Sabitlenmiş Tweet

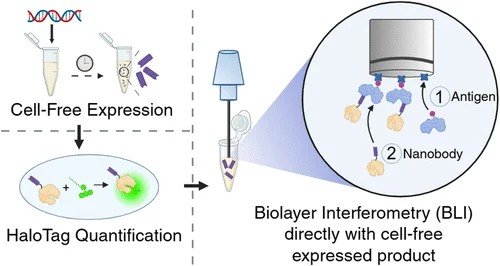
Pleased to share my latest review on Cell-Free Protein Synthesis #CFPS and #AI/ML for accelerating drug discovery
sciencedirect.com/science/articl…
#CellFree #SynBio
English
Filippo Caschera
1.5K posts

@Stjle
Synthetic Biology, Artificial Cells, Amphiphile Systems, Machine Learning, Cell-Free Protein Synthesis: Italy, Denmark, Japan, USA, France, Germany, UK.