SrzArthur
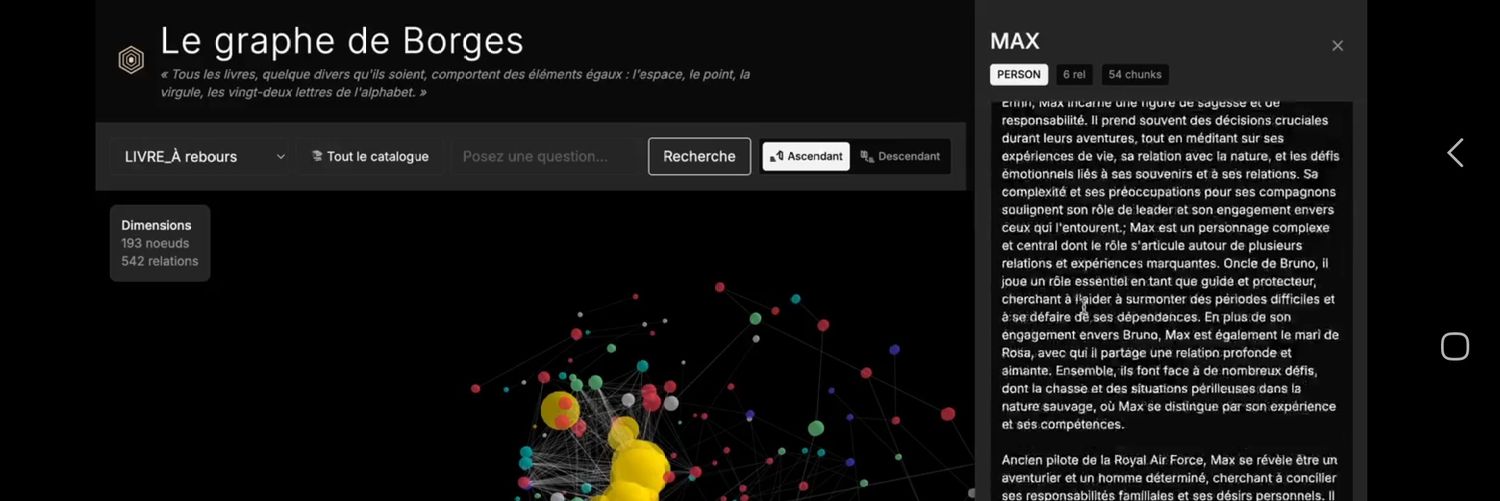
IT, Governance and Design 🧐 | Ongoing designer of Le Graphe de Borges 📚



The overlooked truth about RAG in the LLM era: the query is just as important as the retrieval system. With BM25 and a solid query augmentation system, you can virtually retrieve anything.

Coucou ! Vous êtes à quel niveau d’études et vous faites quoi comme métier actuellement ? +salaire svp