
Tom Dwan
5.2K posts


narcissists also seem like obvious candidates for LLM psychosis: high susceptibility to affirmation loops, low tolerance for contradiction, weak reality testing
Steve Stewart-Williams@SteveStuWill
“The single strongest personality predictor [of conspiracy thinking] is narcissism. Narcissists are particularly prone to conspiracy theories because they have a strong need for uniqueness, are prone to paranoia, and can also be remarkably gullible.” stevestewartwilliams.com/p/12-things-ev…
English

CIA scientists concluded that COVID came from a lab leak. Then someone scribbled out their conclusion at 2 am and changed the report.
Tomorrow, a whistleblower testifies before my committee. The COVID cover-up is unraveling.
Daily Wire@realDailyWire
"The carelessness of Anthony Fauci...in all likelihood led to this pandemic that 15 million people died, and still, there hasn't been responsibility." @RandPaul joins @cabot_phillips to discuss new whistleblower testimony surrounding the origins of COVID-19:
English
@polynoamial I feel like you would be one of the best situated people to help come up with better eval criteria…
And I think it’s very important for many aspects of society that there is some more public information around this stuff
English

I love seeing a new eval with such low scores. When we announced GPT-5.5, almost every benchmark had a score above 50%.
It's time to retire evals like GQPA and bring in a new set.
Kilian Lieret@KLieret
The first ProgramBench task was just solved by GPT 5.5 high/xhigh. Interestingly, high/xhigh picked two different languages for the task (C vs Python). GPT 5.5 xhigh was significantly better than Opus 4.7 xhigh in all metrics. 🧵
English
Tom Dwan retweetledi


in honor of 4/20 once I’m done with work I’d love to light up a blunt and stream some heads up NLH against someone. I don’t even know how to stream poker but if someone can help me set it up I’m in.
Who’s game?
English
Tom Dwan retweetledi

Yesterday, we sat down with @TomDwan for our 3rd conversation, and it didn't disappoint.
We covered a lot of ground, but some notable topics included:
• Why did Tom get access to private games that other pros didn't?
• How people in poker can use their skills to excel in other industries?
• The infamous J-4 hand
• The Robl fold
You can watch the recording of the Q&A here:
once.run/TomTalksPoker
English
From @TomDwan's recent Q&A - the story of how Phil Ivey got himself banned from one of the best private games in the world.
English
@polynoamial You guys tell the truth a lot more than Anthropic or XAI seem too.
I don’t have much knowledge about Google/deepmind I’m hopeful they’re closer on that scale to OAI.
We should have both what you suggest, and the public models playing. Along with more options
English
What we really need is a benchmark where AI models make AI models that play poker.
GTOWizard@GTOWizard
We benchmarked every major AI model at poker. GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, Grok 4 and more. All played 5,000 hands of heads-up no-limit against our state-of-the-art poker agent. Every single one lost. Here's the full breakdown 🧵
English
Ahh ok. Im happy to try to help you pressure the frontier labs to play ball.
Some of them claim to be good enough for military targeting and stuff (even though awful mistakes seem to have happened), why not do a proper real test?
GTOWizard@GTOWizard
@TomDwan Great point, Tom. Running frontier LLMs at scale is expensive. That's why we use AIVAT, a variance reduction technique that achieves the same statistical significance in 10x fewer hands, so 5K is equivalent to ~50K raw hands.
English
@GTOWizard Was this an automated response? What about doing more hands instead of the “luck-adjusted” bs hahaha.
It’s still cool regardless obv tho, happy you guys did this
English

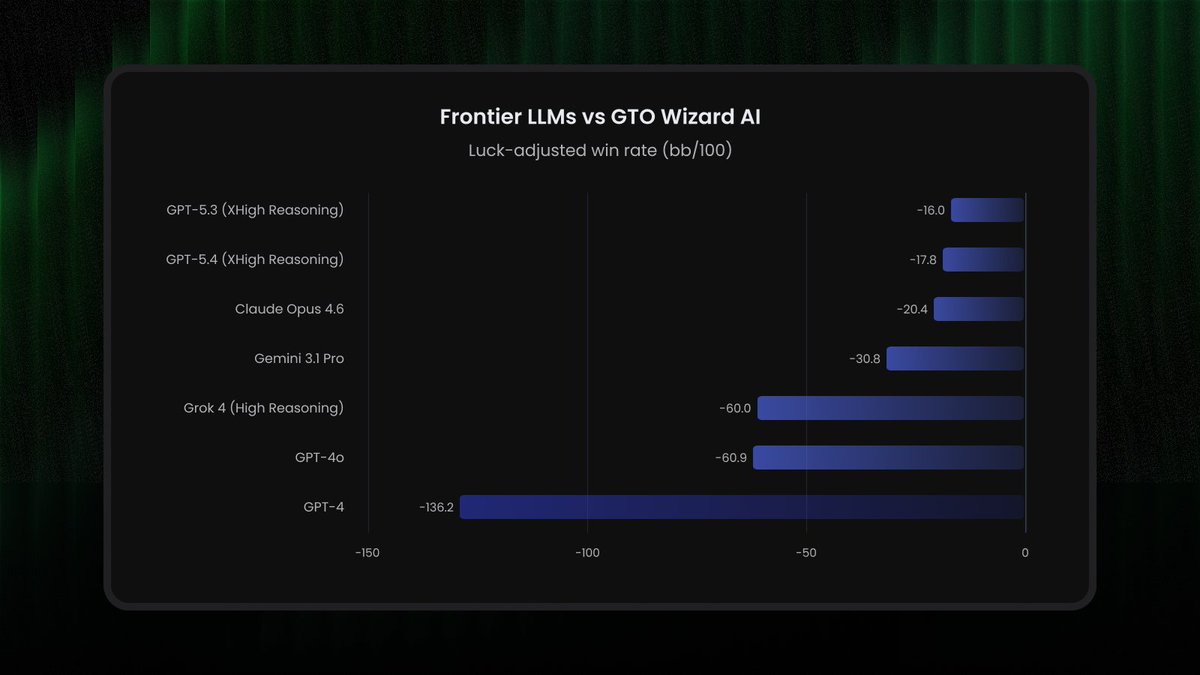
Results (luck-adjusted bb/100):
#1 GPT-5.3 XHigh Reasoning: -16.0
#2 GPT-5.4 XHigh Reasoning: -17.8
#4 Claude Opus 4.6: -20.4
#6 Gemini 3.1 Pro: -30.8
#12 Grok 4 High Reasoning: -60.0
#15 GPT-4: -136.2
A top pro winning at 4 bb/100 is considered elite. The best LLM loses at 4x that rate.
Grok 4 at -60.0 performs nearly the same as a strategy that simply folds every single hand (-64.6).
English

This is cool. 5k obviously not enough hands though, you guys should know that. Can you run a new one with 50-100k hands 🙏🏻🙏🏻
GTOWizard@GTOWizard
We benchmarked every major AI model at poker. GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, Grok 4 and more. All played 5,000 hands of heads-up no-limit against our state-of-the-art poker agent. Every single one lost. Here's the full breakdown 🧵
English
I saw @senortilt teach our drunk friend blackjack once…
Señor Tilt@senortilt
Hey @KylieJenner — I’m Sam Kiki. I hold the record for the most ever won in 17 seasons on High Stakes Poker. I also hold the record for largest single day win. I, too, like splashy pots. I have a seat and $500k with your name on it. Bring @RealChalamet. I’ll teach you both everything the @VanityFair video left out. Then we can all compete on @PokerGO with a few of our mutual friends.
English