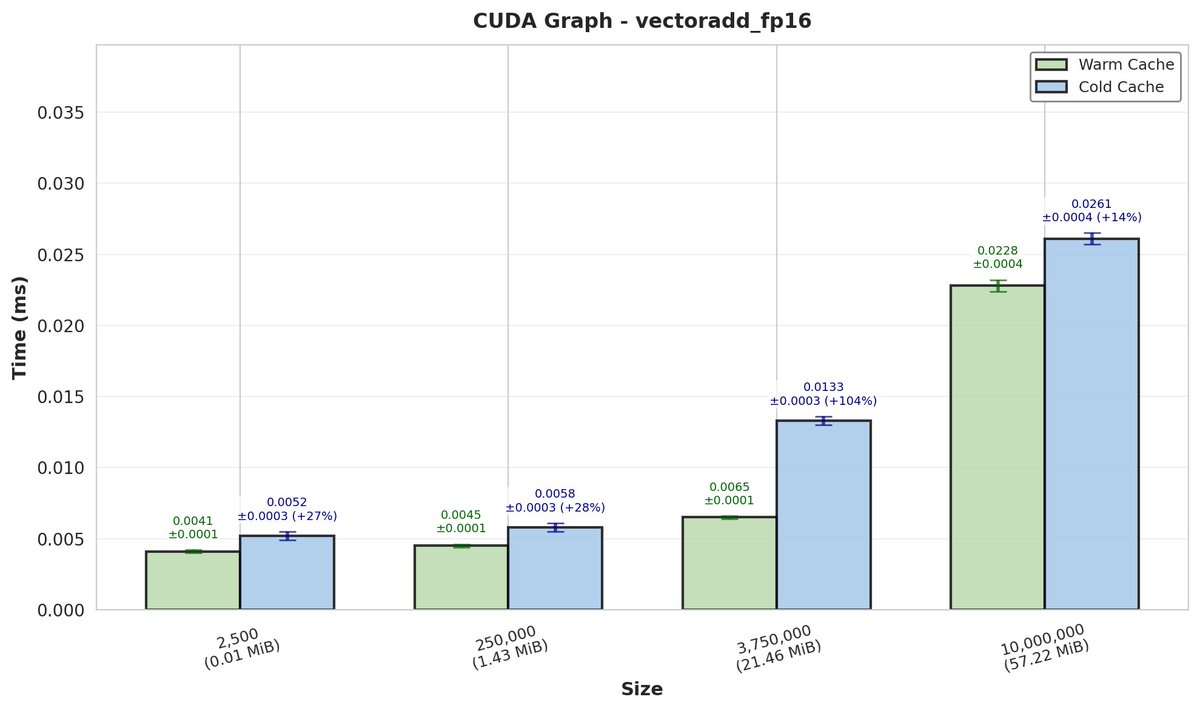
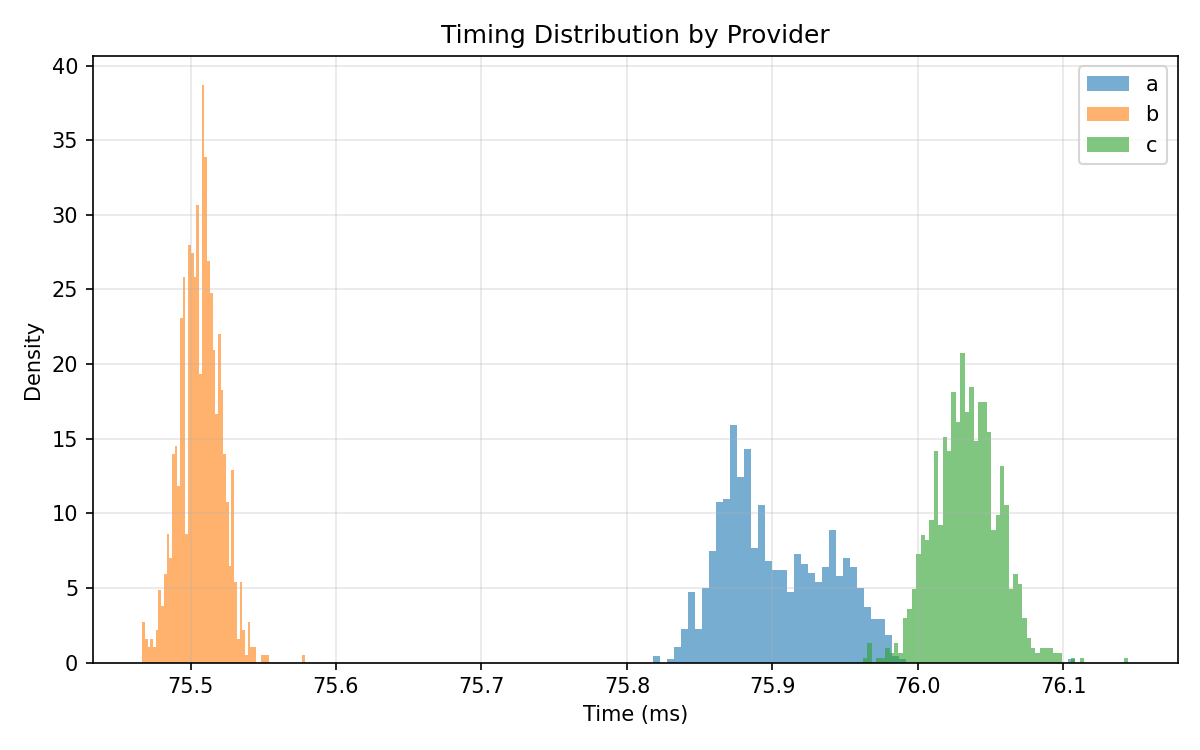
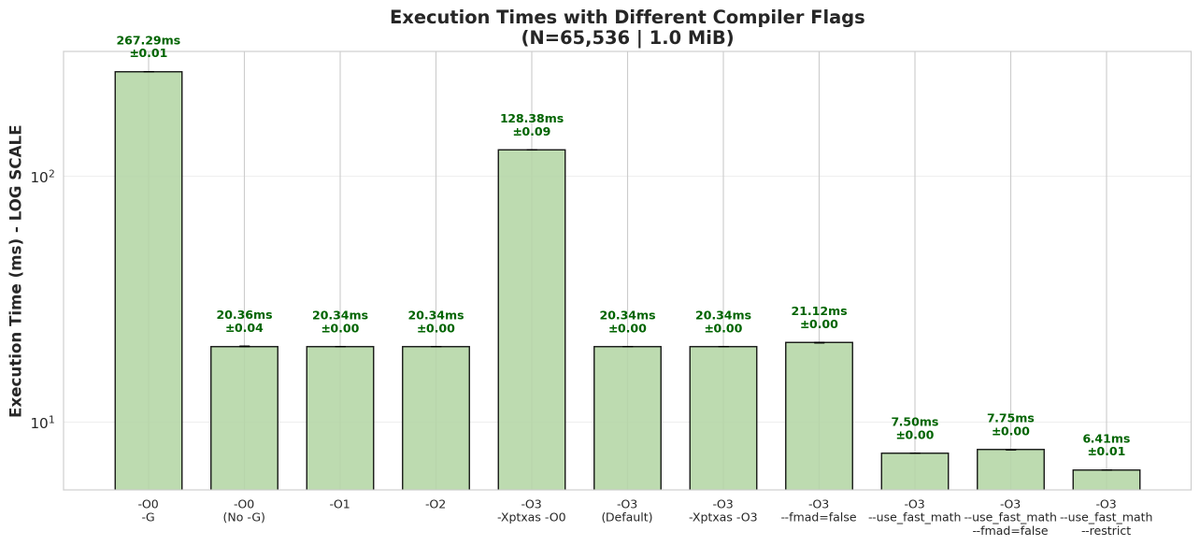
Full post at standardkernel.com/blog/reimagini… (5/5)
English
Standard Kernel Co.
21 posts

@Standard_Kernel
Building AI Infrastructure with AI; fast kernels go brrr






Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.

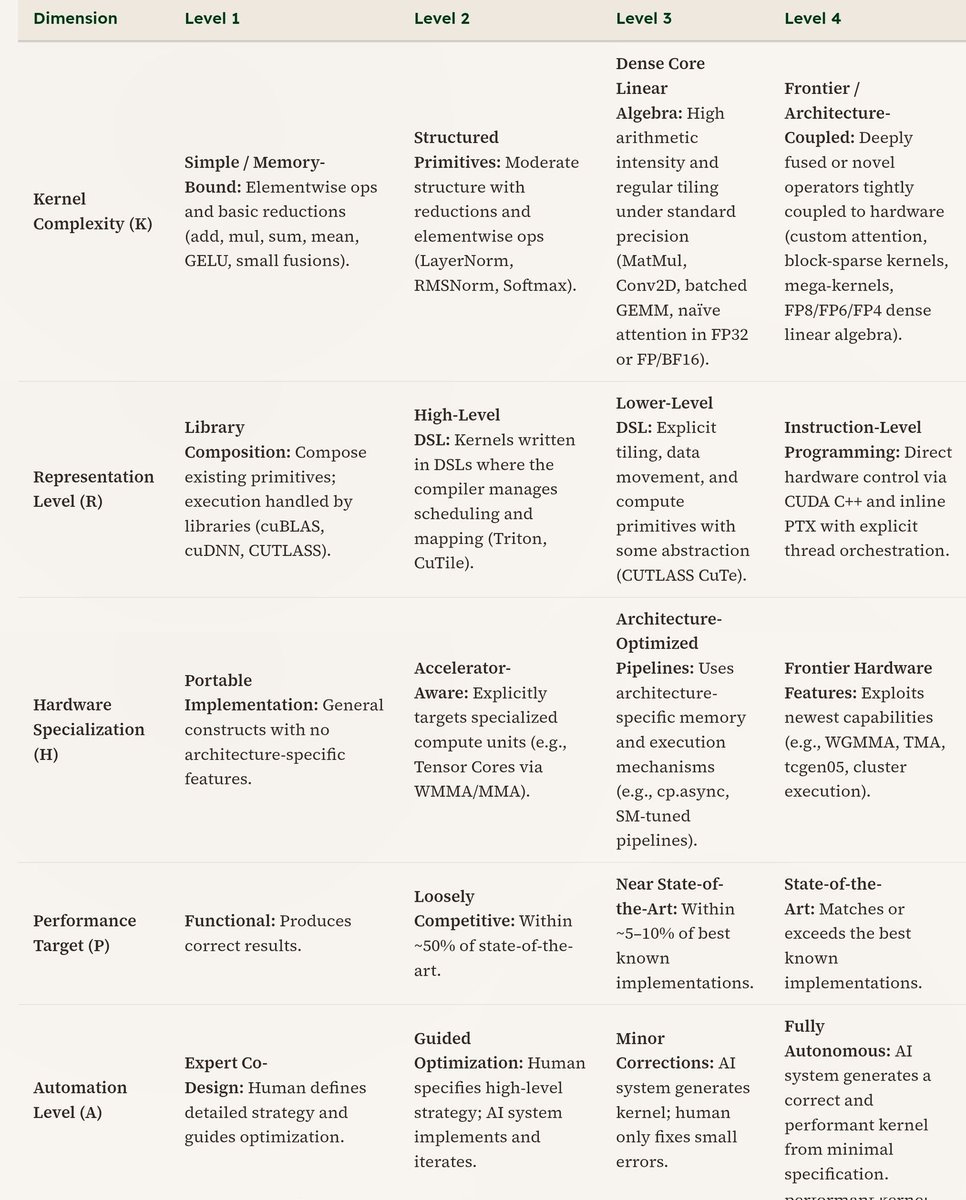
Excited to share @Standard_Kernel's seed round and some reflections on what we’ve learned about kernel generation and what we believe is next. Grateful to our amazing team, supporters, and the broader community pushing this space forward.