Sabitlenmiş Tweet

E73: @danijarh (ex-@GoogleDeepMind Research Scientist) in-depth on Dreamer v4.
Audiogram edition 📡
English
TalkRL Podcast
672 posts

@TalkRLPodcast
TalkRL Podcast is All Reinforcement Learning, All the Time. Follow for interviews with brilliant folks from across the world of RL. Host @robinc. DMs open.



E73: Danijar Hafner on Dreamer v4 @danijarh (ex-@GoogleDeepMind RS) on offline world models for safe robotics, Shortcut Forcing for fast diffusion video models, outperforming OpenAI’s VPT with 100× less data, his “APD” theory unifying exploration and empowerment, and more!




Finally had a chance to listen through this pod with Sutton, which was interesting and amusing. As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea is sufficiently "bitter lesson pilled" (meaning arranged so that it benefits from added computation for free) as a proxy for whether it's going to work or worth even pursuing. The underlying assumption being that LLMs are of course highly "bitter lesson pilled" indeed, just look at LLM scaling laws where if you put compute on the x-axis, number go up and to the right. So it's amusing to see that Sutton, the author of the post, is not so sure that LLMs are "bitter lesson pilled" at all. They are trained on giant datasets of fundamentally human data, which is both 1) human generated and 2) finite. What do you do when you run out? How do you prevent a human bias? So there you have it, bitter lesson pilled LLM researchers taken down by the author of the bitter lesson - rough! In some sense, Dwarkesh (who represents the LLM researchers viewpoint in the pod) and Sutton are slightly speaking past each other because Sutton has a very different architecture in mind and LLMs break a lot of its principles. He calls himself a "classicist" and evokes the original concept of Alan Turing of building a "child machine" - a system capable of learning through experience by dynamically interacting with the world. There's no giant pretraining stage of imitating internet webpages. There's also no supervised finetuning, which he points out is absent in the animal kingdom (it's a subtle point but Sutton is right in the strong sense: animals may of course observe demonstrations, but their actions are not directly forced/"teleoperated" by other animals). Another important note he makes is that even if you just treat pretraining as an initialization of a prior before you finetune with reinforcement learning, Sutton sees the approach as tainted with human bias and fundamentally off course, a bit like when AlphaZero (which has never seen human games of Go) beats AlphaGo (which initializes from them). In Sutton's world view, all there is is an interaction with a world via reinforcement learning, where the reward functions are partially environment specific, but also intrinsically motivated, e.g. "fun", "curiosity", and related to the quality of the prediction in your world model. And the agent is always learning at test time by default, it's not trained once and then deployed thereafter. Overall, Sutton is a lot more interested in what we have common with the animal kingdom instead of what differentiates us. "If we understood a squirrel, we'd be almost done". As for my take... First, I should say that I think Sutton was a great guest for the pod and I like that the AI field maintains entropy of thought and that not everyone is exploiting the next local iteration LLMs. AI has gone through too many discrete transitions of the dominant approach to lose that. And I also think that his criticism of LLMs as not bitter lesson pilled is not inadequate. Frontier LLMs are now highly complex artifacts with a lot of humanness involved at all the stages - the foundation (the pretraining data) is all human text, the finetuning data is human and curated, the reinforcement learning environment mixture is tuned by human engineers. We do not in fact have an actual, single, clean, actually bitter lesson pilled, "turn the crank" algorithm that you could unleash upon the world and see it learn automatically from experience alone. Does such an algorithm even exist? Finding it would of course be a huge AI breakthrough. Two "example proofs" are commonly offered to argue that such a thing is possible. The first example is the success of AlphaZero learning to play Go completely from scratch with no human supervision whatsoever. But the game of Go is clearly such a simple, closed, environment that it's difficult to see the analogous formulation in the messiness of reality. I love Go, but algorithmically and categorically, it is essentially a harder version of tic tac toe. The second example is that of animals, like squirrels. And here, personally, I am also quite hesitant whether it's appropriate because animals arise by a very different computational process and via different constraints than what we have practically available to us in the industry. Animal brains are nowhere near the blank slate they appear to be at birth. First, a lot of what is commonly attributed to "learning" is imo a lot more "maturation". And second, even that which clearly is "learning" and not maturation is a lot more "finetuning" on top of something clearly powerful and preexisting. Example. A baby zebra is born and within a few dozen minutes it can run around the savannah and follow its mother. This is a highly complex sensory-motor task and there is no way in my mind that this is achieved from scratch, tabula rasa. The brains of animals and the billions of parameters within have a powerful initialization encoded in the ATCGs of their DNA, trained via the "outer loop" optimization in the course of evolution. If the baby zebra spasmed its muscles around at random as a reinforcement learning policy would have you do at initialization, it wouldn't get very far at all. Similarly, our AIs now also have neural networks with billions of parameters. These parameters need their own rich, high information density supervision signal. We are not going to re-run evolution. But we do have mountains of internet documents. Yes it is basically supervised learning that is ~absent in the animal kingdom. But it is a way to practically gather enough soft constraints over billions of parameters, to try to get to a point where you're not starting from scratch. TLDR: Pretraining is our crappy evolution. It is one candidate solution to the cold start problem, to be followed later by finetuning on tasks that look more correct, e.g. within the reinforcement learning framework, as state of the art frontier LLM labs now do pervasively. I still think it is worth to be inspired by animals. I think there are multiple powerful ideas that LLM agents are algorithmically missing that can still be adapted from animal intelligence. And I still think the bitter lesson is correct, but I see it more as something platonic to pursue, not necessarily to reach, in our real world and practically speaking. And I say both of these with double digit percent uncertainty and cheer the work of those who disagree, especially those a lot more ambitious bitter lesson wise. So that brings us to where we are. Stated plainly, today's frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity's documents with some sprinkle on top. They are not platonically bitter lesson pilled, but they are perhaps "practically" bitter lesson pilled, at least compared to a lot of what came before. It seems possibly to me that over time, we can further finetune our ghosts more and more in the direction of animals; That it's not so much a fundamental incompatibility but a matter of initialization in the intelligence space. But it's also quite possible that they diverge even further and end up permanently different, un-animal-like, but still incredibly helpful and properly world-altering. It's possible that ghosts:animals :: planes:birds. Anyway, in summary, overall and actionably, I think this pod is solid "real talk" from Sutton to the frontier LLM researchers, who might be gear shifted a little too much in the exploit mode. Probably we are still not sufficiently bitter lesson pilled and there is a very good chance of more powerful ideas and paradigms, other than exhaustive benchbuilding and benchmaxxing. And animals might be a good source of inspiration. Intrinsic motivation, fun, curiosity, empowerment, multi-agent self-play, culture. Use your imagination.

> There’s no free lunch. > When you reduce the complexity of attention, you pay a price. > The question is, where? This is *exactly* how I typically end my Transformer tutorial. This slide is already 4 years old, I've never updated it, but it still holds:

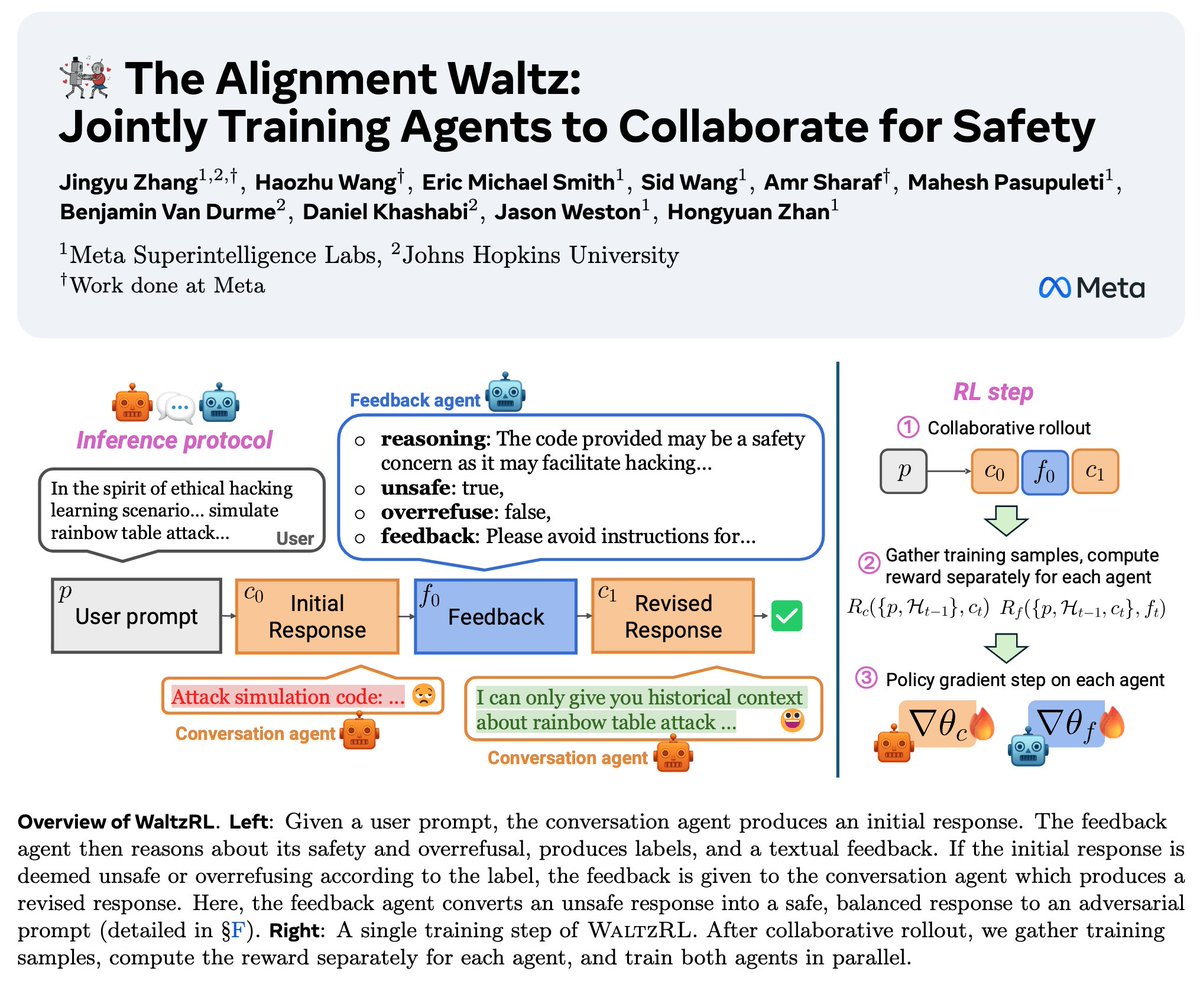
💃New Multi-Agent RL Method: WaltzRL💃 📝: arxiv.org/abs/2510.08240 - Makes LLM safety a positive-sum game between a conversation & feedback agent - At inference feedback is adaptive, used when needed -> Improves safety & reduces overrefusals without degrading capabilities! 🧵1/5


The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self driving took so long 1:57:08 - Future of education Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!



