Sabitlenmiş Tweet

Lots of people (myself included) have trouble understanding why transformer architectures directly add token embeddings to the position embeddings. It's weird to just directly add the representation of the content - i.e. the token embeddings, with the representation of the content's position within its context. (Note: there are techniques like RoPE that try to get around this, however here I'll deal with the more basic strategy of addition.)
Together with Raneem Mahajne, we trained a small transformer on a simple next-token prediction task. We gave the transformer a sequence of random digits, occasionally interspersed with a + sign. Whenever the + sign appeared, the next number would have to be the same as the *most recent even number*.
For example, if we have the sequence 3 1 2 7 5 +, the next number would have to be a 2.
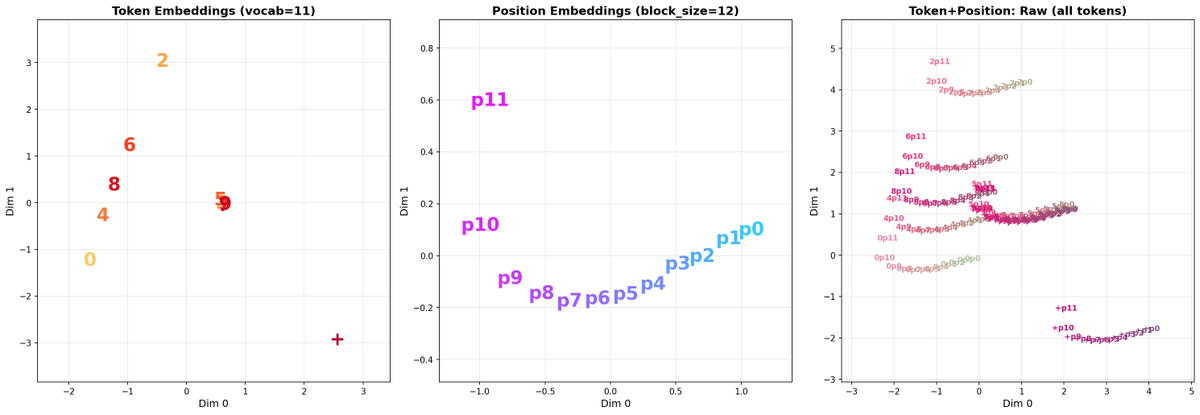
Because we used an embedding dimension of 2 for both the positions and the tokens, we can directly visualize the token embeddings, the position embeddings, and their sum, for every possible token and position combination.
In the token embedding space, the transformer learned to separate out the even numbers from the odd numbers, and it also learned to separate the + sign from everything else. Interestingly, the model also decided to smush all the odd numbers together, while maintaining some space between each even digit, presumably because once a + sign appears, it becomes necessary to predict a specific even number.
In the position embedding space, the transformer learned to correctly order the positions along a curve. Position ordering is important for this task, because in order to know what the "most recent" even number is, you need to have a sense of ordering.
When the token and position information are summed, the structure of *both* the token embedding space and position embedding space are preserved. The even numbers remain separated from each other and the odd numbers, the odd numbers remained smushed together, and the "+" token occupies its own area of space. But now, for each token, we see a local structure based on the curve of ordered positions.
Part of the reason why this occurs is because the magnitudes of the token embeddings are ~10x larger than the magnitudes of the position embeddings, allowing the 'macro' structure to be dominated by the tokens, while the 'micro' structure is determined by the positions.
In other words, summing the position information and token information doesn't just mix things haphazardly, it actually retains the geometric structure of both by using a different scale to encode 'what' and 'where'.
English